一种基于深度学习的智能物流四级行政区划及实体地址识别方法及识别系统与流程
- 国知局
- 2024-07-31 22:47:51
本发明涉及到智能物流,特别涉及到一种基于深度学习的智能物流四级行政区划及实体地址识别方法。
背景技术:
1、在现代物流行业中,地址解析是一个关键的技术,它用于将输入的地址信息转化为具体的行政区划信息和地址实体,如省、市、区、乡镇、街道等,以便进行包裹配送、路线规划、物流管理等工作。地址解析的准确性和效率对于物流行业的运营和服务质量至关重要。传统的地址解析方法通常基于规则匹配和关键词提取,但由于地址文本的复杂多样性,传统方法往往难以涵盖所有情况,并且容易受到地址表达方式的变化影响,导致解析准确率不高。例如,地址中可能会出现缺失信息、错别字、简写、别名等问题,增加了地址解析的复杂性。近年来,自然语言处理(nlp)和深度学习技术的迅速发展为地址解析带来了新的机遇。
2、bert(bidirectional encoder representations from transformers)作为一种预训练的语言表示模型,通过双向上下文建模,具有强大的语义理解和表征能力,能够在各种nlp任务中取得优异的表现。在地址实体识别任务中,bert可以将地址文本映射为高维向量空间,有效地捕捉地址中的关键信息和上下文语境,从而实现对地址实体的准确识别和提取。
3、此外,bert模型还可以结合传统规则方法,通过迁移学习或微调等技术,进一步提高地址解析的准确率和适应性。然而,尽管bert模型在自然语言处理任务中表现优秀,但在物流地址行政区划和地址实体识别领域的应用还相对较少。现有技术往往缺乏针对物流行业特定场景的优化和训练,因此仍有改进和创新的空间。因此,有必要提供一种基于bert模型的物流地址行政区划和地址实体识别系统,以满足物流行业对于高准确性、高效率的地址解析需求。
技术实现思路
1、本发明的目的在于克服上述现有技术存在的不足,提供一种基于深度学习的智能物流四级行政区划及实体地址识别方法。本发明的识别方法要能够解决传统物流地址解析系统中人工标注数据缓慢和标注成本高的问题。
2、为了达到上述发明目的,本发明专利提供的技术方案:
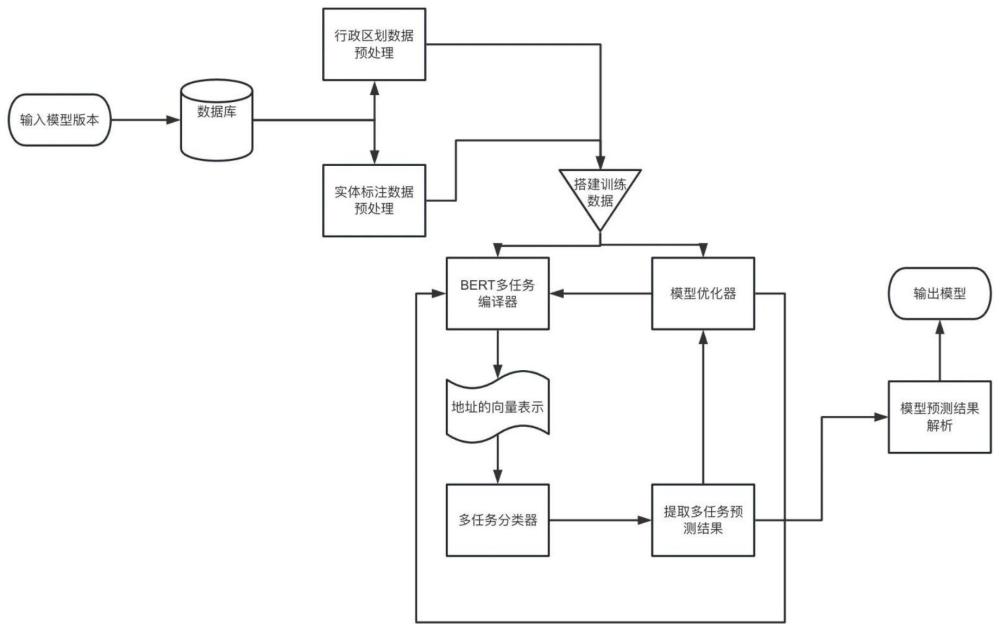
3、一种基于深度学习的智能物流四级行政区划及实体地址识别方法,该识别方法将行政区划地址处理和实体地址处理任务结合在一起,通过共享模型参数,来提高模型的参数效率和训练效率,该识别方法包括如下步骤:
4、s1.行政区划地址处理环节,
5、s11.行政区划标签数据获取,利用业务数据库,从已有的物流地址中获得分类标签数据,该业务数据含有大量已经解析好的物流地址,每个地址都经过人工或半自动标注了相应的行政区划分类标签;
6、s12.在获得行政区划标签数据后,进行标签数据准备,准备工作包括数据清洗、去重、格式转换,确保数据的质量和统一;
7、s13.进行数据标注,将准备好的行政区划标签数据与地址文本对应起来,形成第一个训练集;
8、s2.实体地址处理环节,
9、s21.通过与第三方地址解析接口交互以获取标注数据,从外部获取命名实体识别的地址标注数据;
10、s22.对获得的第三方解析的地址标注数据进行整理和转换,包括数据清洗和格式转换,以获得适应的数据格式和标签定义;
11、s23.将整理好的地址数据与地址文本对应起来,形成第二个训练集;
12、s3.分类任务及命名实体识别任务环节,
13、s31.输入编码:将第一训练集和第二训练集均输入到bert编码器中,获得地址文本的上下文向量表示;
14、s32.分类任务:通过bert编码器的上下文向量表示对行政区划地址进行分类任务,将地址文本划分为省、市、区县及乡镇的类别,实现行政区划地址的准确提取;
15、s33.命名实体识别任务:在bert编码器模块中添加实体地址处理模块定义的实体标签,进行命名实体识别任务,准确地识别出地址文本中各类实体的边界和类型;
16、s34.动态loss权重调整:优化多任务学习中的loss函数,在训练过程中根据任务的难易程度和样本分布情况动态调整不同任务的loss权重,使模型更关注关键任务和难以识别的样本;
17、s35.利用信息熵进行bert编码器模型优化:信息熵衡量一个随机变量的不确定程度,将信息熵引入到多任务学习中,通过最小化信息熵来优化模型的泛化能力和鲁棒性;
