一种基于轻量化提示微调的目标说话人语音识别方法
- 国知局
- 2024-06-21 11:56:22
本发明涉及深度学习自然语言处理、语音识别,特别涉及一种基于轻量化提示微调的目标说话人语音识别方法。
背景技术:
0、技术背景
1、随着深度学习技术的发展,现有的自动语音识别(automaticspeechrecognition,asr)模型在进行单一说话人语音识别任务时已经达到甚至超越了人类水平,然而一旦将这些模型应用于多说话人重叠语音时,原本性能表现良好的单说话人语音识别模型就不再可用。这是因为单说话人语音识别模型在缺乏先验知识的前提下不清楚要转录多说话人重叠语音中哪个说话人的语句。据统计,重叠语音在会议场景中约占比6%-15%,因此现有的单说话人识别模型存在的问题制约了自动语音识别技术的实际应用。
2、为了处理识别多说话人重叠语音识别这一难题,目标说话人语音识别(targetspeaker asr)作为自动语音识别的一个子任务先后被许多研究者提出并尝试解决。目标说话人语音识别旨在从多说话人重叠语音中转录出需要的目标说话人的发言文本,该过程是通过引入目标说话人的声纹向量作为先验指导模型转录来实现的。
3、尽管现有的研究已经提出了一些有效的目标说话人语音识别方法,但是现有的这些方法仍存在一些缺陷:首先,大部分现有的方法需要全量训练或者微调一个特别设计的专用模型,这意味着大量的冗余参数只为这一个特定的子任务服务,这会造成大量的计算和存储开销的浪费,尤其随着模型的规模越来越大。其次,现有的目标说话人语音识别模型训练或微调时过于依赖人工标注的文本信息,这不但需要比较高的人工标注成本,还会使模型在训练过程中学习到人工标注文本的偏见从而缺少泛化性。因此,在大模型时代,人们的愿景是一个通用的大基座模型可以在几乎不额外增加计算和存储开销的情况下高效地处理多个任务,并且需要开发出更好的基于模型自动标注数据的模型训练方法。
技术实现思路
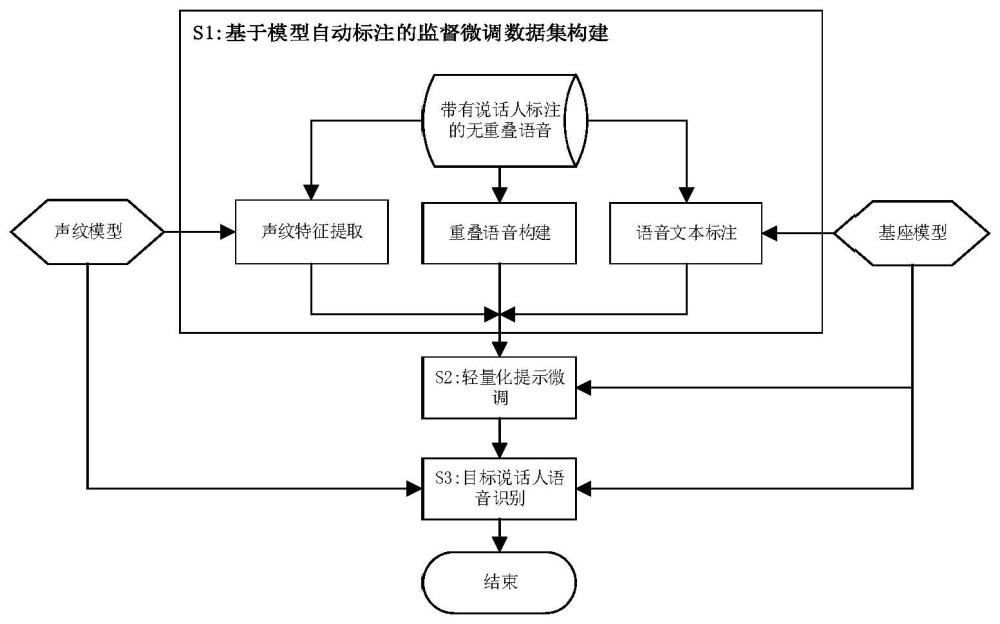
1、为了解决上述现有技术中存在问题,本发明提出了一种基于轻量化提示微调(prompt tuning,pt)的目标说话人语音识别方法,该方法可以高效地将单说话人语音识别大模型,即基座模型适配到多说话人重叠语音中的目标说话人语音识别任务上。在方法的监督微调数据集构建步骤中,为解决传统方法构建监督微调数据集过于依赖人工标注的问题,本发明提供了一种基于模型自动标注的监督微调数据集构建方法。
2、本发明采用的技术方案如下:
3、一种基于轻量化提示微调的目标说话人语音识别方法,该方法首先基于模型自动标注进行监督微调数据集的构建,解决了传统方法过于依赖人工标注的问题,并有助于提高微调后的模型的泛化性能;之后使用构建好的数据集进行目标说话人语音识别模型的轻量化提示微调,将只能适用于单说话人非重叠语音的基座模型简洁高效地适配到多说话人重叠语音中的目标说话人语音识别任务上,具体步骤包括:
4、步骤1:基于模型自动标注的监督微调数据集构建,准备大量仅带有说话人标注的无重叠语音,使用声纹识别模型对所有不同说话人提取声纹特征并保存;使用基座模型对这些语音进行识别,生成标注文本并保存;选取n条来自不同说话人的无重叠语音,n≥2,以服从特定分布的信噪比构建重叠语音并保存,构建多条重叠语音—声纹特征—标注文本数据对作为监督微调数据集;
5、步骤2:目标说话人语音识别模型的轻量化提示微调,使用步骤1构建的数据集,通过在基座模型输入的重叠语音特征向量组的前部附加上1个目标说话人声纹特征向量、随机初始化的n个软提示向量,对基座模型进行轻量化监督微调,其中声纹特征向量应经过矩阵投影变换以保证其在形状和语义方面与软提示向量一致,微调过程中仅更新声纹特征投影矩阵及附加的软提示向量的参数,在微调完成后存储投影矩阵和软提示向量。
