一种基于半监督和对比学习的肺部疾病分类方法及系统
- 国知局
- 2024-07-31 22:54:13
本发明涉及医疗影像分析,是一种应用于缺少人类专家预测场景下基于半监督和对比学习的人机交互学习方法及系统,尤其是面向肺部疾病的分类。
背景技术:
1、尽管医学影像技术迅速发展,传统的胸部放射影像学仍然是诊断肺部疾病不可或缺的工具,例如,绝大多数针对结核病检测的研究基于胸部x射线(cxr)图像进行。人工智能技术上的突破使得医生可以利用深度学习技术辅助肺部疾病诊断,近年来,一些学者提出有必要让人类参与到模型的决策过程中,这主要有两个方面的原因。一方面,在医疗、金融等一些风险较高的场景中,如果完全使用模型代替人类专家进行分析和预测,可能会因为模型的误差带来很大的风险[leitão, d., saleiro, p., figueiredo, m.a., &bizarro, p. (2022). human-ai collaboration in decision-making: beyondlearning to defer. arxiv, abs/2206.13202.],这在实际应用中是不被允许的。另一方面,人类和人工智能模型理解和代表真实世界的方式有根本性的不同。并且不同于人工智能模型,人类能够利用人工智能无法掌握的信息从少数的样本中快速学习。因此综合以上两方面看,更加理想的系统既不是单独的人工智能系统,也不是单独的人类专家,而是由两者来合作完成,利用两者的互补优势将对决策过程带来最大化的帮助。
2、决策中的人机交互[punzi, c., pellungrini, r., setzu, m., giannotti,f., & pedreschi, d. (2024). ai, meet human: learning paradigms for hybriddecision making systems. arxiv, abs/2402.06287.]旨在创造协同效应人类决策者和人工智能系统之间的合作,人工智能系统和一个或多个人类专家组成一个团队,共同完成预测任务。已有的人机交互方法可以分为三类范式:监督、延迟和合作。监督是三者中最简单的一种,其中人与机器之间不存在集成,而是人类专家对后者的预测进行监督,即模型的预测和人类的监督分为两个阶段。由于人类能够感知到模型预测阶段的结果,并且也能够修正它,因此人类专家能实现最大限度的自主性。延迟只允许两个步骤中的一个发生,即要么是人类进行预测,要么是模型进行预测。其中,选择人类或者模型的步骤是由一个额外的模型(拒绝模型)指导的。与前面的监督方法不同,人类和模型将独立完成各自的预测过程,最终采用哪个预测结果则只由拒绝模型决定。合作则在人类和模型之间建立一个更复杂的环路,以迭代的方式在两者中进行协同。与以往的范式不同,在合作协同范式中人类和模型的预测结果会交互式地互相修正,以得到最终的预测结果。
3、传统的人机交互系统通常是合作式的,需要有专家和模型同时对数据进行分析,这样的交互过程时间长,并且对专家标注数量的要求很高。在医学领域,获取放射科医生对图像的标注非常耗时,并且患者数据的处理也存在隐私性等敏感问题,因此在大规模的影像数据集上难以获得完整的人类标注。
4、然而,现有的人机交互学习方法通常需要每个样本上都有对应的人类标注,例如raghu[raghu, m., blumer, k., corrado, g.s., kleinberg, j.m., obermeyer, z., &mullainathan, s. (2019). the algorithmic automation problem: prediction,triage, and human effort. arxiv, abs/1903.12220.]提出的基于置信度的算法需要先在每个用例上对比人类专家和模型的预测精确度,再选择置信度更高的预测作为系统的预测结果,但这在实际的临床场景中难以实现。医疗目前已有的人机交互方法大多数没有考虑到这个问题,多使用了完整的专家标签。一些学者[charusaie, m., mozannar, h.,sontag, d.a., & samadi, s. (2022). sample efficient learning of predictorsthat complement humans. international conference on machine learning.]