一种数据同步方法、装置、电子设备和存储介质与流程
- 国知局
- 2024-07-31 23:02:13
本技术涉及数据处理,特别是涉及一种数据同步方法、装置、电子设备和存储介质。
背景技术:
1、在数据同步任务中,hbase(非关系型分布式数据库)一般是重要的目标源,例如将数据从其它数据库同步到hbase,是常见的需求。在将数据同步到hbase的过程中,通常通过hbase的put操作实现数据的写入,其中,所述put操作用于向指定的hbase表中插入一行数据或更新已存在的行数据。然而,每一条put操作所操作的数据有限,无法实现批量数据的同步。
2、现有技术中,通常使用importtsv工具(hbase提供的一个命令行工具)来进行批量数据的同步。但是importtsv工具无法正确处理作为字段分隔符的转义字符,例如,importtsv工具有时会将转义字符识别为普通字符,以及当设定指定字符为分隔字符时,将数据中作为普通字符的指定字符识别为分隔字符,因此,现有的批量同步方法存在影响数据同步的准确性和完整性的情况。
3、因此,如何实现在数据批量同步时兼顾数据同步的准确性和完整性,成为亟需解决的问题。
技术实现思路
1、本技术实施例的目的在于提供一种数据同步方法、装置、电子设备和存储介质,以实现在数据批量同步时兼顾数据同步的准确性和完整性。具体技术方案如下:
2、第一方面,本技术提供了一种数据同步方法,应用于数据同步工具,所述方法包括:
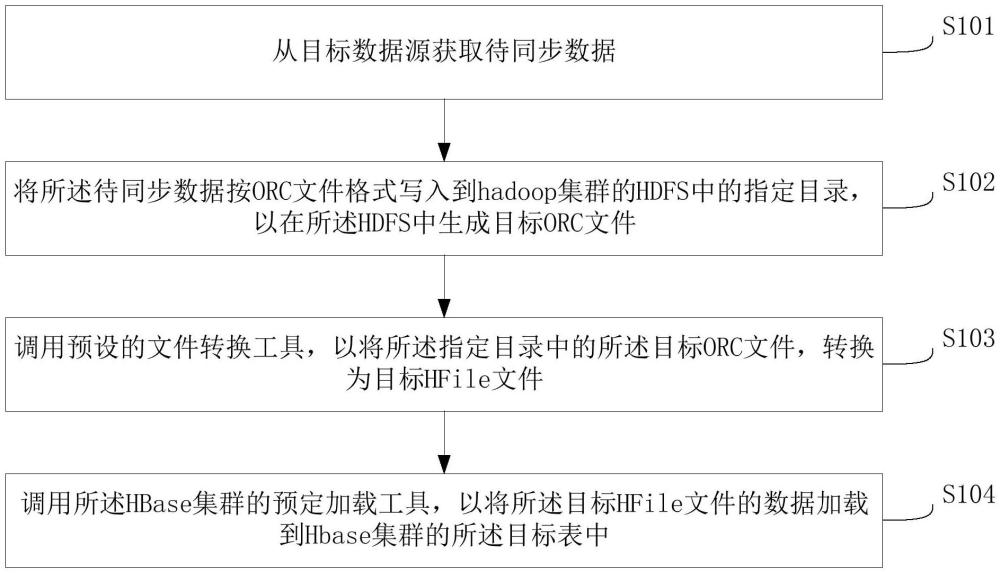
3、从目标数据源获取待同步数据;
4、将所述待同步数据按orc文件格式写入到hadoop集群的hdfs中的指定目录,以在所述hdfs中生成目标orc文件;
5、调用预设的文件转换工具,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件;其中,所述目标hfile文件中存储有所述待同步数据,且所述目标hfile文件中所包括的字段与目标表中的字段相同,所述目标表为预先确定的在hbase集群中用于同步所述待同步数据的数据表;
6、调用所述hbase集群的预定加载工具,以将所述目标hfile文件的数据加载到hbase集群的所述目标表中。
7、可选的,所述调用预设的文件转换工具,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件之前,所述方法还包括:
8、获取用户输入的命令行参数;其中,所述命令行参数的参数内容包括所述指定目录中的所述目标orc文件的文件路径、目标存储地址、所述目标表的表名以及所述目标orc文件的字段信息;所述目标存储地址表征所述目标hfile文件在所述hdfs上存放的地址;
9、所述调用预设的文件转换工具,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件,包括:
10、调用预设的文件转换工具,以解析所述命令行参数,得到所述参数内容,基于所述参数内容,配置mapreduce作业,并将所述mapreduce作业提交至hadoop集群,以使得所述hadoop集群中的预设数据转换模块执行所述mapreduce作业,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件;
11、其中,所述mapreduce作业的作业参数包括所述文件路径、所述目标存储地址、所述目标表的表名以及所述目标orc文件的字段信息;
12、所述预设数据转换模块执行所述mapreduce作业的过程包括:
13、基于所述文件路径,从所述hdfs的所述指定目录中读取所述目标orc文件,并解析所读取到的所述目标orc文件,得到所述目标orc文件中的每一行数据;
14、基于目标映射关系,确定所述目标orc文件中的每一行数据对应的目标行数据,并基于各条目标行数据,生成目标hfile文件并存储于所述目标存储地址;所述目标映射关系为依据所述目标orc文件的数据结构和所述目标表的数据结构,确定的所述目标orc文件的各字段和各指定字段的映射关系;所述目标orc文件的数据结构和各字段为基于所述目标orc文件的字段信息确定出的;各指定字段为基于所述表名所确定出的目标表中的各字段;所述目标表的数据结构为基于所述表名所确定出的;
