民事案件判决预测模型产品及方法
- 国知局
- 2024-07-31 23:02:05
本发明属于法律与人工智能、自然语言处理相关,更具体地,涉及一种民事案件判决预测模型产品及方法。
背景技术:
1、智慧司法旨在依托大数据、人工智能与自然语言处理等技术深度分析运用司法数据,提高司法效能,降低管理成本。判决预测是智慧司法中的一项重要任务,它可以帮助法律专业人士更加准确地评估案件的胜败可能性,理解案件的法律问题和风险,为律师、法官和当事人提供决策参考,优化法律服务和资源分配,提高司法审判效率。
2、民事案件涉及的法律条款、事实情况、当事人诉求等往往更加复杂多样,导致案件数据难以提取和分析,因此,民事案件判决预测的研究相对较少。而在目前,民事案件裁判文书的数量比刑事案件裁判文书的数量高一个量级,因此民事案件判决预测亟待进行深入研究。面对海量的民事案件,需要大量具备专业知识的审判人员依照相关法律条文和全面的案件信息做出案件判决,人力物力成本消耗巨大。
3、因此,如何设计一种能够涵盖多种案由并且具有高度可靠性的民事案件判决预测方法,成为本领域的技术难题。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种民事案件判决预测模型产品及方法,其目的在于解决民事案件判决结果预测问题。
2、为实现上述目的,按照本发明的一个方面,提供了一种民事案件判决预测模型程序产品,包括:
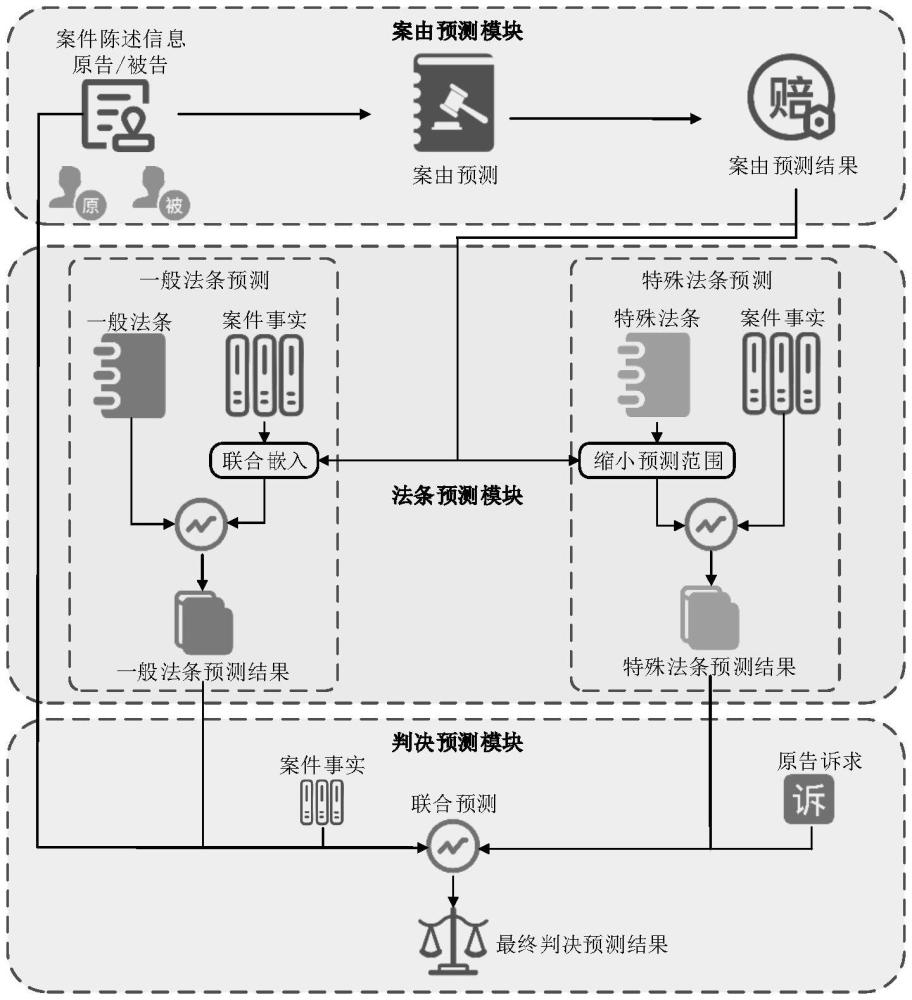
3、案由预测模型,用于对原、被告陈述生成案件三元组与案件争论点,将各案件三元组关联起来形成案情图谱,对案情图谱中的实体、关系和所述案件争论点分别进行编码,获取其嵌入表示;还用于基于所述实体、关系的嵌入表示,使用图神经网络聚合并提炼案情图谱的信息特征,依据该信息特征和所述案件争论点的嵌入表示输入第一mlp进行案由预测;
4、法条预测模型,用于对案由预测模型预测的案由、案件事实与案件领域对应的一般法条/特殊法条编码后,输入第二mlp/第三mlp预测案件适用的一般法条/特殊法条;
5、判决预测模型,用于分析案件事实与原告诉求的关联,提取与原告诉求关联的关键事实;还用于对案件多角度法律要素进行编码,得到其嵌入表示,所述案件多角度法律要素包括法条预测模型得到的一般法条预测结果、特殊法条预测结果、原告诉求、案件事实、关键事实、原告陈述、被告陈述;还用于使用注意力机制将所有法律要素特征融合为整体民事案件特征表示,并使用第四mlp进行判决结果分类,完成判决预测。
6、优选地,所述案由预测模型包括第一特征增强层、第一编码层、特征学习层和案由预测层,其中,
7、所述第一特征增强层用于对输入的原、被告陈述使用大语言模型生成案件三元组与案件争论点;所述案件三元组指头实体-关系-尾实体三元组;
8、所述第一编码层用于将各案件三元组关联起来形成案情图谱,使用法律领域预训练模型对案情图谱中的实体、关系和所述案件争论点分别进行编码,获取其嵌入表示;
9、所述特征学习层用于基于实体、关系的嵌入表示,使用图神经网络聚合并提炼案情图谱的信息特征,获取案情图谱的深度特征表示;
10、所述案由预测层用于以案件争论点的嵌入表示与案情图谱的深度特征表示作为输入,采用拼接池化的方式融合特征信息,使用第一mlp学习融合特征信息并进行案由预测结果分类,完成案由预测。
