一种针对语音对抗攻击的语音自然度评估方法
- 国知局
- 2024-06-21 11:57:08
本发明属于智能语音系统中的语音识别模型安全,具体涉及一种针对语音对抗攻击的语音自然度评估方法。
背景技术:
1、语音识别技术可以将语音转换成文本,目前已广泛应用于智能手机、汽车、工业控制终端等设备,能够实现语音控制、语音转录、语音搜索等功能。现有研究表明,语音识别技术受到对抗攻击的威胁。在对抗攻击中,攻击者将恶意构造的对抗噪声叠加人类语音形成对抗样本,诱使语音识别模型输出错误的文本。在语音控制场景下,此类攻击会导致智能手机、摄像头、家电、车辆等设备发生恶意操作,威胁各类语音识别应用的安全运行。
2、现有研究一般通过求解优化问题来生成对抗样本,在此优化问题中优化目标是音频加上扰动会被模型识别为目标文本且扰动对于人类来说具有较低的可听性。用数学公式来表达时,优化目标式是最小化对抗样本的模型识别结果与目标文本之间的距离和扰动的可听性指标的加权和。为提高攻击的隐蔽性、增加对抗样本的自然性,现有研究针对扰动的可听性指标进行了优化,先后提出了分贝失真、绝对听觉阈值、心理声学听觉掩映等多种方案,在不同方案下生成的扰动具有不同的信号形态,同时也具有不同的自然度。
3、分贝失真使用扰动和原始音频之间的强度比来表示扰动的可听性,通过将原始音频和扰动之间的信噪比固定在一个较大值来防止对抗噪声强度过大被人类发觉。使用分贝失真作为可听性指标时生成的对抗扰动在信号形态和听觉效果上都类似于白噪声,与正常的人类语音有较大的差别。这使得生成的对抗样本自然度较差,容易被人类分辨。与之相对的是心理声学听觉掩映方案,此方案利用了心理声学的理论,即对于人类听觉来说,高能量声音能掩盖和它相似频率和时间点的低能量声音。以此为可听性指标生成的扰动在时频域上的能量分布与原始音频类似,因此扰动听起来像人类的低语声,因此此类对抗样本自然度较好,攻击的隐蔽性好,难以被人类发现,但它仍保留了部分对抗特性。另外,绝对听觉阈值等其他可听性指标下生成的对抗样本性能在上述两者之间。
4、现有研究未对对抗音频的自然度进行具体的描述和分析,但他们通过训练分类器的方式区分语音对抗样本与良性语音之间在信号形态上的差异,并对两者进行区分。相关工作包括:
5、samizade s等人在2020年的《proceedings of the ieee internationalconference on acoustics,speech and signal processing(icassp)》上发表的《adversarial example detection by classification for deep speech recognition》利用倒频谱作为输入特征,小核卷积神经网络作为分类器,检测对抗音频中的对抗噪声,实现了针对一种白盒对抗样本和一种关键词识别黑盒对抗样本的检测。
6、carlini n等人在2016年的《proceedings of the usenix security symposium》上发表的《hidden voice commands》利用短时时频域特征的均值和标准差作为输入,逻辑回归模型作为分类器,构造了一个对抗样本的检测器,可以检测出基于梅尔倒频谱-拟倒频谱方法生成的语音对抗样本。
7、马健等人在2022年的《东莞理工学院学报》上发表的《基于多频谱特征的音频对抗样本检测方法》利用对抗样本的时域特征和频域特征作为输入,针对多个频谱的特征训练卷积神经网络作为分类器,实现了针对一种白盒对抗样本和一种黑盒对抗样本的检测。
8、上述工作利用分类器对对抗样本和良性语音进行区分,但所提出的方法未分析和利用语音对抗样本的不自然性这一本质特点。
技术实现思路
1、对于上述存在的问题,本发明针对语音识别模型的对抗攻击,提出了一种针对语音对抗攻击的语音自然度评估方法。首先提出了对抗样本的五类不自然性,并针对每一种不自然性提出了若干个声学-统计特征用于描述此类不自然性。接着基于上述声学-统计特征,设计了自然度指标,用于对语音样本的自然度进行评估,可以量化测试语音与人类正常语音之间的相似度。
