基于深度学习的砂岩型铀矿含铀层自动识别方法及系统
- 国知局
- 2024-07-31 22:44:46
本发明涉及深度学习,具体是指基于深度学习的砂岩型铀矿含铀层自动识别方法及系统。
背景技术:
1、对于现有的含铀层自动识别方法,单独依靠基本模型或传统方法,存在检索效率低、分类精度下降的问题,无法充分提取图像的深层次特征,导致特征表示不够精确,同时缺乏有效的深层特征提取和二值化处理,分类模型可能无法准确区分含铀层和非含铀层,识别精度下降;现有的在大规模数据集上直接操作高维特征,导致存储空间和计算时间成倍增加,存在处理效率低下的问题;一般的检索方法存在检索效率低、计算资源消耗高和检索精度受限的问题,全库扫描方式导致检索效率低,尤其是在数据量庞大时,无法满足实时检索的需求,逐个计算哈希码之间的距离,消耗大量计算资源,尤其在大规模数据集上,计算资源的需求会成倍增加,同时容易受到噪声数据的影响,可能导致检索结果包含更多不相关的哈希码,降低检索精度。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了基于深度学习的砂岩型铀矿含铀层自动识别方法及系统,本方法中使用端到端深度哈希模型通过基本模型和卷积自编码器的结合,有效提取图像的初步和深层特征,提高了特征表示的精度,生成的低维二值哈希码大大减少了存储空间和计算复杂度,使得图像检索过程更加快速高效,通过深度特征提取和二值量化,模更准确地识别和区分含铀层和非含铀层,提高了识别的准确率;通过使用哈希码数据库,压缩高维特征,减少了数据的存储需求和计算量,显著提升了大规模数据处理的效率,同时使用汉明距离进行快速相似性计算,大幅提升图像检索速度,适应实时应用场景;使用结合硬k均值和模糊c均值找出最近邻图像,通过硬k均值聚类,将哈希码数据库划分为若干个簇,检索时首先定位到最近的簇,再在该簇内进行详细匹配,大幅减少了需要计算距离的哈希码数量,提升检索效率,同时通过聚类,将相似的哈希码集中在一起,减少噪声数据的干扰,提高检索结果的相关性和精度,聚类后仅需在少量簇内进行距离计算,显著减少计算资源消耗,提高系统的资源利用率。
2、本发明采取的技术方案如下:本发明提供的基于深度学习的砂岩型铀矿含铀层自动识别方法,该方法包括以下步骤:
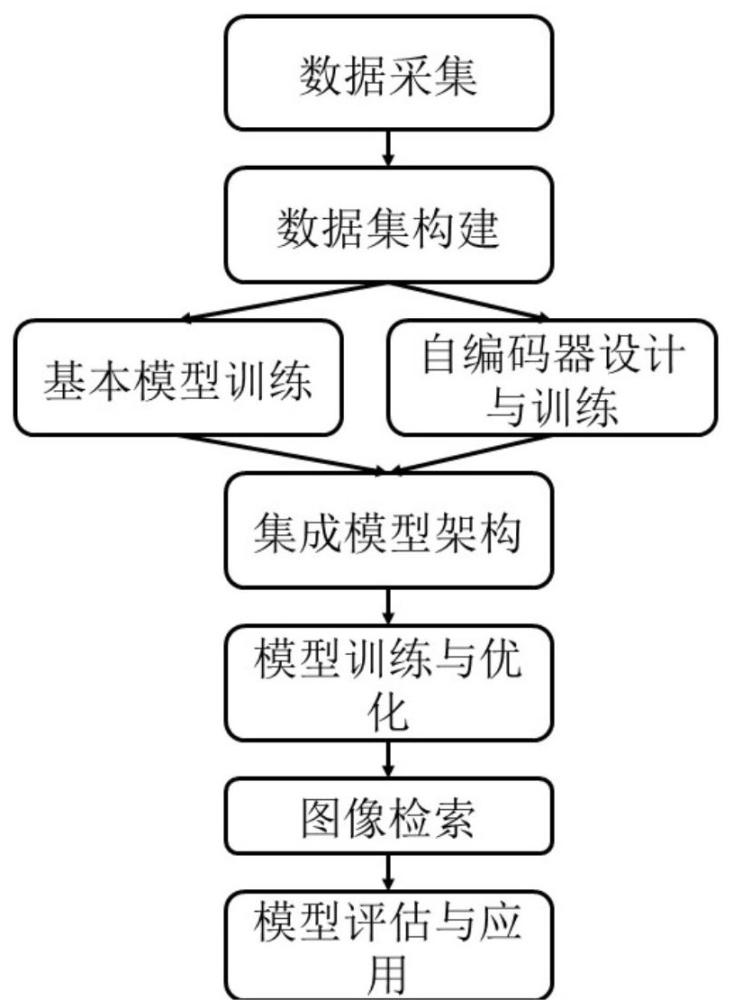
3、步骤s1:数据采集,收集砂岩型铀矿地质图像数据,使用半自动标注工具对砂岩型铀矿地质图像数据进行区分,标注为含铀层和非含铀层,同时收集其他矿石类型的图像数据;
4、步骤s2:数据集构建,构建充足数据集、稀缺数据集和较大数据集,充足数据集将砂岩型铀矿的地质图像数据和其他矿石类型的图像数据放入,稀缺数据集放入砂岩型铀矿地质图像数据,较大数据集包含充足数据集和稀缺数据集;
5、步骤s3:基本模型训练,使用预训练的resnet模型作为基本模型,在较大数据集上微调基本模型,适应砂岩型铀矿图像的特征;
6、步骤s4:自编码器设计与训练,设计一个包含编码器和解码器的卷积自编码器,编码器部分压缩图像信息,解码器部分重构图像,在自编码器中加入跳过连接,并且在稀缺数据集上训练自编码器;