11、优选地,所述法条预测模型包括第二编码层和法条预测层,其中,
12、所述第二编码层用于采用法律领域预训练语言模型对案由预测模型预测的案由、案件事实与案件领域对应的一般法条、特殊法条编码,得到其嵌入表示;
13、所述法条预测层用于将一般法条的嵌入表示、案件事实的嵌入表示,可选加入预测案由的嵌入表示输入第二mlp,第二mlp从中学习法律要素与一般法条之间的关联,输出第一预测向量,以一般法条的嵌入表示和第一预测向量的余弦相似度作为标准,预测案件适用的一般法条;还用于将特殊法条的嵌入表示、案件事实的嵌入表示,可选加入预测案由的嵌入表示输入第三mlp,第三mlp从中学习法律要素与特殊法条之间的关联,输出第二预测向量,以特殊法条的嵌入表示和第二预测向量的余弦相似度作为标准,预测案件适用的特殊法条。
14、优选地,所述判决预测模型包括第二特征增强层、第三编码层、特征融合层和判决预测层,其中,
15、所述第二特征增强层用于使用大语言模型分析案件事实与原告诉求的关联,提取与原告诉求关联的关键事实,以增强诉求相关性的特征识别;
16、所述第三编码层用于采用法律领域预训练语言模型对案件多角度法律要素进行编码,得到其嵌入表示;
17、所述特征融合层用于使用层次注意力与自注意力结合的形式为不同角度法律要素嵌入表示特征分配权重,将所有法律要素特征融合为整体民事案件特征表示;
18、所述判决预测层用于使用第四mlp在整体民事案件特征表示的基础上进行判决结果分类,完成判决预测。
19、优选地,第一编码层通过对案情图谱中的实体、关系编码得到的原告陈述特征fc、被告陈述特征fd直接在第三编码层复用;第二编码层对案件事实、一般法条、特殊法条编码得到的案件事实特征ff、一般法条预测特征fglap与特殊法条预测特征fslap直接在第三编码层复用;
20、所述第三编码层编码时,给定原告诉求文本序列sp、案件关键事实文本序列sef,将二者拼接为单个法律要素spf进行编码,通过标识符“原告诉求:”、“关键事实:”对文本序列加以区分:
21、fpf=encoder(spf+ppf)
22、其中,ppf表示原告诉求及关键事实拼接文本序列的位置信息,编码得到诉求事实整合特征fpf;
23、所述特征融合层先分别对fc和fd、fglap和fslap进行低层次注意力融合得到fcd、fgs,再对fcd与案件事实特征ff进行中层次注意力融合得到fcdf,最后对fpf、fgs与fcdf采用自注意力机制进行融合,从而将所有法律要素特征融合为整体民事案件特征表示。
24、优选地,特征学习层中,图注意力网络中的每一个图注意力层都以实体嵌入矩阵关系嵌入矩阵和保存节点邻居关系的邻接矩阵作为输入,节点即实体;实体嵌入矩阵me中第i行为实体ei的嵌入,ne是实体的总数,t是每个实体嵌入的特征维数;关系嵌入矩阵mr中第j行是关系rj的嵌入,nr是关系的总数,p是每个关系嵌入的特征维数;最终图注意力层的输出结果为和上一图注意力层的输出作为下一图注意力层的输入;
25、由实体ei、ej与关系rn拼接而成的三元组表示为通过对三元组中实体与关系的特征向量进行线性变换学习得到三元组的特征向量,形式如下:
26、
27、其中,是三元组的特征向量表示,分别为实体ei、ej和关系rn的特征向量表示,w1表示拟合三元组特征向量的权重矩阵;
28、使用αijn表示三元组的绝对权重系数,
29、
