具有组件锁定和一阶编辑的文本至图像扩散模型的制作方法
- 国知局
- 2024-07-31 22:37:30
本公开涉及文本至图像模型。
背景技术:
1、文本至图像模型是将自然语言描述(即,用户输入文本)作为输入并且生成与该描述匹配的图像(即,计算机图形)的机器学习模型。虽然文本至图像模型目前已经存在,但是期望基于每个用户来个性化这些模型。文本至图像模型的个性化的任务是生成特定的、独特的用户提供的概念(如对象或风格)的图像并且允许用户使用自由文本“提示”来修改它们的外观或在新角色和新颖场景中组合它们。简单地说,用户提供特定概念的几个训练示例(例如,示例图像)。然后,个性化算法允许学习使用预训练的文本至图像模型和多样的提示来利用这个概念。
2、然而,存在用于对将文本至图像模型个性化的现有解决方案的限制。例如,在保持文本至图像模型被冻结的同时学习每个概念的新的词嵌入向量的一些基于文本逆转(inversion)的方法导致所学习的概念与训练示例仅具有粗粒度的相似性以及与自由形式文本的组合不起作用的情形。类似地,每概念学习两个嵌入(即,每个概念的新的词嵌入向量和在否定提示中应用的词嵌入)的其他文本逆转方法也与训练示例具有粗粒度的相似性。
3、作为另一示例,对整个文本至图像模型进行微调(诸如利用正则化项和非常低的学习率)的方法针对用于每个概念的完全微调模型表现出非常大的存储器或存储占用更新,通常不允许组合多个概念,因为针对每个概念学习了不同的模型,并且倾向于以未知的方式(例如,泄漏、灾难性遗忘等)不利地影响底层文本至图像模型。甚至仅微调交叉注意力键和值层而不是整个模型的方法也表现出类似的限制,例如大的更新占用、不支持连续学习、仅组合在相同会话联合训练的概念的能力、以及对底层文本至图像模型的不利影响。
4、现有解决方案中的另一个问题是过度拟合。本质上,一旦方法已经学习了特定概念,则变得难以通过简单地改变输入文本提示来修改该概念。
5、需要解决这些问题和/或与现有技术相关联的其他问题。例如,对于文本至图像扩散模型的个性化,需要采用组件锁定(component locking)和/或一阶编辑(rank-oneediting),如在以下实施例中所描述的,与文本逆转相比,这可以改进所生成图像的细粒度细节而不会牺牲使用自由形式文本的组合性,这可以减少底层模型的存储器占用空间更新而不是完全微调,并且这可以减少灾难性遗忘和泄漏。
技术实现思路
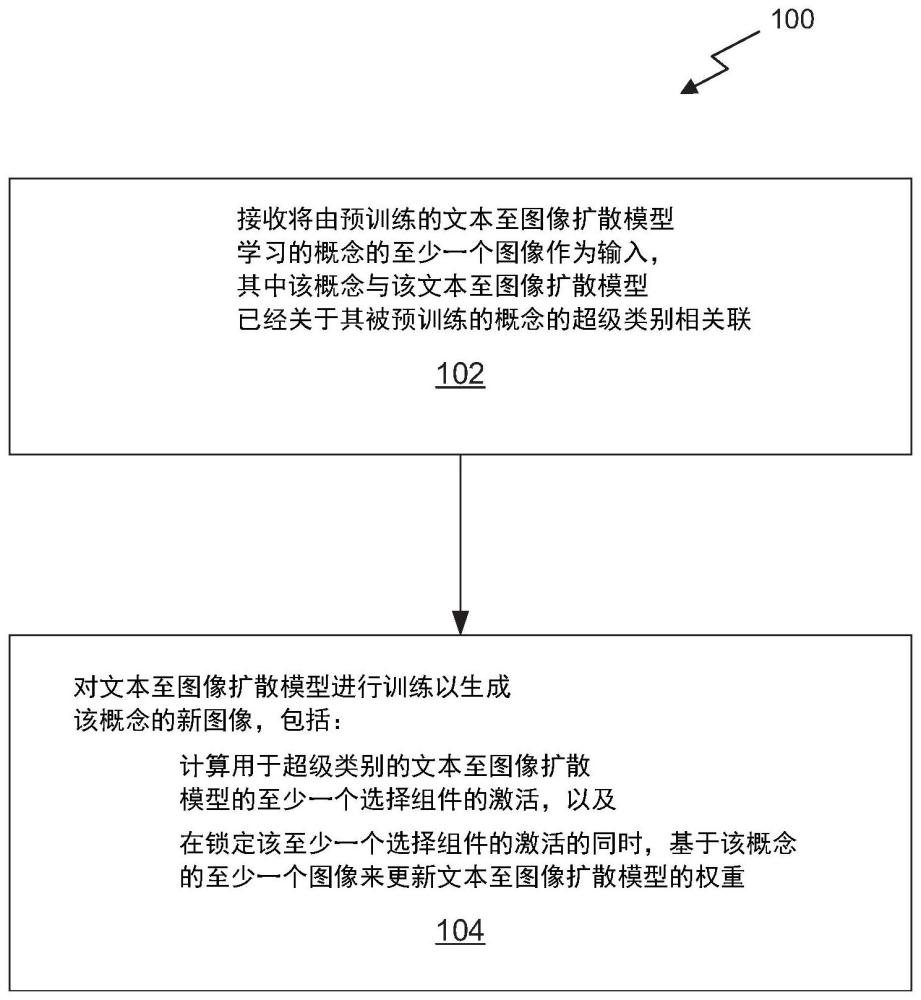
1、公开了一种用于提供文本至图像扩散模型的个性化的方法、计算机可读介质和系统。在一个实施例中,接收将由预训练的文本至图像扩散模型学习的概念(concept)的至少一个图像作为输入,其中该概念与该文本至图像扩散模型已经关于其被预训练的概念的超级类别(category)相关联。该文本至图像扩散模型被训练成生成该概念的新图像,包括:针对该超级类别计算该文本至图像扩散模型的至少一个选择组件的激活,以及在锁定该至少一个选择组件的激活的同时,基于该概念的该至少一个图像更新该文本至图像扩散模型的权重。