7、步骤s5:集成模型架构,将基本模型和卷积自编码器无缝集成,形成端到端的深度哈希模型,基本模型处理输入图像并提取初步特征,初步特征作为卷积自编码器的输入,卷积自编码器进一步提取深层特征并生成哈希码,自编码器的最后一层将高维特征向量映射为低维二值哈希码;
8、步骤s6:模型训练与优化,设计损失函数,先在充足数据集上训练基本模型,再在稀缺数据集上训练自编码器,使用数据增强和随机梯度下降方法进行优化,得到训练后的端到端深度哈希模型;
9、步骤s7:图像检索,收集需要检测的地质图像,使用低维二值哈希码对新收集的地质图像进行比较,得到识别结果;
10、步骤s8:模型评估与应用,使用平均精度分数作为主要性能指标评估模型的检索效果,在实际勘探中部署训练后的端到端深度哈希模型,对实际勘探中新采集的地质图像进行含铀层识别和检索。
11、进一步的,步骤s4,具体包括以下内容:
12、编码器设计:将输入的砂岩型铀矿地质图像数据压缩为低维度的特征表示,使用卷积神经网络作为编码器,由三层卷积层组成,每层卷积层后接一个池化层,每个卷积层使用relu激活函数;
13、解码器设计:解码器与编码器对称,通过三层反卷积层将编码后的低维度的特征表示解码重构为与原始输入尺寸相同的图像;
14、引入跳过连接:在自编码器中引入跳过连接,在编码器的每个卷积层后,将低维度的特征表示输出直接连接到解码器的对应的反卷积层输入;
15、损失函数设计:使用重构误差、量化损失、两两相似度损失综合设计总损失函数,具体包括以下内容:
16、重构损失:使用均方误差衡量图像与输入图像之间的差异,所用公式如下:
17、;
18、其中,为重构损失,为样本数量,为第个输入图像,为第个通过自编码器解码器生成的重构图像;
19、量化损失:将高维特征向量映射为低维二值哈希码,引入量化损失,所用公式如下:
20、;
21、其中,为量化损失,为第个样本的高维特征向量,是对进行符号函数操作得到的二值向量;
22、两两相似度损失:所用公式如下:
23、;
24、其中,为两两相似度损失,为第个样本与第个样本之间的相似度矩阵元素,表示这两个样本之间的相似度,、为第、个样本的高维特征向量;
25、总损失函数:设计总损失函数,所用公式如下:
26、;
27、其中,为重构损失的权重参数,为量化损失的权重参数,为两两相似度损失的权重参数;
28、进一步的,步骤s7,具体包括以下步骤:
29、步骤s71:收集图像,收集需要检测的地质图像并进行预处理,得到处理后的地质图像;
30、步骤s72:提取图像特征,将处理后的地质图像输入训练后的端到端深度哈希模型,其中的基本模型对处理后的地质图像进行处理,提取初步特征;
31、步骤s73:生成哈希码,将初步特征输入卷积自编码器,自编码器进一步提取深层特征并生成高维特征向量;
32、步骤s74:二值量化,将自编码器生成的高维特征向量通过二值化技术映射为低维二值哈希码;
33、步骤s75:哈希码比较,构建一个哈希码数据库,包含训练过程中生成的所有图像的哈希码及其对应的标签,对于步骤s74生成的低维二值哈希码,计算出与哈希码数据库中所有哈希码之间的汉明距离;
34、步骤s76:图像检索与匹配,根据计算出的汉明距离,使用结合硬k均值和模糊c均值找出最近邻图像,根据最近邻图像的标签判断类别;
35、进一步的,步骤s76,具体包括以下步骤:
36、步骤s761:选择硬k均值聚类,将哈希码数据库中的所有哈希码进行硬k均值聚类,得到k个簇中心;