30、其中,w2为权重矩阵,leakyrelu(*)为非线性激活函数;
31、包含实体ei的每个三元组的相对权重系数γijn为:
32、
33、其中,ni表示实体ei的所有邻居节点,ri表示实体ei相连的关系集合,αikr表示实体ei、ek和关系rr三元组的绝对权重系数,softmax(*)为激活函数;
34、利用相对权重系数,图注意力层将实体ei的特征向量表示更新为按照相对权重系数加权的三元组特征表示之和:
35、
36、其中,σ(·)表示softmax函数;
37、大语言模型输出的所有三元组经法律领域预训练语言模型编码后,其中所有关系的特征向量表示构成关系嵌入矩阵mr;关系ri的新特征表示由关系嵌入矩阵mr线性变换后得到,线性变换的权重参数矩阵为t′为图注意力层输出的关系特征向量维数,变换过程如下所示:
38、m′r=mrwr
39、其中,m′r为变换得到的关系的新特征表示的关系嵌入矩阵;
40、在图注意网络的最后一层输出层,引入多头注意力机制来稳定深度学习过程;多头注意力机制是分别计算m个注意力头也即图注意力网络中m条独立路径上最后一层图注意力层的结果,然后将它们直接拼接起来,得到实体ei的嵌入表示
41、
42、其中,是第m个注意力头计算出的实体ei、ej和关系rn三元组的相对权重系数,是第m个注意力头中的实体ei、ej和关系rn三元组的特征向量,中关系的特征向量是m′r中对应关系ri的关系特征表示元素;
43、使用权重矩阵对me进行线性变换得到mt,mt表示转换后的实体嵌入矩阵,te表示初始实体特征向量维度,t′表示图注意网络输出的实体特征向量维度;之后将mt添加到图注意力层输出的实体特征矩阵m′e当中,得到最终的输出实体特征:
44、mt=weme
45、me″=me′+mt
46、利用最终的输出实体特征,对案情图谱中的核心实体及关系进行平均聚合,得到案情图谱的深度特征表示fg。
47、按照本发明的另一方面,还提供了一种民事案件判决预测模型构建方法:
48、采用带有案由标签的原、被告陈述数据集,对上述的案由预测模型进行训练;
49、采用带有一般法条标签/特殊法条标签的包括案由、案件事实和一般法条/特殊法条的数据集,对上述的法条预测模型进行训练;
50、采用判决结果标签的包含原、被告陈述、原告诉求、案件事实、一般法条、特殊法条的案件多角度法律要素数据集,对上述的判决预测模型进行训练;得到训练好的民事案件判决预测模型。
51、优选地,采用交叉熵函数对案由预测模型进行训练;
52、采用带有一般法条标签的数据集对法条预测模型进行训练时,采用第一损失函数如下:
53、
54、
55、其中,对于一般法条ai,其特征向量为一般法条特征矩阵fga中第i行元素cosine是余弦相似度函数,为第二mlp的预测向量,simi是与之间的相似度,ηglap为设定的适用一般法条的相似度阈值,labelglap为案件的适用一般法条标签,αglap、βglap和γglap均为模型训练前设置的超参数,loss是计算的损失;
56、采用带有特殊法条标签的数据集对法条预测模型进行训练时,采用第二损失函数如下:
57、
58、
59、其中,对于特殊法条aj,其特征向量为特殊法条特征矩阵fsa中第j行元素为第三mlp的预测向量,simj是与之间的相似度,ηslap为设定的适用特殊法条的相似度阈值,labelslap为案件适用的特殊法条标签,αslap、βslap和γslap均为模型训练前设置的超参数,loss*是计算的损失。
