一种语音分割方法、装置、计算机设备及介质与流程
- 国知局
- 2024-06-21 11:57:29
本发明涉及计算机,具体涉及一种语音分割方法、装置、计算机设备及介质。
背景技术:
1、自动会议纪要是当前会议一体机产品的关键功能之一,其核心功能是解决谁在什么时间说了什么,即提取每个参会人员的语音内容。而区分不同人的语音,即把多人语音分割出来,是整个会议一体机产品的核心功能之一。
2、当前技术上,通常采用声纹的方法,即通过声纹模型提取每个小的时间片的声纹向量,如i-vector或者基于深度学习模型提取的d-vector等,而后通过聚类,把所有小片段进行归并,完成说话人分割。也有基于方位的分割方法,即把空间按照角度分辨率切割成多份,再计算各个语音片段的方位,把对应方位语音片段打上事先做好的分割类别标签,完成说话人分割。
3、基于声纹的方法通常将语音切成小片段,如1~2秒,能够抽取的声纹信息十分有限,从而导致聚类通常并不那么准确。而基于方位的方法,通常方位区分度并不那么高,造成邻近的人很容易被判为同一人,加上空间分割势必产生“边界”问题,比如一个空间为[-30°,30°],如果说话人恰好在30°,那么有些语音判为该区间,一部分语音则判为相邻区间,所以单纯基于方位的方法也不理想。而结合方位和声纹是一个好的想法,但由于两类系统差异较大,目前还没有看到比较好的方法。
技术实现思路
1、有鉴于此,本发明提供了一种语音分割方法、装置、计算机设备及介质,以解决方位和声纹融合的问题。
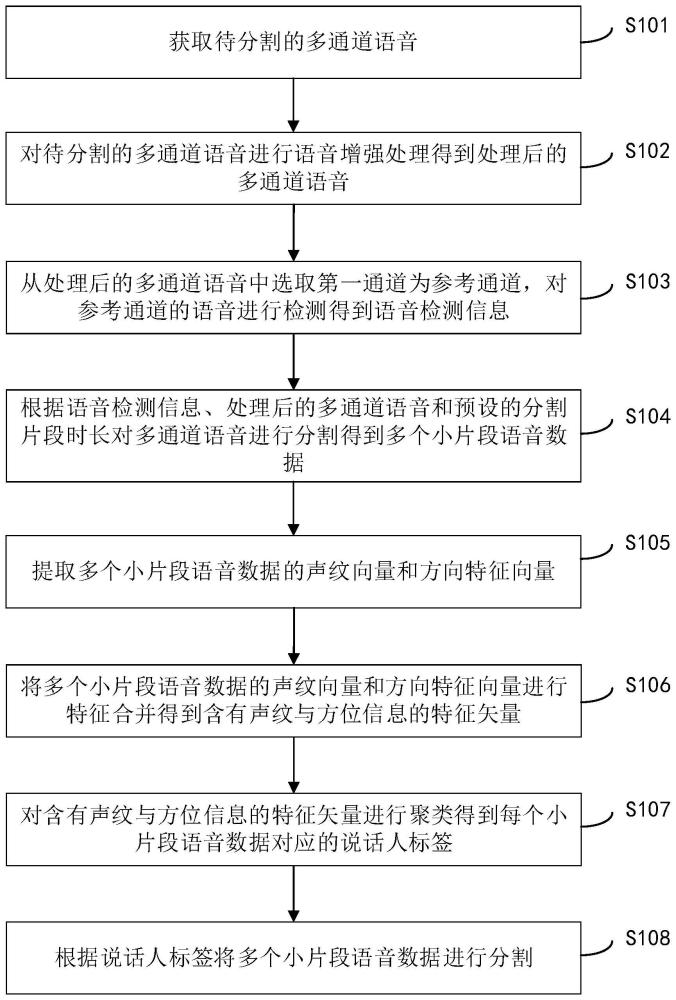
2、第一方面,本发明提供了一种语音分割方法,该方法包括:
3、获取待分割的多通道语音;
4、对待分割的多通道语音进行语音增强处理得到处理后的多通道语音;
5、从处理后的多通道语音中选取第一通道为参考通道,对参考通道的语音进行检测得到语音检测信息;
6、根据语音检测信息、处理后的多通道语音和预设的分割片段时长对所述多通道语音进行分割得到多个小片段语音数据;
7、提取多个小片段语音数据的声纹向量和方向特征向量;
8、将多个小片段语音数据的声纹向量和方向特征向量进行特征合并得到含有声纹与方位信息的特征矢量;
9、对含有声纹与方位信息的特征矢量进行聚类得到每个小片段语音数据对应的说话人标签;
10、根据说话人标签将多个小片段语音数据进行分割。
11、本发明提供的一种语音分割方法,具有如下优点:提取了方向特征向量和声纹向量,将声纹向量和方向特征向量进行特征合并得到含有声纹与方位信息的特征矢量,特征矢量较好的融合了声纹与方位信息,相比单纯的声纹特征增加了特征间的区分性,又规避了单独使用方位信息存在的问题,不仅分割性能得到明显提高,且这种方法易于集成到现有任何基于聚类的声纹分割系统和基于端到端的神经网络分割系统。
12、在一种可选的实施方式中,对待分割的多通道语音进行语音增强处理得到处理后的多通道语音,包括:
13、采用多通道混响抑制算法mclp对所述待分割的多通道语音进行去除混响处理得到去除混响的多通道语音;
14、将去除混响的多通道语音中每个通道的语音通过语音降噪模块进行去噪处理得到处理后的多通道语音。
15、在一种可选的实施方式中,对所述参考通道的语音进行检测得到语音检测信息,包括:
16、将参考通道的语音输入语音检测模块进行检测得到语音时间起止点信息。
17、在一种可选的实施方式中,根据语音检测信息、处理后的多通道语音和预设的分割片段时长对多通道语音进行分割得到多个小片段语音数据,包括:
18、将语音检测信息、处理后的多通道语音和预设的分割片段时长输入语音分割模块将多通道语音进行分割得到多个小片段语音数据。
19、在一种可选的实施方式中,提取多个小片段语音数据的声纹向量和方向特征向量,包括:
20、从多个小片段中抽取一路参考通道,通过声纹特征模块提取声纹向量;
21、通过srp-phat算法提取多个小片段语音数据每一帧信号的的srp-phat谱,所有帧的srp-phat谱取平均,再归一化构成方向特征向量;或,通过子空间的方法提取方向特征向量。
22、在一种可选的实施方式中,对含有声纹与方位信息的特征矢量进行聚类得到每个小片段语音数据对应的说话人标签,包括:
23、采用自底向上的聚类方式,不断合并距离最近的特征片段,并与设定阈值进行比较,直到特征间距离大于设定阈值停止聚类;
