基于RNN-T的全球英语模型的训练数据序列的制作方法
- 国知局
- 2024-06-21 11:58:27
背景技术:
1、本发明总体上涉及机器学习,并且更具体地涉及用于组成基于递归神经网络换能器(rnn-t)的全球英语模型的有效训练数据序列的方法和系统。
2、近年来,用于自动语音识别(asr)的端到端模型作为一种将常规asr系统的独立组件(例如,声学、发音和语言模型)折叠成单个神经网络的方式已经变得流行。此类模型的示例包括基于连接机制时间分类(ctc)的模型、递归神经网络换能器(rnn-t)、以及基于注意力的seq2seq模型。在这些模型中,rnn-t是最适合的流端到端识别器,其与常规系统相比已经显示出竞争性能。
3、在探究rnn-t之前,语音识别继续演进以满足移动环境的不受束缚且灵活的需求。继续开发新的语音识别架构或对现有架构的改进,其寻求提高asr系统的质量。为了说明,语音识别最初采用多个模型,其中每个模型具有专用目的。例如,asr系统包括声学模型(am)、发音模型(pm)和语言模型(lm)。声学模型将音频的片段(例如,音频的帧)映射到音素。发音模型将这些音素连接在一起以形成单词,而语言模型用于表示给定短语的似然性(例如,单词序列的概率)。然而,尽管这些单独的模型一起工作,但每个模型被独立地训练并且经常在不同数据集上手动地设计。
4、独立模型的方法使得语音识别系统能够相当准确,尤其是当给定模型的训练语料库(例如,训练数据体)迎合模型的有效性时,但是需要独立地训练独立模型引入其自身的复杂性并且导致具有集成模型的架构。这些集成模型试图使用单个神经网络将音频波形(例如,输入序列)直接映射到输出句子(例如,输出序列)。这导致序列到序列方法,其在给定音频特征序列时生成单词(或字素)序列。序列到序列模型的示例包括“基于注意力”模型和“监听-参加-拼写(listen-attend-spell)”(las)模型。las模型使用监听器组件、参加器组件和拼写器组件将语音话语转录成字符。这里,监听器是递归神经网络(rnn)编码器,其接收音频输入(例如,语音输入的时间-频率表示)并将音频输入映射到更高级别的特征表示。参加器参加更高级别的特征以学习输入特征与预测的子词(subword)单元(例如,字素或词片)之间的对准。拼写器是基于注意力的rnn解码器,其通过在假设词语集上产生概率分布来根据输入生成字符序列。利用集成结构,模型的所有组件可以联合地训练为单个端到端(e2e)神经网络。这里,e2e模型是指其架构完全由神经网络构成的模型。全神经网络在没有外部和/或手动设计的组件(例如,有限状态转换器、词典或文本标准化模块)的情况下起作用。此外,当训练e2e模型时,这些模型通常不需要从决策树自举或来自独立系统的时间对准。
5、尽管早期的e2e模型被证明是准确的并且训练提升优于单独训练的模型,但这些e2e模型(诸如las模型)通过在生成输出文本之前检查整个输入序列而起作用,并且因此不允许流输出作为输入被接收。在没有流能力的情况下,las模型不能进行实时语音转录。由于这个缺陷,部署las模型用于延迟敏感或需要实时语音转录的语音应用可能会造成问题。
6、另外,具有声学、发音和语言模型或组合在一起的此类模型的语音识别系统可以依赖于解码器,该解码器必须搜索与这些模型相关联的相对较大的搜索图。对于大型搜索图,完全在设备上托管这种类型的语音识别系统不是有利的。这里,当语音识别系统被托管在“设备上”时,接收音频输入的设备使用其处理器执行语音识别系统的功能。例如,当完全在设备上托管语音识别系统时,设备的处理器不需要与任何设备外的计算资源协调以执行语音识别系统的功能。不完全在设备上执行语音识别的设备依赖于(例如,远程计算系统或云计算的)远程计算并因此依赖于在线连通性来执行语音识别系统的至少一些功能。例如,语音识别系统使用与基于服务器的模型的网络连接利用大搜索图执行解码。
7、不幸的是,依赖于远程连接使得语音识别系统容易遭受延迟问题和/或通信网络的固有不可靠性。为了通过避免这些问题来改进语音识别的实用性,语音识别系统再次进化成被称为递归神经网络换能器(rnn-t)的序列到序列模型的形式。rnn-t不采用注意力机制,并且不像通常需要处理整个序列(例如,音频波形)以产生输出(例如,句子)的其他序列到序列模型,rnn-t连续地处理输入样本和流输出符号,这是对于实时通信特别有吸引力的特征。例如,使用rnn-t的语音识别可以如所讲的那样逐个输出字符。