60、按照本发明的另一方面,还提供了一种民事案件判决预测方法,将原、被告陈述输入上述民事案件判决预测模型构建方法中训练好的案由预测模型,输出预测的案由;
61、将该预测的案由、案件事实与案件领域对应的一般法条/特殊法条输入上述民事案件判决预测模型构建方法中训练好的法条预测模型,输出预测的案件适用的一般法条和特殊法条;
62、将预测的一般法条和特殊法条、原告诉求、案件事实、关键事实、原告陈述、被告陈述,输入上述民事案件判决预测模型构建方法中训练好的判决预测模型,输出针对该原告诉求的判决预测结果;当具有多条原告诉求时,使用该训练好的判决预测模型分多次预测分别得到每条原告诉求对应的判决预测结果。
63、按照本发明的另一方面,还提供了一种计算机可读存储介质,包括存储的计算机程序,所述计算机程序被处理器执行时,控制所述计算机可读存储介质所在设备执行上述的民事案件判决预测模型构建方法,和/或,上述的民事案件判决预测方法。
64、总体而言,通过本发明所构思的以上技术方案与现有技术相比,本发明提供的方案主要具有以下有益效果:
65、1.本发明提出的民事案件判决预测模型包括案由预测模型、法条预测模型与判决预测模型三个部分,其中,案由预测部分通过案件当事人的陈述确定案由,遵循相应逻辑对原被告陈述进行特征提取,做出案由预测,案由预测结果为法条选择提供精准参考,缩小法条预测范围;法条预测部分,将民事案件中的一般法条与特殊法条分开,利用案由与案件事实的交互特征进行预测,而法条预测结果为最终的判决预测提供关键法律依据,提升判决预测的准确性与可解释性;最后,判决预测部分对裁判文书中原被告陈述、案件事实及原告诉求进行特征提取,结合法条预测结果做出判决预测。
66、2.本发明提出的民事案件判决预测模型,在案由预测模型部分,充分利用大语言模型在文本理解处理方面的先进能力,通过大语言模型从原告陈述和被告辩护中提取关键信息,使用图神经网络对这些信息进行深度融合,获取准确的案由特征进行案由预测。
67、第一特征增强层对大语言模型进行指令微调规范其对话格式,以原被告陈述作为输入,使用大语言模型生成案情关键三元组与案件争论点。这一过程能够显著提升案由预测部分对案件陈述核心要素的理解和捕捉能力,使案由预测部分能够更加细致高效地对关键信息进行文本嵌入与特征学习,提升其性能和预测准确度。
68、第一编码层将案件三元组关联在一起形成案情图谱,使用司法领域预训练语言模型对案情图谱中的实体、关系与前述案件争论点分别进行编码,分别获取其特征向量。
69、特征学习层使用图神经网络聚合并提炼案情图谱的信息特征,获取案情图谱的深度特征表示。通过这种高效的特征聚合过程,图神经网络能够有效地捕捉案情图谱中实体间的复杂关系和交互,为案由预测部分揭示更为丰富和细致的案件语义层次,加强模型对案件本质的理解能力,从而提升案由预测的准确度与可靠性。
70、案由预测层以案件争论点的文本嵌入表示与案情图谱的特征表示作为输入,采用拼接池化的方式融合特征信息,使用多层感知机(mlp)学习融合特征信息并进行案由预测结果分类,完成案由预测。
71、3.本发明提出的民事案件判决预测模型,在法条预测模型部分,利用预训练语言模型捕获案件事实和法律条文间的丰富语义关系,通过在损失函数中引入文本相似度阈值,提高模型区分正负样本的能力。
