基于巨型内存页的边缘深度学习模型推理加速方法及装置
- 国知局
- 2024-07-31 22:51:52
本发明属于计算机边缘计算领域,具体涉及一种基于巨型内存页的边缘深度学习模型推理加速方法及装置。
背景技术:
1、近年来,计算能力的快速提升推动了深度学习(dl)在诸如计算机视觉、自然语言处理和语音识别等各个领域的显著成功。dl作为机器学习的子领域,引入了许多尖端技术。尽管传统的云计算一直是dl任务的首选,但在边缘设备上部署模型的需求变得日益紧迫。与延迟、隐私和对网络连接的依赖性有关的问题加剧了这种紧迫感。边缘设备受到功耗、尺寸的限制,通常使用中央处理器(cpu)进行计算,并且受到内存资源的限制。因此,优化模型的部署以符合边缘设备的资源限制变得至关重要。推理涉及将经过训练的模型应用于新数据。这个过程涵盖了众多数值计算,计算复杂性和内存使用取决于模型的参数和输入数据。对于推理,高效地执行这些计算并尽快提供准确的预测至关重要。
2、模型优化是推理加速的常用手段,其中模型优化主要包括了剪枝,量化和蒸馏等方法。剪枝是指通过去除神经网络中不重要的连接或节点来减少模型参数数量和计算量。这种方法可以显著减小模型大小,从而提高推理速度。量化则是将神经网络参数从浮点数转换为低精度的整数表示,减少了存储空间和计算需求。常见的量化方式有固定点数量化和二值化。而蒸馏通过将一个复杂模型的知识(教师模型)传递给一个小型模型(学生模型),使学生模型学习到教师模型的知识,从而减小模型大小并提高推理速度。然而,这些方法主要侧重于与特定应用紧密相关的高级优化。简而言之,这些优化技术是针对特定模型和应用程序量身定制的,这可能会限制它们在切换到不同模型时的有效性。
3、模型推理过程中涉及大量的内存访问,不同于gpu显存,cpu平台上的内存通常是由操作系统来管理,因此用户访问内存的过程可能会涉及到频繁的系统调用和虚拟地址转换过程。过多的系统调用会显著妨碍处理器性能。此外,当应用程序的数据大小超出了快表(tlb)的覆盖范围时,会导致额外的等待时间来处理tlb未命中。这种延迟导致cpu空闲时间增加,计算效率降低。虽然传统的内存池可以缓解系统调用的问题,但它们不经意间引入了过多的峰值内存使用。此外,管理内存池通常涉及复杂的代码,增加了代码的复杂性和维护开销。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种基于巨型内存页的边缘深度学习模型推理加速方法及装置,本发明旨在减少快表tlb未命中并避免频繁的系统调用,实现边缘深度学习模型推理过程中的内存访问加速。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种基于巨型内存页的边缘深度学习模型推理加速方法,包括:
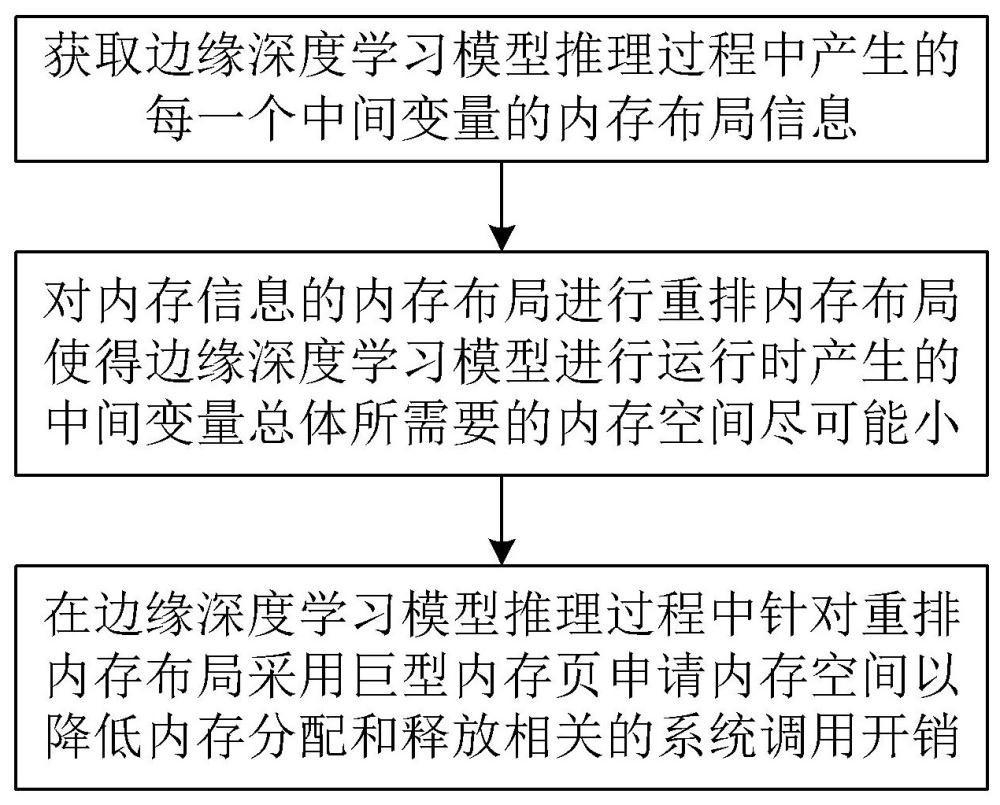
4、步骤s1,获取边缘深度学习模型推理过程中产生的每一个中间变量的内存布局信息;
5、步骤s2,对内存信息的内存布局进行重排内存布局使得边缘深度学习模型进行运行时产生的中间变量总体所需要的内存空间尽可能小;
6、步骤s3,在边缘深度学习模型推理过程中针对重排内存布局采用巨型内存页申请内存空间以降低内存分配和释放相关的系统调用开销。
7、可选地,步骤s1中获取边缘深度学习模型推理过程中产生的中间变量的内存信息包括:监测边缘深度学习模型推理过程中的申请或者释放内存的操作,根据申请或者释放内存识别为对应中间变量的创建和销毁动作,从而根据中间变量的创建和销毁动作记录每一个中间变量的内存布局信息。
8、可选地,所述根据中间变量的创建和销毁动作记录每一个中间变量的内存布局信息包括:在中间变量创建时读取当前创建操作的顺序及所需的内存大小,在中间变量销毁时读取销毁操作的顺序,且通过一个初始值为0的全局变量来记录创建和销毁操作的顺序,当且仅当中间变量被创建或者是销毁时该全局变量的值才会改变,从而得到每一个中间变量的内存布局信息。