8、因而,存在对于使用rnn-t来训练数据序列的更高效过程的需要。
技术实现思路
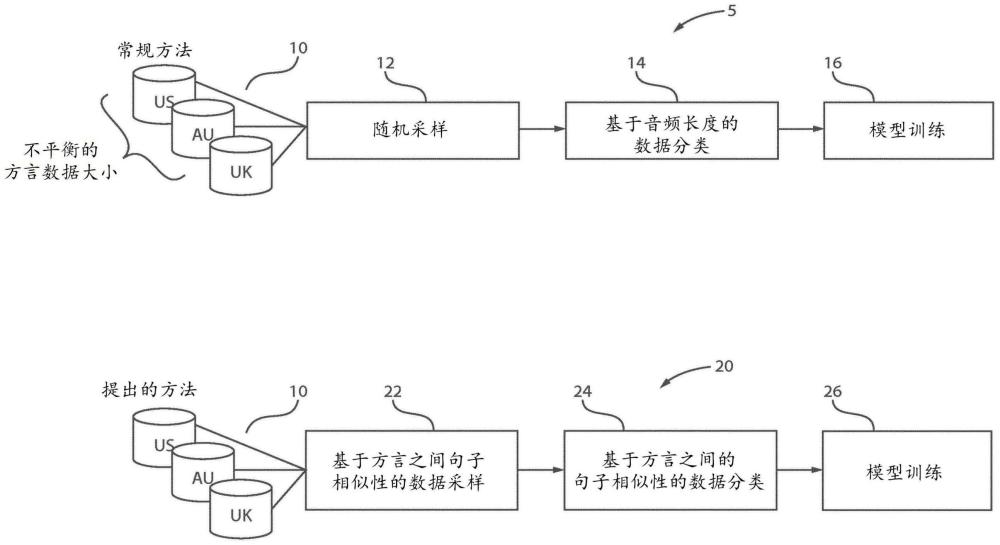
1、根据实施例,提供了一种用于为语音识别模型准备训练数据的计算机实现的方法。该计算机实现的方法包括:获得多个音频数据集,每个音频数据集具有不同的声学特征;以及对来自多个音频数据集的句子进行分类,使得来自不同音频数据集的相似句子紧密定位,同时对音频长度施加弱约束,以训练语音识别模型。
2、根据另一实施例,提供了一种用于为语音识别模型准备训练数据的计算机程序产品。该计算机程序产品包括计算机可读存储介质,所述计算机可读存储介质具有体现在其中的程序指令,程序指令可由计算机执行以使计算机获得多个音频数据集,每个音频数据集具有不同声学特征并且对来自所述多个音频数据集的句子进行分类,使得来自不同音频数据集的相似句子紧密定位,同时对音频长度施加弱约束,以训练语音辨识模型。
3、根据又一实施例,提供了一种用于为语音识别模型准备训练数据的系统。该系统包括存储器和与该存储器通信的一个或多个处理器,该一个或多个处理器被配置为获得多个音频数据集,每个音频数据集具有不同的声学特征,以及对来自该多个音频数据集的句子进行分类,使得来自不同音频数据集的相似句子紧密定位,同时对音频长度施加弱约束,以训练语音识别模型。
4、根据另一实施例,提供了一种用于为语音识别模型准备训练数据的计算机实现的方法。该计算机实现的方法包括:获得多个音频数据集,每个音频数据集具有不同的声学特征,对来自该多个音频数据集的句子进行分类,使得来自不同音频数据集的相似句子紧密定位以训练语音识别模型,以及将来自所述不同音频数据集的相似句子分组成小批量,其中所述小批量中的每个小批量包括不同英语方言之间的句子对。
5、根据又一实施例,提供了一种用于为语音识别模型准备训练数据的计算机程序产品。该计算机程序产品包括计算机可读存储介质,该计算机可读存储介质具有随其包含的程序指令,该程序指令可由计算机执行以使得该计算机:获得多个音频数据集,每个音频数据集具有不同的声学特征,对来自该多个音频数据集的句子进行分类以使得来自不同音频数据集的相似句子被紧密定位以训练语音识别模型,以及将来自该不同音频数据集的相似句子分组成小批量,其中该小批量中的每个小批量包括不同英语方言之间的句子对。
6、在一个优选的方面,从每个具有不同声学特征的数据池采样多个音频数据集,使得所采样的音频数据集包括相似句子的多个集合。
7、在另一优选的方面,引入得分惩罚以控制句子的多样性。
8、在又另一优选的方面,相似句子是具有目标语言的不同方言的相似句子。
9、在又另一优选方面,语音识别模型是用于目标语言的全球语音识别模型。
10、在又另一优选方面,将来自不同音频数据集的相似句子分组成小批量。
11、在又另一优选方面,小批量中的每个小批量包括不同英语方言之间的句子对。
12、在又另一优选方面,小批量中的每个小批量包括相似量的方言数据。
13、在又另一优选方面,来自不同音频数据集的相似句子的不同英语方言之间的相似性由以下公式给出:
14、的单词向量的句子a和b之间的距离,并且p(d)是不构成有偏文本数据的相似性得分依赖性惩罚。
15、在又另一优选的方面,相似性得分依赖性惩罚由以下公式给出:
16、p(d)=γekd-γ(d>0),其中,γ、k是超参数。
17、应注意,参考不同的主题描述了示例性实施例。具体地,参照方法类型权利要求描述了一些实施例,而参照装置类型权利要求描述了其他实施例。然而,本领域的技术人员将从以上和以下描述中得出,除非另外指出,否则除了属于一种类型的主题的特征的任何组合之外,涉及不同主题的特征之间(具体地,方法类型权利要求的特征与装置类型权利要求的特征之间)的任何组合也被认为是在本文档内描述的。
18、从以下将结合附图阅读的对其说明性实施例的详细描述,这些和其他特征和优点将变得显而易见。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24814.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表