一种基于模型指纹的音频主动归因方法
- 国知局
- 2024-06-21 11:56:32
本发明涉及一种基于模型指纹的音频主动归因取证方法,属于音频处理和数字取证领域。
背景技术:
1、音频生成技术已经能够产生高度逼真的语音、音乐和其他声音。这些模型通过学习复杂的音频数据分布,能够创造出几乎听不出真假的音频。逼真的音频生成带来了一系列风险,包括制作虚假的语音记录,例如仿造公众人物的声音,以及在不具备授权的情况下制作音乐作品。鉴于这些风险,对音频内容的来源进行归因和验证变得非常重要。
2、目前国内外对于音频归因的方法分为主动归因方法和被动归因方法。主动归因方法:音频生成模型在训练期间被嵌入一个特定的指纹或水印。这使得生成的音频包含一些可追踪和验证的特征,有助于识别和确认音频的真实来源。被动归因方法:被动归因方法不依赖于对生成模型的预处理。它通过分析生成的音频来寻找模型留下的特有痕迹或模式。这要求使用高级的音频分析技术,以识别特定生成模型的特征。对音频的归因和验证不仅是一个技术挑战,也涉及伦理和法律问题。确保技术的使用不损害个人隐私、版权和社会安全是非常重要的。总的来说,目前音频归因技术还处于发展阶段,与图像和视频处理领域相比,音频取证和归因方法的研究相对欠缺,现有的归因技术还不够成熟完善。
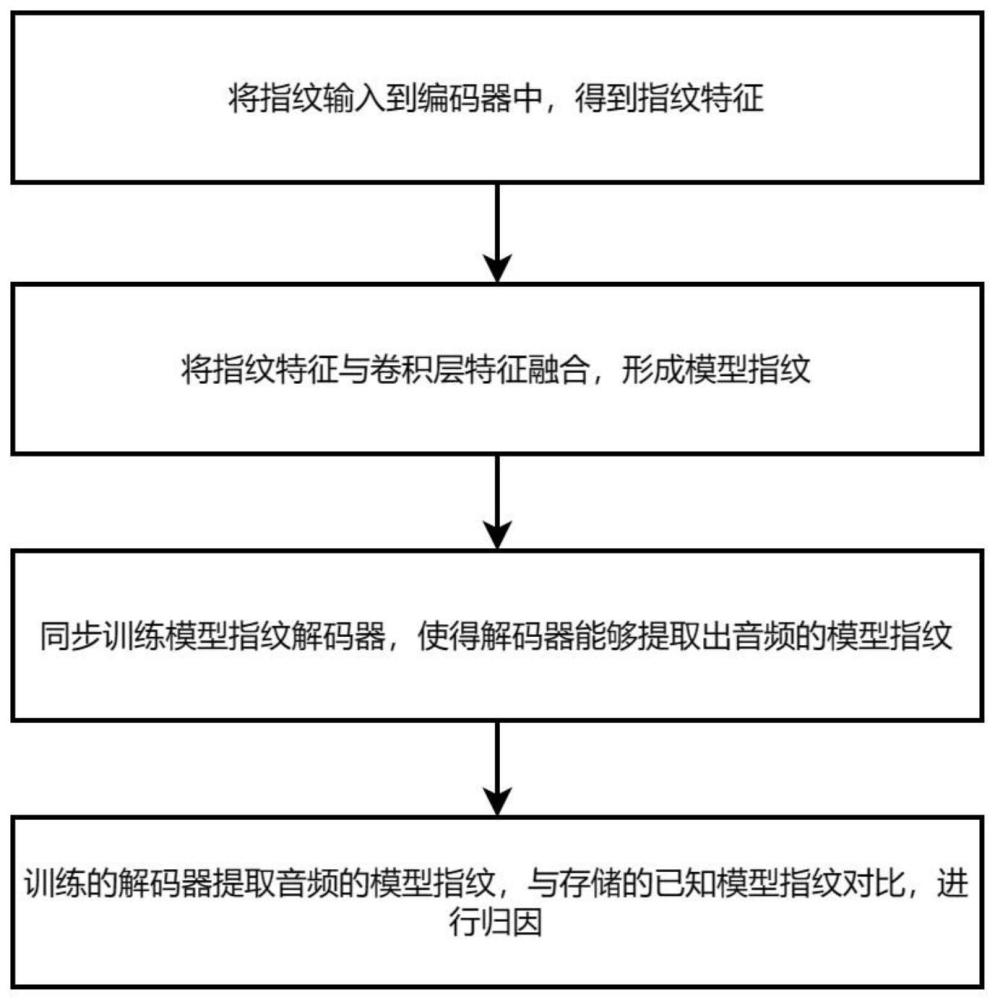
技术实现思路
1、基于上述问题,本发明的目的是提供一种对于生成音频的主动归因方法。为达到上述目的,本发明提出了一种基于模型指纹的音频主动归因方法,该方法将指纹特征与模型相结合形成独特的模型指纹,使得生成的音频中带有该模型指纹,实现对于音频的主动归因。
2、为了达到上述技术目的,具体技术方案如下所示:
3、一种基于模型指纹的音频主动归因方法,该方法包括以下步骤:
4、s1:模型指纹嵌入:训练带有模型指纹的音频生成模型,并同步训练模型指纹解码器;
5、s2:音频归因:将提取出的音频的模型指纹与存储的已知模型指纹对比,如果相同,则认为是已知模型生成的;否则,则认为不是已知模型生成的。
6、进一步,步骤s1具体包括以下步骤:
7、s11:将随机生成的指纹输入到编码器中,得到指纹特征;
8、s12:指纹特征与生成器中每一层的卷积层特征进行融合形成模型指纹,特征融合的数学表达式如下:
9、z'=cα⊙z+cβ
10、式中,z为卷积层特征,cα和cβ为指纹特征经过全连接层后得到的两个输出,z'为融合后的模型指纹;
11、s13:将生成的音频输入到一同训练的解码器中进行指纹提取,得到其模型指纹;
12、s14:计算解码器提取的模型指纹与嵌入的模型指纹之间的相关损失来指导生成器和解码器的训练;