6、步骤3:目标说话人语音识别,当基座模型的输入语音为包含目标说话人的多说话人重叠语音时,在该语音特征向量组前部附加上1个的目标说话人声纹向量和n个步骤2中训练并保存的提示向量,其中目标说话人声纹向量应使用步骤1中同样的声纹模型提取得到,并使用步骤2保存的投影矩阵进行投影变换。此时基座模型可以自动在多说话人重叠语音中转录出目标说话人的发言文本。
7、优选的,所述步骤1中,多条无重叠语音构建重叠语音时应保证较短的语音通过后补0操作填充到与最长的语音等长以保证构建的重叠语音不丢失信息;所述信噪比服从均值为0标准差为4.1db的正态分布。
8、优选的,所述步骤2中,基座模型为基于编码器和解码器结构的多层transformer模型,所述的目标说话人语音识别模型的轻量化提示微调方法应包含:输入提示微调,在输入层特征向量组前部附加n个提示向量;深度提示,使用新的可训练提示向量替换中间层输入特征向量组前的n个向量;重参数化,使用前馈网络重参数化软提示向量,所述前馈网络为一个深度为2并包含跳跃连接的多层感知机,输入到每一层的软提示向量组的重参数化前馈网络参数共享,不同层的软提示向量组的重参数化前馈网络参数不共享。
9、本发明的有益效果是:使用步骤1中基于模型自动标注的监督微调数据集构建方法,既可以节约人工标注成本又能防止微调后的模型过拟合人工标注的偏见,从而提升微调后模型的泛化能力;通过步骤2中目标说话人语音识别模型的轻量化提示微调,可以将只能适用于非重叠语音的基座语音识别模型简洁高效地适配到多说话人重叠语音中的目标说话人语音识别任务上,相较于传统的基于全量训练或者微调一个专用的目标说话人语音识别模型的方法,使用本发明提供的方法仅需训练并存储非常少量的参数,从而可以在保持了较高性能的前提下大大节省训练和存储开销。
技术特征:1.一种基于轻量化提示微调的目标说话人语音识别方法,可以高效地将只能适用于非重叠语音的语音识别模型,即基座模型简洁高效地适配到多说话人重叠语音目标说话人语音识别任务上,具体步骤包括:
2.根据权利要求1所述的基于轻量化提示微调的目标说话人语音识别方法,其特征是:在步骤1基于模型自动标注的监督微调数据集构建中,多条无重叠语音构建重叠语音时应保证较短的语音通过后补0操作填充到与最长的语音等长以保证构建的重叠语音不丢失信息;所述信噪比服从均值为0标准差为4.1db的正态分布。
3.根据权利要求1所述的基于轻量化提示微调的目标说话人语音识别方法,其特征是:在步骤2目标说话人语音识别模型的轻量化提示微调中,基座模型为基于编码器和解码器结构的多层transformer模型,所述的目标说话人语音识别模型的轻量化提示微调方法应包含:输入提示微调,在输入层特征向量组前部附加n个提示向量;深度提示,使用新的可训练提示向量替换中间层输入特征向量组前的n个向量;重参数化,使用前馈网络重参数化软提示向量,所述前馈网络为一个深度为2并包含跳跃连接的多层感知机,输入到每一层的软提示向量组的重参数化前馈网络参数共享,不同层的软提示向量组的重参数化前馈网络参数不共享。
技术总结本发明公开了一种基于轻量化提示微调的目标说话人语音识别方法,可以将只能适用于单说话人非重叠语音的基座语音识别大模型简洁高效地适配到多说话人重叠语音中的目标说话人语音识别任务上。为解决传统方法监督训练或微调过程过于依赖人工标注数据的问题,本发明在监督微调数据集构建步骤中提供了一种基于模型自动标注的监督微调数据集构建方法。使用模型自动标注的文本数据进行轻量化提示微调,既节约了人工标注成本又能使微调后的模型不受人工标注的数据偏见影响,从而微调后的模型更具泛化性。技术研发人员:刘琚,马豪,邵明杰,李静,彭志远受保护的技术使用者:山东大学技术研发日:技术公布日:2024/6/5本文地址:https://www.jishuxx.com/zhuanli/20240618/24596.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。