一种基于改进YOLOv5s的草莓果实识别方法
- 国知局
- 2024-07-31 22:49:19
本发明涉及计算机图像处理,具体为一种基于改进yolov5s的草莓果实识别方法。
背景技术:
1、yolov5x是yolov5系列中最大的模型之一。yolov5x通常会包含更多的网络层和参数,以提高模型的感知能力和准确性,从而在目标检测任务中更好地处理复杂场景和小目标。然而,这也意味着yolov5x的模型体积和计算复杂度通常会更大,需要更多的计算资源来训练和执行。
2、现有技术申请号为cn202310918241.3的发明涉及一种基于改进yolov5x的草莓果实检测方法,包括:草莓图像预处理,草莓图像采集;样本数据增强,对提取的多张图片进行缩放、裁切和色调调整,再通过mosaic混合方法来处理数据集;数据标注,使用开源图像标注工具labelimg进行标注,将图片中的草莓对象位置和草莓分类信息标记出来;根据sd-yolov5x(strawberrydetection-yolov5x)的网络模型对草莓数据集进行训练。其发明基于现有yolov5x模型的主干网络,引入了特征提取cch模块和nam注意力模块。
3、然而,在草莓识别的实际应用中,模型体积较大会对模型加载、部署和运行速度产生一定的影响,需要考虑到硬件资源和性能要求。当草莓识别技术需要在移动端应用时,现有技术的模型体积较大,考虑到智能设备的成本,从而移植至设备上存在一定困难,同时并不能保证移植至移动端后,依然保持出色的识别效果。
技术实现思路
1、针对现有技术的不足,本发明公开了一种基于改进yolov5s的草莓果实识别方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于改进yolov5s的草莓果实识别方法,包括以下步骤:
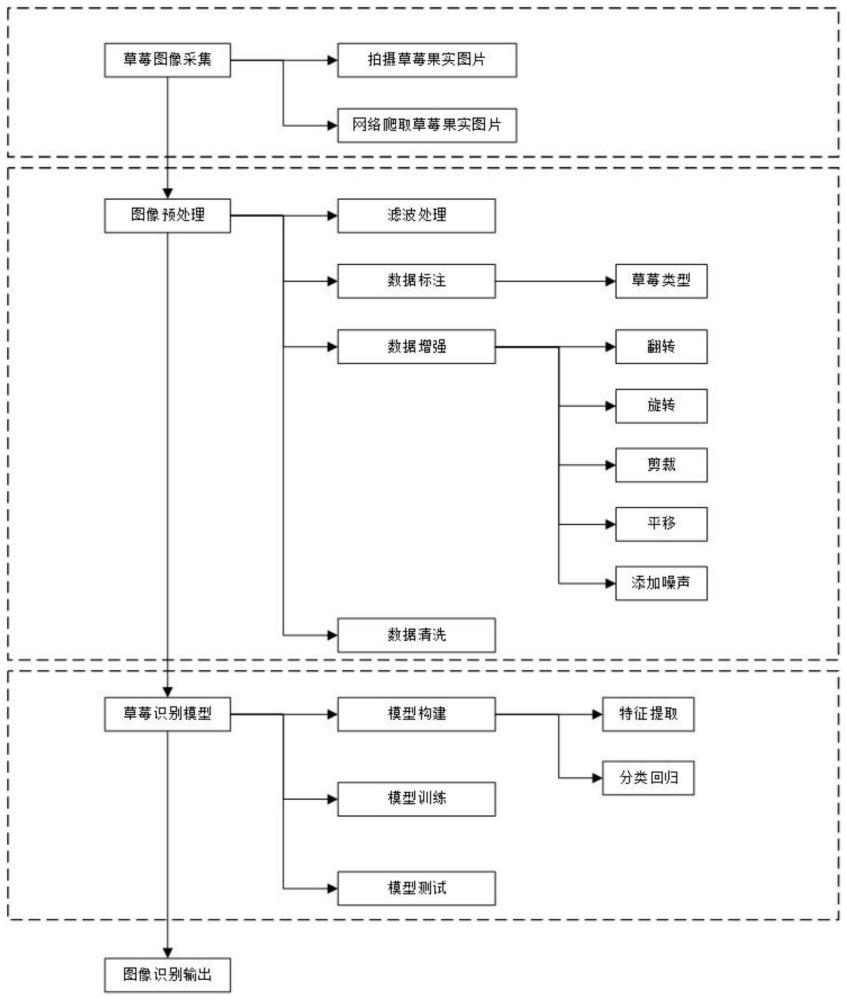
3、s1、通过相机对果实进行多角度拍摄,采集草莓图像,并使用计算机在网络上爬取草莓果实图片,并进行筛选处理,构建草莓数据集;
4、s2、对数据集进行预处理包括对数据集进行数据标注、数据增强和数据清洗,并划分为训练集、验证集和测试集,并划分为训练集、验证集和测试集;
5、s3、构建草莓识别模型,包括对原始的yolov5s模型进行改进得到mb-yolov5s模型,所述改进的mb-yolov5s模型包括:
6、1)以yolov5s为基础模型,将主干网络替换为改进的mobilenetv3网络,改进主要体现在bneck模块中,将原有的se注意力模块替换为eca注意力模块;
7、2)将颈部网络替换为改进的bifpn网络;改进包括在conv3模块和concat模块之间引入ca注意力模块,增强模型对重要特征通道的感知能力;
8、s4、使用数据集对mb-yolov5s进行模型训练;
9、s5、使用测试集对mb-yolov5s模型进行测试评估;
10、s6、将待识别的草莓果实图像输入到mb-yolov5s模型中进行识别输出。
11、优选的,步骤s1中构建草莓数据集步骤包括:
12、1)草莓图像采集,在草莓种植棚环境中使用相机从果实的正前方、左前方、右前方和上方进行拍摄,所拍摄的草莓果实图像包括无遮挡果实完全暴露、被枝叶或果实遮挡的不完全暴露两种类型;
13、2)使用计算机在网络上爬取草莓果实图片,并进行筛选处理。
14、优选的,步骤s2中数据集预处理步骤包括:
15、1)数据标注,每张图像包括使用开源图像标注工具labelimg进行标注,选择yolo标注格式,将图像中草莓的位置信息和分类信息标记出来;分类信息包括成熟草莓和未成熟草莓两类;
16、2)数据增强,从已标注好的原始草莓图像中筛选出可供目标检测的草莓图像,对图像进行数据增强,包括翻转、旋转、裁剪、平移和添加噪声,缓解过拟合问题,增加模型的泛化能力,提高模型在真实场景中的表现;