13、s15:重复以上步骤来优化模型参数,使训练出来的音频模型能够使生成的音频中带有模型指纹,且解码器能够解码出待归因音频中的模型指纹。
14、进一步,步骤s2具体包括以下步骤:
15、s21:将待归因的音频输入到由步骤s1训练的解码器中,提取出音频中的模型指纹;
16、s22:将提取出的模型指纹和已知的模型指纹进行比较,进行归因。如果相同,则认为是已知模型生成的;否则,则认为不是已知模型生成的。
17、本发明的优点及有益效果如下:
18、与现有的音频归因方法相比,本发明提供的采取主动添加模型指纹的方法提升了方法的灵活性和可扩展性。该方法通过将指纹嵌入深度学习网络的参数中,而非直接嵌入到生成的音频样本里,无需对音频数据进行预处理,且有效地保留了音频输出的原始质量和效用。这种做法不仅提高了指纹的隐蔽性和安全性,还提升了技术的适用性和灵活性,使其能更好地抵抗外部攻击。与依赖特定输入触发的指纹方法相比,本发明通过将指纹嵌入网络参数中的策略,避免了对特定输入的依赖,提高了技术的泛用性。采用指纹特征与卷积层特征融合的方法能够有效地将模型指纹集成到生成的音频中,并且一同训练的解码器也能高效地提取音频中的指纹信息。该方法不仅使得模型拥有者能够对其模型进行指纹识别,还能准确地检测并归因包含指纹的音频,从而确保音频生成模型的分发和使用过程更加透明。
技术特征:1.一种基于模型指纹的音频主动归因方法,其特征在于,该方法具体包括以下步骤:
2.根据权利要求1所述的一种基于模型指纹的音频主动归因方法,其特征在于,训练了带有模型指纹的生成器和解码器。步骤s1具体包括以下步骤:
3.根据权利要求1所述的一种基于模型指纹的音频主动归因方法,其特征在于,步骤s2具体包括以下步骤:
技术总结本发明涉及一种基于模型指纹的音频主动归因取证方法,属于音频处理和数字取证领域。该方法包括两个主要阶段:模型指纹嵌入阶段和音频归因阶段。模型指纹嵌入阶段:为音频生成模型添加模型指纹,并同步训练模型指纹解码器,通过解码器提取出音频的模型指纹;音频归因阶段:将提取出的音频的模型指纹与存储的模型指纹对比,如果相同,则认为是已知模型生成的;否则,则认为不是已知模型生成的。本发明方法无需对音频样本进行操作,直接通过添加模型指纹的方法使得生成音频中带有模型指纹,进行音频主动归因。本发明不仅能够让模型拥有者对模型进行指纹识别,而且可以准确地检测到包含指纹的音频并归因,确保了音频生成模型的分发和使用更加透明。技术研发人员:陈龙,周彦秀,董振兴,陈自刚受保护的技术使用者:重庆邮电大学技术研发日:技术公布日:2024/6/5本文地址:https://www.jishuxx.com/zhuanli/20240618/24621.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表