2、在另一实施例中,接收将由预训练的文本至图像扩散模型学习的概念的至少一个图像作为输入。该文本至图像扩散模型被训练为生成该概念的新图像,针对该文本至图像扩散模型的至少一个层,包括:将该输入前向传播通过该文本至图像扩散模型以确定至该层的所传播输入,将定义的输出反向传播通过该文本至图像扩散模型以确定该层的目标输出,以及更新该层的权重,使得当该权重被应用于所传播输入时,该层的结果输出与该权重未被更新的情况相比会更紧密地与该目标输出对齐。
3、在又一实施例中,接收将由预训练的文本至图像扩散模型学习的概念的至少一个图像作为输入。该文本至图像扩散模型被训练为生成该概念的新图像,包括:在基于该概念的该至少一个图像更新该文本至图像扩散模型的权重的同时,通过软分割掩模对标准条件扩散损失进行加权。
技术特征:1.一种方法,包括:
2.如权利要求1所述的方法,其中所述输入包括所述概念的多个图像。
3.如权利要求1所述的方法,其中所述超级类别包括对所述超级类别的描述。
4.如权利要求1所述的方法,其中所述输入包括所述概念的单个图像。
5.如权利要求1所述的方法,其中所述至少一个选择组件的所述激活是所述文本至图像扩散模型的交叉注意力模块的k矩阵的输出处的激活。
6.如权利要求1所述的方法,其中所述选择组件是所述文本至图像扩散模型的交叉注意力模块的前馈层的输出处的活动。
7.如权利要求1所述的方法,其中所述至少一个选择组件的所述激活是基于指示所述超级类别的输入文本提示计算的,并且其中在锁定所述至少一个选择组件的所述激活的同时,基于指示所述概念的输入文本提示和所述概念的所述至少一个图像更新所述文本至图像扩散模型的所述权重。
8.如权利要求1所述的方法,其中基于所述概念的所述至少一个图像更新所述文本至图像扩散模型的权重被额外重复至少一次。
9.如权利要求8所述的方法,其中重复更新所述权重,直至满足预定义的目标。
10.如权利要求9所述的方法,其中所述预定义的目标是由至少一个评分函数确定。
11.如权利要求10所述的方法,其中所述预定义的目标是由至少两个评分函数确定的,其中所述至少两个评分函数中的第一评分函数测量针对所述概念的所生成的图像与至少一个图像输入之间的对齐,并且其中所述至少两个评分函数中的第二评分函数测量所生成的图像与输入文本提示之间的对齐。
12.如权利要求1所述的方法,其中在锁定之前调制所述激活。
13.如权利要求12所述的方法,其中所述超级类别的注意力图用于调制所述激活。
14.一种方法,包括:
15.如权利要求14所述的方法,其中更新所述层的所述权重取决于针对输入文本提示中的一个或更多个词的所述目标输出。
16.如权利要求14所述的方法,其中所述至少一个层是所述文本至图像扩散模型的至少一个交叉注意力模块中的线性投影层。
17.如权利要求14所述的方法,其中所述至少一个层是所述文本至图像扩散模型的至少一个交叉注意力模块中的卷积层的内核矩阵。
