基于改进CTGAN网络的油茶树固有频率数据增强方法
- 国知局
- 2024-07-31 22:46:55
本发明涉及林果振动采收的,尤其是指一种基于改进ctgan网络的油茶树固有频率数据增强方法。
背景技术:
1、由于油茶果采摘的季节性强、采收期短,所以目前应用最多的采收方式是振动采收,其采摘效率和采净率高。而振动采收的效果与采收装备作业时的振动频率密切相关,如果振动频率与固有频率接近或相同,能量传递将更有效,更容易使果实脱落。
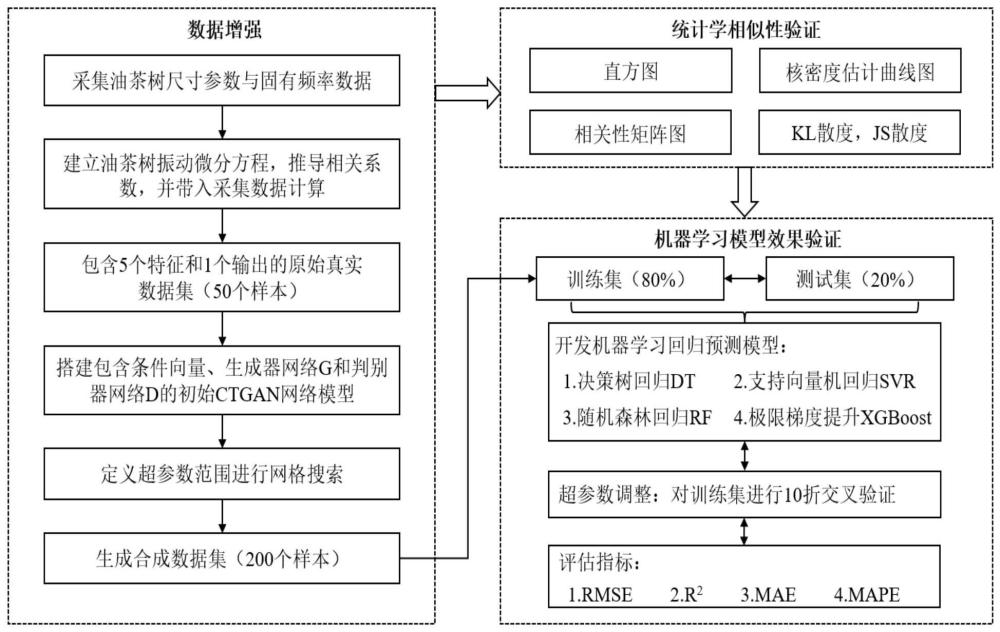
2、传统的油茶树固有频率预测方法主要应用油茶树三维模型构建和有限元模态分析的方法,但每棵油茶树的结构、刚度和阻尼的不同会导致固有频率不同,依次对其进行建模和有限元分析太过繁琐耗时。近年来,随着机器学习技术的发展,利用数据驱动的方法进行油茶树固有频率预测已被学者证明可行,但这种方法需要大量的数据进行训练,而采集油茶树固有频率预测的数据集非常耗时。
3、ctgan(conditional tabular generative adversarial network,条件表格生成对抗网络)是一种针对表格数据的生成对抗网络,它通过引入条件生成器和判别器,能够根据给定的条件生成具有特定特征的表格数据。ctgan模型能够学习预测目标和输入特征之间潜在关系,极大地保留真实数据的原始信息。因此,利用ctgan对油茶固有频率预测数据集进行增强,有望提高预测模型的性能和泛化能力。
技术实现思路
1、本发明的目的在于克服现有技术的缺点与不足,提出了一种基于改进ctgan网络的油茶树固有频率数据增强方法,将有限的原始训练样本进行扩充,生成满足真实数据分布的新样本,以满足机器学习模型对数据样本的要求。
2、为实现上述目的,本发明所提供的技术方案为:基于改进ctgan网络的油茶树固有频率数据增强方法,包括以下步骤:
3、1)建立简化的油茶树三自由度质量-弹簧-阻尼模型,构建并求解油茶树受迫振动微分方程,得到油茶树固有频率ω与弹性模量e、密度ρ、各级枝条的横截面直径d和长度l之间的方程;
4、2)采集多组油茶树尺寸参数和固有频率数据,构建原始真实数据集;
5、3)将原始真实数据集输入构建的改进ctgan网络,通过最小化原始真实数据集与合成数据集之间的皮尔逊相关系数绝对差得到最优的改进ctgan网络,再训练该最优的改进ctgan网络生成多组合成数据;其中,所述改进ctgan网络是对包含条件向量、生成器g和判别器d的ctgan网络加入了超参数网格搜索模块,用于对超参数进行网格搜索寻优;
6、4)使用统计学方法对合成数据的质量进行评估,验证生成的合成数据是否满足原始真实数据集的特征分布;开发机器学习模型对合成数据进行回归预测,计算机器学习模型的评估指标,验证生成的合成数据的质量。
7、进一步,在步骤1),将油茶树简化为三自由度质量-弹簧-阻尼模型,将油茶树的结构分为主干、主枝和次级枝三部分,将油茶树主干质量等效为m1,主干弹性系数等效为k1,主干阻尼系数等效为c1,将油茶树所有主枝质量等效为m2,所有主枝弹性系数等效为k2,所有主枝阻尼系数等效为c2,将油茶树所有次级枝质量等效为m3,所有次级枝弹性系数等效为k3,所有次级枝阻尼系数等效为c3;对于树干振动式油茶果采收,激振力q通过激振装置作用在主干上,令油茶树主干、主枝和次级枝受到激振力q作用时离开平衡位置的位移分别为x1、x2和x3;
8、根据牛顿第二定律,构建油茶树受迫振动微分方程,公式表示如下:
9、
10、式中,代表主干的加速度,代表主干的速度,代表主枝的加速度,代表主枝的速度,代表次级枝的加速度,代表次级枝的速度,代表激振力的频率,t代表时间,sin代表求正弦;
11、将油茶树受迫振动简化为无阻尼振动,并将油茶树受迫振动微分方程写成矩阵形式,列出矩阵形式的油茶树受迫振动微分方程和特征方程,公式分别表示如下:
12、
13、det[k-ω2m]=0