9、可选地,所述中间变量的内存布局信息包括中间变量的生命周期、中间变量的内存的偏移量和占用内存空间大小,所述偏移量为中间变量的内存起始地址。
10、可选地,步骤s2包括:
11、s2.1,将中间变量按照生命周期降序排序;
12、s2.2,在排序后的中间变量中选择最左下的偏移量;
13、s2.3,在排序后的中间变量中遍历选择一个中间变量作为当前中间变量;
14、s2.4,判断当前中间变量能否放置在所选偏移量,若能放置在所选偏移量则跳转步骤s2.5;否则,跳转步骤s2.3以继续选择中间变量;
15、s2.5,结合当前中间变量的占用内存空间大小在所选偏移量放置当前中间变量的内存块;
16、s2.6,在排序后的中间变量中抬高偏移量以选择新的偏移量;
17、s2.7,判断排序后的中间变量是否已经全部放置,若排序后的中间变量已经全部放置则跳转步骤s3;否则跳转步骤s2.2。
18、可选地,步骤s3包括:
19、s3.1,根据得到的重排内存布局确定总体内存占用的大小;
20、s3.2,向操作系统申请等于总体内存占用的大小的巨型内存页;
21、s3.3,在边缘深度学习模型推理过程中监测中间变量申请内存空间,若检测到中间变量申请内存空间则跳转步骤s3.4;
22、s3.4,根据得到的重排内存布局确定重排内存布局后该中间变量的地址偏移量;
23、s3.5,根据重排内存布局后中间变量的地址偏移量分配对应内存空间给该中间变量;
24、s3.6,判断边缘深度学习模型的推理任务是否结束,若结束则跳转步骤s3.7;否则,跳转步骤s3.7;否则跳转步骤s3.3;
25、s3.7,释放巨型内存页,结束并退出。
26、此外,本发明还提供一种基于巨型内存页的边缘深度学习模型推理加速装置,包括:
27、采样器程序模块,用于获取边缘深度学习模型推理过程中产生的每一个中间变量的内存布局信息;
28、规划器程序模块,用于对内存信息的内存布局进行重排内存布局使得边缘深度学习模型进行运行时产生的中间变量总体所需要的内存空间尽可能小;
29、分配器程序模块,用于在边缘深度学习模型推理过程中针对重排内存布局采用巨型内存页申请内存空间以降低内存分配和释放相关的系统调用开销。
30、此外,本发明还提供一种基于巨型内存页的边缘深度学习模型推理加速装置,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述基于巨型内存页的边缘深度学习模型推理加速方法。
31、此外,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行所述基于巨型内存页的边缘深度学习模型推理加速方法。
32、此外,本发明还提供一种计算机程序产品,所述计算机程序产品中包含计算机指令,所述计算机指令用于被微处理器编程或配置以执行所述基于巨型内存页的边缘深度学习模型推理加速方法。
33、和现有技术相比,本发明主要具有下述优点:为了减少边缘深度学习模型在推理过程中因快表tlb未命中并避免频繁的系统调用的问题,本发明提供了一种通用的主机内存优化方法,本发明基于深度学习框架来管理中间变量的内存使用,具体而言首先通过运行时采样来获取内存使用的详细信息,然后从操作系统请求巨型内存页来自己管理,同时减少了系统调用和tlb未命中的次数,从而能够实现边缘深度学习模型推理过程中的内存访问加速。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195048.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表