72、第二编码层采用法律领域预训练语言模型编码案由、案件事实与对应法律条文,得到它们的特征向量。这一过程利用了法律领域预训练语言模型深厚的语言理解能力,捕捉文本中的细微语义差异和法律概念的丰富联系。通过学习这些深入特征,模型能够更准确地分析案件内容和法律条文之间的相关性,极大地增强了法条预测的准确度。
73、法条预测层以案由(可选)及案件事实的嵌入表示为输入,使用多层感知机(mlp)学习法律要素与法条之间的关联,输出维度相同的预测向量,以法条嵌入表示和预测向量的余弦相似度作为标准,预测案件适用法条。
74、4.法条预测模型中,对编码出的民事案由与案件事实特征向量进行拼接池化,池化操作能够融合民事案由与案件事实间的边缘信息,突出案件中的重要特征,减少特征维度并增强模型的泛化能力;将案由文本与案件事实描述文本编码后得到的特征向量作为最终特征输入到多层感知机(mlp)中,得到一般法条预测部分的预测向量。
75、5.本发明提出的民事案件判决预测模型,在判决预测模型部分,通过结合层次注意力机制和自注意力机制,有效融合多角度法律要素,显著提升了判决预测任务的准确度。
76、6.本发明提出的民事案件判决预测模型建立方法中,分别对案由预测模型、用于一般法条/特殊法条预测的法条预测模型、判决预测模型进行训练,得到训练好的民事案件判决预测模型,该训练好的民事案件判决预测模型全面利用多角度法律要素,可对不同种类案由案件进行准确判决预测。
77、第二特征增强层使用大语言模型分析案件事实与原告诉求的关联,提取与当前原告诉求关联的案件事实文本,以增强诉求相关性的特征识别。
78、第三编码层采用司法领域预训练语言模型编码案件多角度法律要素,得到它们的特征向量。
79、特征融合层使用层次注意力与自注意力结合的形式为不同法律要素特征分配权重,将所有法律要素特征融合为整体民事案件特征表示。这种方式允许模型在理解单个法律要素特征的同时整合这些要素,构建出一个反映民事案件整体本质的综合特征表示。
80、判决预测层使用多层感知机(mlp)在整体民事案件特征表示的基础上进行判决结果分类,做出最终判决预测。
81、7、本发明提出的民事案件判决预测模型建立方法中,训练过程中,模型将一般法条预测出的特征向量与一般法条特征向量进行余弦相似度计算,得到预测向量与法条特征向量间的相似度,设定一般适用法条匹配的相似度阈值。再根据上述计算结果与训练参数设计一般法条预测部分的损失函数。对于可预测范围内的所有法条,模型均依据相似度计算损失,并进行反向传播。因此,模型能够对可预测范围内所有法条的特征进行学习。最终模型输出的相似度超过阈值的法条,作为一般法条预测的结果。
82、8.本发明提出的民事案件判决预测方法,利用训练好的民事案件判决预测模型可对不同种类案由案件进行准确判决预测,有效融合多角度法律要素,显著提升了判决预测任务的准确度。
83、9、本发明提出的民事案件判决预测方法,由于单个民事案件通常包含多个原告诉求,诉求的数量也因案件而异。因此对于包含n个原告诉求的案件,判决预测模型会针对每个原告诉求进行特征提取与判决预测,最终模型可以得到同个案件中n个不同原告诉求的预测结果。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195704.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表