17、3)数据清洗,将增强后的图像进行识别、纠正和删除错误、不完整或者不准确的数据,确保数据的质量和可靠性,构建草莓数据集。
18、优选的,所述原始的yolov5s模型包括输入端、主干网络、颈部网络和输出端;
19、1)输入端包括mosaic数据增强、自适应图片缩放以及自适应锚框计算三部分组成,mosaic数据增强能够扩大小目标的数量,使得模型在小目标的检测上表现更好;
20、2)主干网络组成结构主要包括:
21、focus模块进行切片和拼接操作,提高在gpu上的运行速度;
22、cbs模块为标准卷积、批准归一化、silu激活函数的组合操作,再进行标准卷积的特征提取,接着进行批归一化,最后经过、silu激活函数处理,赋予cbs模块具有非线性表达能力,silu激活函数定义为公式为:
23、silu(x)=x·sigmoid(x)
24、yolov5-c3模块由三个conv模块(conv1、conv2、conv3)和一个bottleneck模块组成的;c3模块让特征图先通过两个分支,然后通过跨层结构将两部分合并,避免部分信息的丢失,使网络更深入,更有效进行提取特征;
25、*c3模块与c3模块的不同在于bottleneck是否有跳连的结构;
26、spp模块对输入特征进行三个池化操作,增加感受野,同时分离出最重要的上下文特征,去除冗余的信息;
27、3)颈部功能是进行不同大小特征图的特征融合,yolov5s一共采用三个尺度的信息在颈部进行融合,结合特征金字塔网络和金字塔注意力网络的结构,多次将不同特征图信息进行交融,为后续在检测头上检测工作做好前期准备;
28、4)输出端为检测的收尾阶段,通过将锚框机制与特征图数据的关联,生成具有目标类别、目标类别概率和目标预测框的输出矩阵;在训练时,预测框是在锚框的基础上调整,yolov5s检测头的输入为3个不同空间尺度的特征图,每个尺度中的一个网格产生3个预测框,对应不同目标大小,最终完成不同尺度的目标检测。
29、优选的,其中mobilenet v3的特征提取网络采用深度可分离卷积作为特征提取器,在保持模型轻量级的同时提供了相对较高的准确性,且使用bneck块结构,结合残差连接和轻量级卷积结构,用于提高模型的表达能力和准确性,其引入了自适应激活函数,动态地调整激活函数的参数,以适应不同的输入数据和任务;其中mobilenet v3的分类器使用se模块,自适应地调整特征图的通道权重,增强模型对特征的表示能力,同时引入“h-swish”的激活函数。
30、优选的,步骤s3对原始的yolov5s模型进行改进得到mb-yolov5s模型,模型改进步骤包括:
31、1)以yolov5s为基础模型,将主干网络替换为改进的mobilenetv3网络,改进主要体现在bneck模块中,将原有的se注意力模块替换为eca注意力模块,具体包括:
32、在h和w维度上对特征向量进行全局平均池化,得到1×1×c大小的特征向量记为zavg;然后zavg通过一维卷积层处理,输出跨通道且不降维的特征向量,并通过sigmoid激活函数归一化处理,从而得到权重系数矩阵weca;最后将输入向量x与权重系数weca相乘得到加权后的向量xeca;
33、2)将颈部网络替换为改进的bifpn网络;改进包括在conv3模块和concat模块之间引入ca注意力模块,增强模型对重要特征通道的感知能力,具体包括:
34、通过concat模块将不同来源或不同尺寸的特征图在通道维度上进行拼接;接着,通过一个conv3模块对融合后的特征图进行空间特征提取和卷积调整;在conv3模块之后,将特征图传入ca注意力模块;ca模块首先通过全局平均池化对特征图的空间维度进行压缩,然后通过一系列密集连接层学习不同通道之间的重要性权重;得到的通道注意力权重随后被用来对原特征图的每个通道进行加权;加权后的特征图再次通过激活函数处理,产生最终的、已经整合了通道注意力信息的特征图,用于后续的特征融合。