18、s4.结果解析环节,解析bert编码器模块的输出结果,将识别出的行政区划地址和地址实体进行整合和解析,得到最终的地址解析结果,对解析结果进行后处理和规则匹配,确保最终结果的准确性和可读性。
19、在s1中,标注了行政区划分类标签含有“省份”、“城市”、
20、“区县”和“乡镇”,在数据标注过程中,为每个地址文本指定相应的行政区划分类标签。
21、在s2中,第三方接口获取的标注数据来源包括有公开数据集和地图服务提供商,已经进行了实体识别和命名实体标注,在数据标注过程中,为每个地址文本指定相应的实体地址标签,包括人名、公司名或街道名。
22、在s33中,引入tf/idf算法对不同网点下的实体进行筛选,所述tf/idf算法的核心包括词频(tf)和逆文档频率(idf)两部分,词频衡量某个词在单个文档中出现的频率,某个词在文档中出现次数越多,其对文档的重要性越大,逆文档频率衡量一个词的普遍重要性,在少数文档中出现的词比在大多数文档中都出现的词更有区分度,将每个网点中的实体作为tf-idf中需要计算的词,得到某个网点下特有的词语,出现的频率越高则得分越高越具有代表性,出现次数少则得分低,不具有代表性;某些普遍性的实体词汇,则通过逆文档频率做区分,使得这类普遍的词得分会很低,通过tf-idf的得分则可以去衡量一个网点下实体的重要程度以及实体的质量程度,
23、tf-idf=tf×idf
24、
25、
26、其中,各参数含义为,tf(term frequency):这是一个用于量化单词在文档中出现的频率的度量。
27、idf是衡量一个词语在文档集合中的重要性的度量。w表示一个单词,越是少见的词语,在idf计算中的得分就越高。
28、tf-idf是一个统计方法,用于评估一个词语在一个文档集合或语料库中的重要性。tf-idf值是通过将tf值(一个词语在单个文档中的出现频率)和idf值(一个词语在整个文档集合中的重要性)相乘来得到的。
29、在s34中,设定分类任务的loss为l_class,命名实体识别任务的loss为l_ner,loss权重分别为α和β,优化目标可以表示为:
30、minimizeα*l_class+β*l_ner
31、通过不断调整α和β的值,动态地平衡两个任务的重要性,使模型在训练过程中更加关注效果较差或难以识别的任务。
32、进一步地,在训练过程中,可以根据每个任务的loss值和样本分布情况,利用梯度信息或样本权重算法来动态地更新α和β的值,实现动态loss权重调整的目标。
33、在s35中,设定bert模型对于分类任务的输出为p_i,其中i表示类别的索引,则模型的预测概率向量为[p_1,p_2,...,p_n],其中n为类别总数,
34、信息熵h(p)可定义如下:
35、h(p)=-σ(p_i*log(p_i))
36、其中,log为自然对数,得到信息熵的值越大,表示预测的不确定性越高,优化模型是获得最小化信息熵。
37、进一步地,优化目标为最小化总体的信息熵,即分类任务和命名实体识别任务的信息熵之和,优化目标表示为:
38、minimize h_class(p)+λ*h_ner(p)
39、其中,h_class(p)为分类任务的信息熵,h_ner(p)为命名实体识别任务的信息熵,λ为权衡两个任务的超参数。
40、在s4中,所述的后处理的具体过程为:后处理包括对解析结果的校正、格式化和优化,包括删除冗余数据、校正错误识别的实体、调整实体的排序或结构,以及转换为特定格式或标准以满足下游应用的需求,以解析结果的准确性和一致性,使其更加符合实际应用中的要求;所述的规则匹配是指应用预定义的规则来进一步验证和精确解析结果,该预定义规则基于特定的语言模式、地址格式、或者特定实体与行政区划之间的关系,通过逻辑和结构上的检查来提升解析结果的可靠性和精度。
41、本发明还涉及到一种基于深度学习的智能物流四级行政区划及实体地址识别系统,该识别系统包括行政区划地址处理模块、实体地址处理模块、多任务的bert编码器模块以及结果解析模块,还包括信息熵模块和动态loss权重调整机制模块实现多任务效果优化,其中,
42、所述行政区划地址处理模块,从数据库获得现有的业务数据,在已有的物流地址中获取分类标签数据,业务数据包含有已经解析好的物流地址,每个地址都经过人工或半自动标注了相应的行政区划分类标签,将准备好的行政区划标签数据与地址文本对应起来,形成第一个训练集;