37、步骤s762:初步匹配,对于需要检测的地质图像,根据计算出的汉明距离,找出距离最近的簇中心,初步确定需要检测的地质图像属于距离最近的簇;
38、步骤s763:使用模糊c均值聚类,对k个簇中心对应的每个簇进行模糊c均值聚类,得到每个簇中哈希码的隶属度;
39、步骤s764:细化匹配,选择隶属度高的哈希码作为候选哈希码;
40、步骤s765:最近邻图像匹配,使用候选哈希码对应的地质图像作为最近邻图像;
41、步骤s766:类别判断,根据最近邻图像的标签,确定需要检测的地质图像的类别。
42、本发明提供的基于深度学习的砂岩型铀矿含铀层自动识别系统,包括数据采集与预处理模块、数据集构建模块、端到端的深度哈希模型和图像检索匹配模块,具体包括以下内容:
43、所述数据采集与预处理模块收集砂岩型铀矿地质图像数据并进行预处理;
44、所述数据集构建模块将收集的地质图像数据划分为充足数据集、稀缺数据集和较大数据集;
45、所述端到端的深度哈希模型结合基本模型和卷积自编码器,提取砂岩型铀矿地质图像数据特征并生成低维二值哈希码;
46、所述图像检索匹配模块利用生成的低维二值哈希码进行图像比较和匹配,使用结合硬k均值和模糊c均值找出最近邻图像并进行分类。
47、采用上述方案本发明取得的有益效果如下:
48、(1)对于现有的含铀层自动识别方法,单独依靠基本模型或传统方法,存在检索效率低、分类精度下降的问题,无法充分提取图像的深层次特征,导致特征表示不够精确,同时缺乏有效的深层特征提取和二值化处理,分类模型可能无法准确区分含铀层和非含铀层,识别精度下降,本方法中使用端到端深度哈希模型通过基本模型和卷积自编码器的结合,有效提取图像的初步和深层特征,提高了特征表示的精度,生成的低维二值哈希码大大减少了存储空间和计算复杂度,使得图像检索过程更加快速高效,通过深度特征提取和二值量化,模更准确地识别和区分含铀层和非含铀层,提高了识别的准确率;
49、(2)对于现有的在大规模数据集上直接操作高维特征,导致存储空间和计算时间成倍增加,处理效率低下,通过使用哈希码数据库,压缩高维特征,减少了数据的存储需求和计算量,显著提升了大规模数据处理的效率,同时使用汉明距离进行快速相似性计算,大幅提升图像检索速度,适应实时应用场景;
50、(3) 现有的检索方法存在检索效率低、计算资源消耗高和检索精度受限的问题,全库扫描方式导致检索效率低,尤其是在数据量庞大时,无法满足实时检索的需求,逐个计算哈希码之间的距离,消耗大量计算资源,尤其在大规模数据集上,计算资源的需求会成倍增加,同时容易受到噪声数据的影响,可能导致检索结果包含更多不相关的哈希码,降低检索精度,本发明使用结合硬k均值和模糊c均值找出最近邻图像,通过硬k均值聚类,将哈希码数据库划分为若干个簇;检索时首先定位到最近的簇,再在该簇内进行详细匹配,大幅减少了需要计算距离的哈希码数量,提升检索效率,同时通过聚类,将相似的哈希码集中在一起,减少噪声数据的干扰,提高检索结果的相关性和精度,聚类后仅需在少量簇内进行距离计算,显著减少计算资源消耗,提高系统的资源利用率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194421.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。