提出基于主动学习的系统迭代地更新数据,先给出少量的专家预测训练模型,再逐渐加入更多的专家预测对模型进行修正,即让模型动态地参与到专家预测的过程中;另一些工作[hemmer, p., thede, l., vossing, m., jakubik, j., & kuhl, n. (2023). learningto defer with limited expert predictions. arxiv, abs/2304.07306.]则提出使用已有的半监督方法将专家预测进行补全,一定程度上规避了这一问题。但是,这样没有充分利用图像中的深层语义信息,直接使用离散的伪标签也提高了引入脏标签的概率,即不可靠的伪标签会降低整体训练集的数据质量。
技术实现思路
1、为了解决现有技术存在的不足,本发明的目的是提出一种基于半监督和对比学习的肺部疾病分类方法及系统。
2、本发明针对现有技术仅适用于人类专家预测没有缺失、不能在有限数据上充分使用协同学习算法的不足,在mozannar等人[mozannar, h., & sontag, d.a. (2020).consistent estimators for learning to defer to an expert. internationalconference on machine learning.]工作(d2l算法)的基础上,提出了一种基于半监督和对比学习的肺部疾病分类系统(doe算法),能够在人机交互系统中缺少专家标注场景下根据少量专家分类结果自动学习专家的预测能力,扩展之前的人机交互方法。另外,本发明还在raghu等人[raghu, m., blumer, k., corrado, g.s., kleinberg, j.m., obermeyer,z., & mullainathan, s. (2019). the algorithmic automation problem:prediction, triage, and human effort. arxiv, abs/1903.12220.]工作的基础上,结合comatch[li, j., xiong, c., & hoi, s.c. (2020). comatch: semi-supervisedlearning with contrastive graph regularization. 2021 ieee/cvf internationalconference on computer vision (iccv), 9455-9464.]的工作,引入半监督学习和对比学习技术提升已有协同学习算法的性能。
3、本发明通过引入输入图像的深层特征表示和专家预测两个层面的相似程度作为正则信息来指导模拟专家预测模块的训练,这使得本发明可以更好地学习专家的预测能力,提升人类专家预测不足时已有人机交互系统的性能,具有较强的泛化能力。
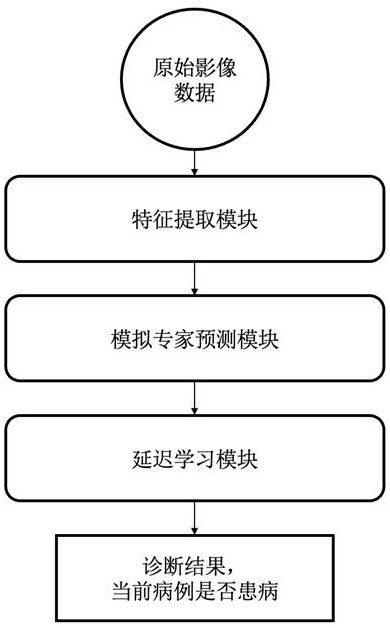
4、本发明提出的一种基于半监督和对比学习的肺部疾病分类方法,所述方法具体包括以下步骤:
5、步骤1:使用的数据集包括三个组成部分:影像数据x、真实标签y和一位人类专家的预测结果d;其中,影像数据通过医用的专业设备获取,真实标签由多位权威的医生协商得到,人类专家的预测结果则由某位医生阅片后给出;数据集中的每个影像数据都有对应的真实标签,但不一定有人类专家的预测结果;所述数据集由ds和du构成,ds中包含影像x对应的人类专家预测结果,表示为,du中不包含对应的人类专家预测结果,表示为,角标i表示不同实例在数据集中的序号,即ds中各个实例的序号表示为从1到s,du中各个实例的序号表示为从1到u;将所述数据集按4∶1的比例随机划分为训练集和测试集;训练数据集由du的部分数据和ds构成,测试数据则为du中剩余的数据;
6、初始化特征提取模块的编码器和分类网络,以及模拟专家预测模块中的专家预测网络;
7、步骤2:训练特征提取模块的编码器和分类网络;将训练集上的每张肺部影像数据x输入到所述编码器中,得到深层的特征表示z;再将z输入分类网络,输出预测的类别标签,取1或0,表示当前病例是否患病;
8、步骤3:固定步骤2特征提取模块中编码器的参数,将训练集上每张图像依次输入所述编码器和所述专家预测网络;并且,提取出所述专家预测网络最后一个全连接层前的向量作为专家预测的隐表示向量,然后基于半监督方法和对比学习设计目标函数,训练模拟专家预测模块的专家预测网络;模拟专家预测模块的专家预测网络输出生成的人类专家预测结果,取1或0,表示当前病例是否患病;