18.如权利要求14所述的方法,其中更新所述权重是基于所述输入与所述层的所传播输入之间的相似性来控制的。
19.如权利要求14所述的方法,其中针对不同范围的去噪时间戳来训练对所述权重的不同更新。
20.一种方法,包括:
21.如权利要求20所述的方法,其中从零样本图像分割模型获得所述软分割掩模。
22.如权利要求20所述的方法,其中所述软分割掩模中的值由其最大值进行归一化。
23.一种系统,包括:
24.如权利要求23所述的系统,其中所述选择组件是所述文本至图像扩散模型的交叉注意力模块的前馈层的输出处的活动。
25.如权利要求23所述的系统,其中所述至少一个选择组件的所述激活是基于指示所述超级类别的输入文本提示计算的,并且其中在锁定所述至少一个选择组件的所述激活的同时,基于指示所述概念的输入文本提示和所述概念的所述至少一个图像更新所述文本至图像扩散模型的所述权重。
26.一种非暂时性计算机可读介质,其存储计算机指令,所述计算机指令在由设备的一个或更多个处理器执行时,使所述设备:
27.如权利要求26所述的非暂时性计算机可读介质,其中所述至少一个选择组件的所述激活是基于指示所述超级类别的输入文本提示计算的,并且其中在锁定所述至少一个选择组件的所述激活的同时,基于指示所述概念的输入文本提示和所述概念的所述至少一个图像更新所述文本至图像扩散模型的所述权重。
28.如权利要求26所述的非暂时性计算机可读介质,其中重复基于所述概念的所述至少一个图像更新所述文本至图像扩散模型的权重,直到满足预定义的目标,并且其中所述预定义的目标是基于针对所述概念的所生成的图像与所述至少一个图像输入之间的对齐、以及所生成的图像与输入文本提示之间的对齐。
技术总结本发明公开了具有组件锁定和一阶编辑的文本至图像扩散模型,具体公开了文本至图像机器学习模型获取用户输入文本并且生成与给定描述匹配的图像。虽然目前存在文本至图像模型,但是期望基于每个用户来个性化这些模型,包括配置模型以生成特定的、独特的用户提供的概念的图像(经由特定对象或风格的图像),同时允许用户使用自由文本“提示”来修改其外观或在新角色和新颖场景中合成它们。当前的个性化解决方案要么生成与所提供的一个或更多个概念仅具有粗粒度相似性的图像,要么需要对整个模型进行微调,这是昂贵的并且可能不利地影响该模型。本描述采用组件锁定和/或一阶编辑来进行文本至图像扩散模型的个性化,这可以改进所生成的图像中的概念的细粒度细节,减少底层模型的存储器占用空间更新,而不是完全微调,并且减少对模型的不利影响。技术研发人员:Y·阿兹蒙,Y·图韦尔,R·高尔,G·切奇克受保护的技术使用者:辉达公司技术研发日:技术公布日:2024/7/25本文地址:https://www.jishuxx.com/zhuanli/20240730/193881.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。