24、其中,聚类结果中类别数为估计说话人数,每个语音片段均有其对应的说话人标签。
25、在一种可选的实施方式中,根据所述说话人标签将所述多个小片段语音数据进行分割,包括:
26、通过说话人标签将所述多个小片段语音数据按照时间先后顺序进行分割。第二方面,
27、本发明提供了一种语音分割装置,所述装置包括:
28、获取模块:用于获取待分割的多通道语音;
29、语音增强处理模块:用于对待分割的多通道语音进行语音增强处理得到处理后的多通道语音;
30、检测模块:用于从处理后的多通道语音中选取第一通道为参考通道,对参考通道的语音进行检测得到语音检测信息;
31、第一分割模块:用于根据语音检测信息、处理后的多通道语音和预设的分割片段时长对多通道语音进行分割得到多个小片段语音数据;
32、提取模块:用于提取多个小片段语音数据的声纹向量和方向特征向量;
33、特征合并模块:用于将多个小片段语音数据的声纹向量和方向特征向量进行特征合并得到含有声纹与方位信息的特征矢量;
34、聚类模块:用于对含有声纹与方位信息的特征矢量进行聚类得到每个小片段语音数据对应的说话人标签;
35、第二分割模块:用于根据说话人标签将所述多个小片段语音数据进行分割。
36、本发明提供的一种语音分割装置,具有如下优点:通过提取模块提取了方向特征向量和声纹向量,通过特征合并模块将声纹向量和方向特征向量进行特征合并得到含有声纹与方位信息的特征矢量,特征矢量较好的融合了声纹与方位信息,相比单纯的声纹特征增加了特征间的区分性,又规避了单独使用方位信息存在的问题,不仅分割性能得到明显提高,且这种装置易于集成到现有任何基于聚类的声纹分割系统和基于端到端的神经网络分割系统。
37、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的一种语音分割方法。
38、第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的一种语音分割方法。
技术特征:1.一种语音分割方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述待分割的多通道语音进行语音增强处理得到处理后的多通道语音,包括:
3.根据权利要求1所述的方法,其特征在于,所述对所述参考通道的语音进行检测得到语音检测信息,包括:
4.根据权利要求1所述的方法,其特征在于,所述根据所述语音检测信息、所述处理后的多通道语音和预设的分割片段时长对所述多通道语音进行分割得到多个小片段语音数据,包括:
5.根据权利要求1所述的方法,其特征在于,所述提取所述多个小片段语音数据的声纹向量和方向特征向量,包括:
6.根据权利要求1所述的方法,其特征在于,所述对所述含有声纹与方位信息的特征矢量进行聚类得到每个小片段语音数据对应的说话人标签,包括:
7.根据权利要求1所述的方法,其特征在于,所述根据所述说话人标签将所述多个小片段语音数据进行分割,包括:
8.一种语音分割装置,其特征在于,所述装置包括:
9.一种计算机设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机指令,所述计算机指令用于使计算机执行权利要求1至7中任一项所述的一种语音分割方法。
技术总结本发明涉及计算机技术领域,公开了一种语音分割方法、装置、计算机设备及介质,该方法包括:获取待分割的多通道语音;对待分割的多通道语音进行语音增强处理;从语音增强处理后的多通道语音中选取参考通道,对参考通道的语音进行检测得到语音检测信息;根据语音检测信息、处理后的多通道语音和预设的分割片段时长对多通道语音进行分割得到多个小片段语音数据;提取声纹向量和方向特征向量;将声纹向量和方向特征向量进行特征合并得到特征矢量;对特征矢量进行聚类得到每个小片段语音数据对应的说话人标签;根据说话人标签将多个小片段语音数据进行分割。本发明通过将声纹向量和方向特征向量进行特征合并得到特征矢量,提高了语音的分割性能。技术研发人员:关海欣,谭小彬,梁家恩受保护的技术使用者:云知声智能科技股份有限公司技术研发日:技术公布日:2024/6/11本文地址:https://www.jishuxx.com/zhuanli/20240618/24721.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。