43、所述实体地址处理模块,与第三方地址解析接口交互,从外部获取命名实体识别的地址标注数据,该标注数据已经进行了实体识别和命名实体标注,对其进行整理和转换,将整理好的地址标注数据与地址文本对应起来,形成另一个训练集;
44、所述多任务的bert编码器模块分别连接所述行政区划地址处理模块和所述实体地址处理模块,将第一训练集和第二训练集输入至多任务的bert编码器模块中得到地址文本的上下文向量表示,对行政区划地址进行分类任务,添加实体地址处理模块定义的实体标签,进行命名实体识别任务,准确识别出地址文本中各类实体的边界和类型;
45、所述结果解析模块连接所述多任务的bert编码器模块,负责解析多任务的bert编码器模块的输出结果,将识别出的行政区划地址和地址实体进行整合和解析,得到最终的地址解析结果;
46、所述信息熵模块连接至多任务的bert编码器模块,通过最小化总体的信息熵,即分类任务和命名实体识别任务的信息熵之和最小化来表示预测的不确定性越低;
47、所述动态loss权重调整机制连接至多任务的bert编码器模块,优化多任务学习中的loss函数,在训练过程中根据任务的难易程度和样本分布情况动态调整不同任务的loss权重,使模型更关注关键任务和难以识别的样本。
48、基于上述技术方案,本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法与现有技术相比,具有如下技术效果:
49、1.本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法提高地址解析准确性。通过引入多任务的bert编码器模块,系统能够同时处理行政区划地址和地址实体识别任务,从而在解析过程中更全面、准确地提取地址信息,降低解析错误率,提高地址解析的准确性。
50、2.本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法增强了对复杂地址的适应能力。系统中的动态loss权重调整和信息熵优化机制使得模型能够根据任务难度和样本分布动态调整权重,优化模型的泛化能力和鲁棒性。这样,系统能够更好地适应复杂、噪声较大的地址文本,提高对复杂地址的适应能力。
51、3.本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法能够实现精准实体识别。通过在命名实体识别数据中引入tf/idf算法进行筛选,系统能够筛选出更准确的实体信息,提高实体识别的准确性和可靠性,从而为物流行业提供更精准的地址信息和相关实体数据。
52、4.本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法能够实现高效处理大规模数据:bert编码器模块的并行处理能力和多任务学习的高效性,使得系统能够处理大规模的物流地址数据,实现高效率的地址解析和实体识别,满足物流行业在大数据应用场景下的需求。
53、5.本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法提升了系统智能化水平:多任务学习和信息熵优化等机制增强了系统的智能化水平,使其能够更好地理解地址文本的语义和结构,从而提高对复杂地址的处理能力,为物流行业提供智能化的地址信息处理服务。
54、6.本发明专利一种基于深度学习的智能物流四级行政区划及实体地址识别方法能够适应多样化业务需求:系统的模块化设计和灵活的数据标注方式使得其能够适应多样化的物流业务需求,根据不同行业和场景进行定制化开发,为不同物流企业提供个性化的解决方案。
55、7.本发明专利的技术效果还包括提高地址解析准确性、增强对复杂地址的适应能力、精准实体识别、高效处理大规模数据、提升系统智能化水平和适应多样化业务需求等,为物流行业提供更高效、智能化的地址信息处理服务,推动物流行业的数字化和智能化发展。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194661.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。