14、式中,[m]代表质量的矩阵形式,代表加速度的矩阵形式,[k]代表弹性系数的矩阵形式,{x}代表位移的矩阵形式,det[]代表矩阵的行列式,ω代表油茶树固有频率;
15、整理特征方程,得到油茶树固有频率ω与主干质量m1、主干弹性系数k1,所有主枝质量m2、所有主枝弹性系数k2、所有次级枝质量m3和所有次级枝弹性系数k3之间的特征方程,公式表示如下:
16、
17、为了简化计算,将树枝近似为圆柱杆,则枝条的等效质量为:
18、
19、式中,m代表树枝的质量,ρ代表树枝的密度,v代表树枝的体积,d代表树枝的横截面直径,l代表树枝的长度;
20、根据材料力学,截面为圆形的杆件,其惯性矩i为:
21、
22、树枝的转动刚度k为:
23、
24、式中,e代表树枝的弹性模量;
25、将k和m带入整理后的特征方程中得:
26、
27、
28、
29、
30、式中,a、b、c代表中间变量,d1代表油茶树主干的横截面直径,l1代表油茶树主干的长度;i代表第几个油茶树主枝,i的取值范围为从1到u,u代表油茶树主枝的数量,d2i代表第i个油茶树主枝的横截面直径,l2i代表第i个油茶树主枝的长度;j代表第几个油茶树次级枝,j的取值范围为从1到v,v代表油茶树次级枝的数量,d3j代表油茶树次级枝的横截面直径,l3j代表油茶树次级枝的长度。
31、进一步,在步骤2),从油茶标准化种植基地中随机选取多棵油茶样本树,统计以下数据:每棵样本树主枝的数量u,次级枝的数量v,利用卷尺和游标卡尺分别测得油茶样本树主干长度l1、主枝长度l2i、次级枝长度l3j、主干横截面直径d1、主枝横截面直径d2i和次级枝横截面直径d3j,使用锤击法测得油茶树的固有频率ω,具体是通过固定冲击力锤和移动加速度传感器的方式,在树干固定位置处用冲击力锤敲击,移动加速度传感器在主枝和次级枝多个测量点的位置上进行测量;
32、将统计到的上述数据带入到步骤1)中的a、b、c中计算,将五个输入特征包括计算得到的a、b、c、u、v和预测目标油茶树的固有频率ω构建原始真实数据集。
33、进一步,在步骤3),改进ctgan网络会根据原始真实数据的类别进行特定的数据预处理操作:将离散列即每棵样本树主枝数量u和次级枝数量v进行独热编码,将连续列a、b、c、ω的值进行特定模式归一化处理,具体是通过多个拥有不同权重和标准偏差的高斯曲线对连续值进行拟合,并引入条件向量使生成器g通过采样进行训练,生成器g利用随机噪声生成最初的与原始真实数据相似的合成数据,将其与预处理后的真实数据输入判别器d进行对抗性训练,并由判别器d进行对比判别;其中,为了生成与真实数据相似的新样本,需要最小化生成器g和判别器d之间的损失函数,通过超参数网格搜索模块,找到最优的一组超参数,训练最优超参数下的改进ctgan网络,生成最终的多组合成数据。
34、进一步,所述超参数网格搜索模块具体执行以下操作:
35、a、定义超参数网格搜索范围,涉及到的超参数包括传递给生成器的随机样本大小(embedding_dim)、每个残差层的输出样本大小(generator_dim)、每个判别器层的输出样本大小(discriminator_dim)、生成器的学习率(generator_lr)、adam(adaptive momentestimation,自适应矩估计)优化器的生成器权重衰减(generator_decay)、判别器的学习率(discriminator_lr)、adam优化器的判别器权重衰减(discriminator_decay)和每一步要处理的数据样本量大小(batch_size);
36、b、在训练次数(epochs)达到预设值时生成一个合成数据集;
37、c、为了评估生成数据的质量,需要计算原始真实数据集和合成数据集之间皮尔逊相关系数的绝对差ρx,y,公式表示如下:
38、
39、式中,x代表原始真实数据集,y代表合成数据集,cov(x,y)代表原始真实数据集x和合成数据集y之间的协方差,σx和σy分别代表原始真实数据集x和合成数据集y之间的标准差,e表示期望;