2、本发明是通过以下技术方案得以实现的:
3、一种针对语音对抗攻击的语音自然度评估方法,包括以下步骤:
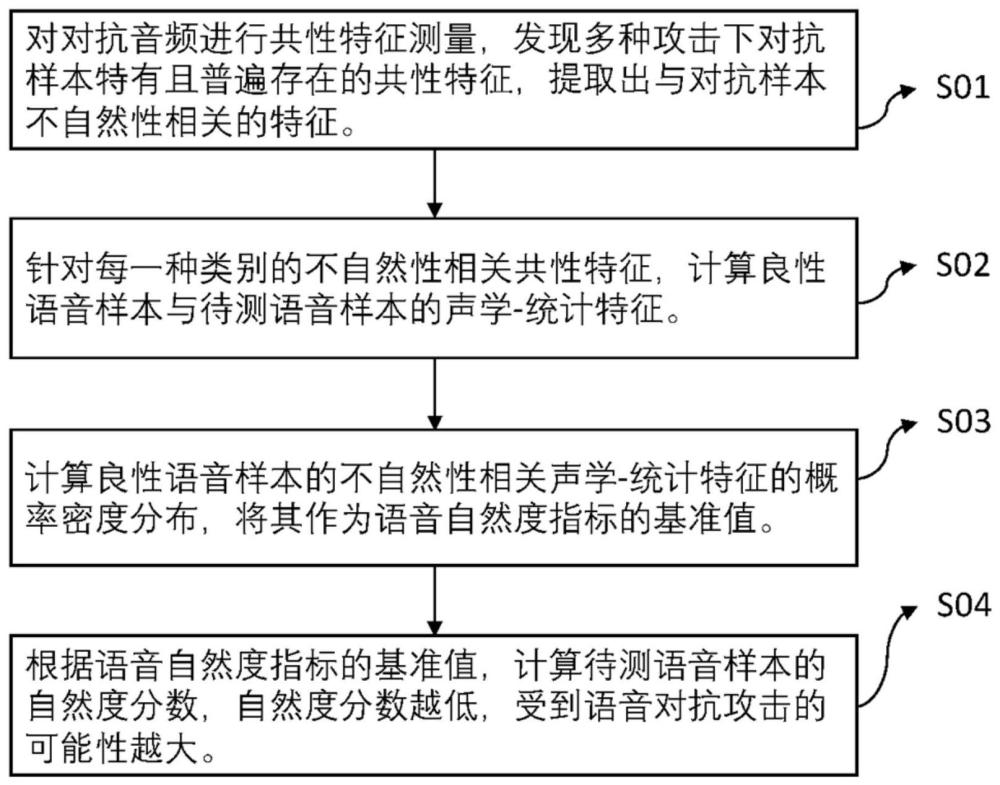
4、步骤s01,获取对抗音频共性特征并筛选得到与不自然性相关的共性特征,所述的与不自然性相关的共性特征包括五种类型,分别为时域信号不连续、频域信号不连续、时域信号不规律、频域信号不规律、语音模式异常;
5、步骤s02,针对每一种类别的不自然性相关共性特征,计算良性语音样本与待测语音样本的不自然性相关声学-统计特征;
6、步骤s03,根据良性语音样本的不自然性相关声学-统计特征设计语音自然度指标,所述语音自然度指标的基准值为良性语音样本的不自然性相关声学-统计特征的概率密度分布;
7、步骤s04,根据语音自然度指标的基准值,计算待测语音样本的自然度分数,自然度分数越低,受到语音对抗攻击的可能性越大。
8、进一步地,所述时域信号不连续对应的不自然性相关声学-统计特征包括频谱图中峰的差值、频谱包络中共振峰的差值、线性预测编码的余弦距离、线性预测编码的欧式距离。
9、进一步地,所述频域信号不连续对应的不自然性相关声学-统计特征包括频谱图中峰的高度、频谱图中峰的宽度、频谱图中峰的峰度、频谱包络中共振峰高度、频谱包络中共振峰宽度、频谱包络中共振峰峰度、频谱包络中共振峰数量。
10、进一步地,所述时域信号不规律对应的不自然性相关声学-统计特征包括线性预测编码的长度、线性预测编码的自相关性、线性预测编码的过零率、线性预测编码的周期、线性预测编码的过零点距离。
11、进一步地,所述频域信号不规律对应的不自然性相关声学-统计特征包括频谱图中峰的自相关率、频谱图中频谱幅值的自相关率、频谱图中频谱幅值的过零率、频谱图中峰的周期、频谱图中频谱幅值的周期、频谱图中频谱幅值的过零点距离。
12、进一步地,所述语音模式异常对应的不自然性相关声学-统计特征包括音素的持续时间、字符的间隔时间。
13、进一步地,所述的语音自然度指标的基准值表示为:
14、
15、其中,px是良性语音样本的不自然性相关声学-统计特征的概率密度分布;是良性语音样本中第j个声学-统计特征的概率密度函数,概率密度函数从良性语音样本声学-统计特征归一化后的统计量集合中计算获得,m是声学-统计特征的数量,x是良性语音样本集合,xi是第i个良性语音样本,dj是第j个声学-统计特征,是语音样本第j个声学-统计特征dj归一化后的统计量。
16、进一步地,所述的待测语音样本的自然度分数的计算公式为:
17、
18、其中,n是自然度分数;将待测语音样本x′的不自然性相关声学-统计特征归一化后的统计量输入良性语音样本的各个声学-统计特征的概率密度函数中,将声学-统计特征的概率密度函数的输出结果之和作为自然度分数。
19、本发明具有以下有益效果:
20、(1)本发明通过测量多种攻击下对抗音频的共性特征,根据这些共性特征的产生原因和与对抗攻击原理之间的联系,提出了与对抗样本不自然性相关的特征,总结为时域信号不连续、频域信号不连续、时域信号不规律、频域信号不规律、语音模式异常五类。本发明利用基于对抗样本的不自然性提出了在多种攻击下均存在的对抗样本的固有属性,弥补了现有研究在语音对抗样本本质特点探究方面的缺失,有助于对抗样本的检测与防御。
21、(2)本发明设计了用于描述语音不自然性的声学-统计特征,并基于此提出了一种语音自然度指标,实现了对语音对抗样本固有属性进行量化表征。通过计算测试语音样本在上述声学-统计特征上符合良性音频分布的概率,作为语音自然度指标。本发明提出的语音自然度指标可以评价任意语音样本与良性语音之间的相似度,在无法使用机器学习模型场景下,轻便快捷地计算某一音频样本的自然度分值,可进一步根据自然度分值得到该音频样本是对抗样本的可能性,实现语音对抗攻击的初步检测。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24682.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表