9、步骤4:固定步骤1中的所述编码器和步骤3中的所述专家预测网络的参数,将测试集上的图像依次输入所述编码器和所述专家预测网络,得到生成的人类专家预测结果;
10、步骤5:集成已有的延迟学习方法,使用步骤4生成的人类专家预测填充延迟学习方法中缺失的人类专家预测,训练延迟学习方法;所述延迟学习方法同时训练一个分配函数和一个分类模型,对于每个实例,分类模型给出模型的预测结果,分配函数则选择人类专家预测和分类模型的预测结果中置信度高的作为最终的输出,输出标签为1或0,表示当前实例是否患病。
11、进一步,步骤2中所述的训练特征提取模块的编码器和分类网络,具体过程是,计算输入图像对应的真实标签和特征提取模块输出的预测类别的损失,训练特征提取模块的编码器和分类网络;其中,len为编码器输出特征向量的维度,表示输入实例的序号,表示交叉熵损失;所述的编码器采用残差神经网络resnet作为骨干结构,从肺部的x光影像中学习出512维的深层的特征表示z,再连接一个全连接层输出预测的类别结果,表示是否患病。
12、进一步,步骤3中所述训练模拟专家预测模块的专家预测网络,具体包括:
13、首先,对专家预测结果d进行预处理,对于多分类问题,只需关注专家是否做出和真实标签一致的预测,而不用关注专家具体做出哪种预测;因此,对于多分类问题中人类专家的预测结果,按对标签进行二值化;其中表示指示函数,表示二值化处理后的专家预测结果;如果多分类任务中生成的人类专家预测和真实标签一致,就取1,否则取0,将多分类问题转化为二分类问题;
14、然后,设计本发明的目标函数,采用半监督学习和对比学习相结合,其中半监督损失由三个部分组成,表示为:
15、,
16、在有专家预测的数据集ds(包含s个样本)上计算第一个损失项;在缺少专家预测的数据集du(包含u个样本)上计算后两个损失项;
17、第一个损失项首先对原始图像施加弱数据增强、依次经过特征提取模块中编码器和专家预测网络预测得到的类别,计算与二值化后真实的人类专家预测标签之间的交叉熵损失h,其中数据增强方法用于提高模型的泛化性;第二个损失项首先在影像数据上使用强数据增强方法,增强后的数据依次经过编码器和专家预测网络得到专家预测结果,并筛选置信度超过阈值的、置信度最高的预测结果作为伪标签,然后计算和专家预测结果的交叉熵;第三个损失项基于图网络,以每张输入图像作为节点、模型预测得到的伪标签之间的相似度作为边,建立一张伪标签图,同理建立一张特征表示的图,计算两张图的相似度作为正则项;此外,本发明设计专家对比损失,通过对特征表示和专家预测的隐表示向量分别建立图和、计算两张图的余弦相似度,鼓励专家预测网络对深层信息相似的输入图像提取出相似的信息,具体表示为;整体目标函数表示为半监督损失和对比损失的加权和,,其中为专家对比损失的权重。
18、一种实现上述所述方法的系统,所述系统包括:特征提取模块、模拟专家预测模块和延迟学习模块;其中,
19、所述特征提取模块,从图像中提取出特征表示向量;
20、所述模拟专家预测模块,基于特征表示向量,被训练从少量专家预测数据中学习专家的预测能力;
21、所述延迟学习模块,在生成的专家预测结果上应用延迟学习算法以实现人类专家和模型之间的互补,提高人机交互学习系统的系统准确度。
22、所述模拟专家预测模块进一步可以分为:模拟专家训练单元和生成专家预测单元,其中:模拟专家训练单元中的模型基于特征提取模块中学习到的隐含信息,从少部分的真实专家预测标签中学习专家能力;生成专家预测单元使用训练好的模拟专家对缺少标注的数据生成专家预测。
23、本发明的有益效果
24、本发明使用具有强大特征提取能力的神经网络,把肺部影像数据转化为特征表示,通过增加模拟专家预测模块,从少量专家预测中学习人类专家的预测能力,对已有的协同学习方法进行扩展。而且已有半监督学习方法的基础上,集成对比损失实现对专家预测的一致性约束,提高方法对专家能力的学习能力;基于生成的更准确的专家预测,可以有效提高已有协同学习方法的性能。与基线方法相比,本发明对专家能力学习的准确率带来了平均15.1%的提升;在每个类别上仅有两条专家标注数据时,本发明对已有协同学习方法准确度的提升达3.2%。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195246.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。