40、d、每循环迭代一次就更新一次ρx,y值最小时的超参数组合,然后继续调整训练次数(epochs)和数据样本量大小(batch_size)的值,不断循环直至网格搜索完成,此时会输出一个ρx,y值最小时的超参数组合,打印这个最佳超参数组合,训练最佳超参数组合下的改进ctgan网络以学习原始真实数据集的数据分布和油茶树尺寸参数与固有频率之间的潜在关系,最后生成最满足真实数据分布的合成数据。
41、进一步,在步骤4),根据步骤3)生成的合成数据集,使用统计学方法对合成数据的质量进行评估,统计学方法包括数据分布的可视化和一些相关性指标的比较,数据分布能够比较原始真实数据和合成数据的相似性,优选直方图和核密度估计曲线图两种方法,相关性比较能够量化数据集变量之间的相似关系,优选相关性矩阵和计算kl散度、js散度两种方法;其中,原始数据和合成数据的kl散度和js散度的计算公式如下:
42、
43、
44、式中,kld(x||y)代表计算原始真实数据集x和合成数据集y的kl散度,jsd(x||y)代表计算原始真实数据集x和合成数据集y的js散度,a代表原始真实数据集x中的样本,f(a)代表原始真实数据的概率分布,h(a)代表合成数据的概率分布,n(a)代表f(a)和h(a)的平均分布,kld(f(a)||n(a))代表计算f(a)和n(a)的kl散度,kld(h(a)||n(a))代表计算h(a)和n(a)的kl散度,kl散度和js散度都大于或等于0,且越小表示越相似,越大表示越不相似。
45、进一步,在步骤4),将步骤3)生成的合成数据集80%的样本划分为训练集,将20%的样本划分为测试集,开发优选的适合小样本的四种机器学习模型,包括决策树回归dt、支持向量机回归svr、随机森林回归rf和极限梯度提升xgboost;为了获得最佳的机器学习模型,对训练集使用10折交叉验证调整每个机器学习模型各自的超参数,将训练集分为10个大小相等的子集,其中9个用于训练,余下1个用作验证,重复10次,并优选4种回归评估指标,定量评估使用改进ctgan网络进行数据增强后机器学习模型的准确性,包括指标:均方根误差rmse、决定系数r2、平均绝对误差mae和平均绝对百分比误差mape,各指标计算方程如下:
46、
47、
48、
49、
50、式中,s代表样本数量,z代表第几个样本,yz代表真实值,代表预测值,代表真实值yz的平均值;其中,r2越接近1,rmse、mae和mape越小,模型的性能越好。
51、本发明与现有技术相比,具有如下优点与有益效果:
52、1、对包含条件向量、生成器g和判别器d的ctgan网络加入了超参数网格搜索模块,使ctgan网络的效果最优。
53、2、本发明方法能够很好地学习到油茶树尺寸参数和固有频率之间的潜在关系,生成出的合成样本能够满足原始真实数据集的分布。
54、3、通过油茶树三自由度质量-弹簧-阻尼模型推导出油茶树基本尺寸参数和固有频率之间的关系式,考虑将推导出的a、b、c三个系数应用到改进ctgan网络的输入中,这样避免了直接将所有油茶树尺寸参数全部作为输入而导致的特征维度爆炸问题。
55、4、条件向量的引入可以确保生成的数据和原始真实数据的分布相符,通过改变条件向量的取值还可以生成不同特征的油茶树固有频率数据,从而增加数据的多样性。
56、5、提出了一套完整的数据增强与效果验证的方案,利用统计学方法和机器学习模型两个方法对合成数据的质量进行验证,可以系统地评估合成数据的质量。
57、6、本发明方法具有很好的可扩展性,可以应用于其它林果类振动采收的固有频率预测环节中去进行又快又好的数据增强。
58、7、对小样本数据进行扩充也能提高后续固有频率机器学习回归预测模型的性能,使模型训练得更充分。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194556.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。