35、优选的,其中,bifpn表示一种目标检测任务中的特征融合网络,改进了传统的fpn,通过采用双向信息流动,允许特征在高层和低层之间双向传播,bifpn通过动态特征图调整自适应地选择输入特征图,并调整它们的权重,提高了网络的泛化能力。
36、优选的,步骤s4中使用数据集对mb-yolov5s进行模型训练,训练过程如下:
37、1)将数据集划分为三个独立子集,按照7:2:1的比例划分训练集、验证集和测试集;
38、2)配置训练超参数,输入图像分辨率为640,批处理大小为8,迭代次数为300轮次;
39、3)启动训练模型,使用训练集数据,在每次训练迭代中,计算损失并更新模型权重;
40、4)训练过程中,mb-yolov5s定期输出训练指标,包括损失值和精度指标,并在验证集上进行验证以获取模型的性能指标。
41、优选的,步骤s5中使用测试集对mb-yolov5s模型进行测试评估,模型测试评估过程如下:
42、训练完成后,模型自动会在验证集上评估模型性能,包括精确度、召回率和平均精度指标是用于评价目标检测模型性能的重要指标,以下为其的定义和计算公式:
43、1)精确度是衡量模型在其认为是正样本的预测中的可靠性,计算公式为:
44、
45、其中,tp代表模型正确预测的正样本的数量,fp代表模型错误预测为正样本的负样本的数量;
46、2)召回率衡量模型检测到所有真正正样本的能力,计算公式为:
47、
48、其中,tp代表模型正确预测的正样本的数量;fn代表模型未检测到的真实正样本的数量;
49、3)平均精确度用来计算整个数据集上模型性能的平均值;通过对每个类求平均精确度,然后计算所有类的ap值的平均值得到map,ap对于单个类别的计算公式简化为:
50、
51、其中,p(r)在不同召回率(r)下的最大精确度值;
52、若要获取map,计算每个类别的ap,然后求其平均值:
53、
54、其中,n是类别的数量,api是第i个类别的ap值;
55、且ap是根据precision-recall曲线计算的,该曲线是根据不同的置信度阈值得出的精确度和召回率,ap为该曲线下面积的大小。
56、优选的,所述map包括不同的iou阈值,以确定预测框和真实框之间的匹配程度;如map@0.5是指在iou阈值为0.5时计算的map,而map@0.5:0.95是指在从0.5到0.95的iou阈值以固定步长计算的map的平均值。
57、与现有技术相比,本发明的有益效果:
58、1、本发明中,mobile net v3网络中使用eca_bneck模块,并将改进后的mobilenet v3网络作为yolov5s的主干网络,使网络更加轻量化,对后续嵌入到移动端起到至关重要的作用;其中,eca-net模块是高效的通道注意力机制,可以增强网络对输入特征中重要信息的捕获能力;通过在bneck模块中加入eca-net,网络能够更加专注于对最终任务更为重要的特征,从而提高特征表达质量和准确度,以及模型的泛化能力;此外,eca-net以最小的计算复杂度和参数增量实现注意力,在训练和推理阶段都能显示出更快的速度。
59、2、本发明中,将注意力ca模块引入bifpn(双向特征金字塔网络)中,用于强化重要信息特征通道的关注,并将改进后的bifpn作为yolov5s的颈部网络;其中,ca模块主要关注通道维度上的重要特征,通过学习不同通道上的权重分配,强化对重要特征的关注并抑制不重要的特征,从而提高模型表达能力和性能;而bifpn使用加权双向特征融合策略,在bifpn的特定的特征融合后引入ca模块,对融合后的特征图进行通道注意力加权,实现更加有效的特征重标定和加权融合,增强模型对关键信息的捕捉能力。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194804.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种边端协同智能卸载方法
下一篇
返回列表