15、其中,每一行数据对应的目标行数据为按照所述目标映射关系将该行数据的各字段的字段值,映射到相应指定字段后所得到的、用于写入所述目标表的行数据。
16、可选的,其中,各指定字段中包括所述目标表中的行键,以及,所述目标表中的除所述行键以外的其他各字段,所述行键用于唯一标识目标表中的行数据;
17、所述将所述待同步数据按orc文件格式写入到hadoop集群的hdfs中的指定目录,以在所述hdfs中生成目标orc文件包括:
18、针对所述待同步数据中的每一行数据,基于所述目标表的行键规则,生成该行数据对应的行键的键值;
19、将每一行数据对应的行键的键值和所述待同步数据,以orc文件格式写入到hadoop集群的hdfs中的指定目录,以在所述hdfs中生成目标orc文件。
20、可选的,其中,各指定字段包括所述目标表的除行健以外的各个字段,所述行键用于唯一标识目标表中的行数据;
21、所述预设数据转换模块解析所读取到的所述目标orc文件,得到所述目标orc文件中的每一行数据后,
22、针对所述目标orc文件中的每一行数据,基于所述目标表的行键规则,生成该行数据对应的行键的键值;
23、所述基于目标映射关系,确定所述目标orc文件中的每一行数据对应的目标行数据包括:
24、基于目标映射关系,将所述目标orc文件中的每一行数据的各字段的字段值,映射到相应指定字段,得到每一行数据对应的映射结果;
25、基于每一行数据对应的映射结果和每一行数据对应的行键的键值,生成每一行数据对应的目标行数据。
26、可选的,所述调用所述hbase集群的预定加载工具,以将所述目标hfile文件的数据加载到hbase集群的所述目标表中包括:
27、调用所述hbase集群的预定加载工具,以基于所述目标表的分区规则,确定所述目标hfile文件中各行数据对应的至少一个目标区域,针对每一目标区域,将所述目标hfile文件发送到所述hbase集群中该目标区域对应的目标服务器,以使所述目标服务器将所述目标hfile文件中对应于该目标区域的各个行数据,加载到该目标区域中;
28、其中,所述分区规则定义了行键与所述目标区域的对应关系,每一目标分区负责存储所述目标表中的一部分数据。
29、可选的,在调用所述hbase集群的预定加载工具,以将所述目标hfile文件的数据加载到hbase集群的所述目标表中之后,所述方法还包括:
30、向hdfs发送第一删除指令,以将所述hdfs中存储的所述目标orc文件删除;
31、和/或,
32、向hbase集群发送第二删除指令,以将所述hbase集群中存储的所述hfile文件删除。
33、第二方面,本技术提供了一种数据同步装置,应用于数据同步工具,所述装置包括:
34、第一获取模块,用于从目标数据源获取待同步数据;
35、写入模块,用于将所述待同步数据按orc文件格式写入到hadoop集群的hdfs中的指定目录,以在所述hdfs中生成目标orc文件;
36、转换模块,用于调用预设的文件转换工具,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件;其中,所述目标hfile文件中存储有所述待同步数据,且所述目标hfile文件中所包括的字段与目标表中的字段相同,所述目标表为预先确定的在hbase集群中用于同步所述待同步数据的数据表;
37、加载模块,用于调用所述hbase集群的预定加载工具,以将所述目标hfile文件的数据加载到hbase集群的所述目标表中。
38、可选的,所述装置还包括:
39、第二获取模块,用于在调用预设的文件转换工具,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件之前,获取用户输入的命令行参数;其中,所述命令行参数的参数内容包括所述指定目录中的所述目标orc文件的文件路径、目标存储地址、所述目标表的表名以及所述目标orc文件的字段信息;所述目标存储地址表征所述目标hfile文件在所述hdfs上存放的地址;
40、所述转换模块,包括:
41、转换单元,用于调用预设的文件转换工具,以解析所述命令行参数,得到所述参数内容,基于所述参数内容,配置mapreduce作业,并将所述mapreduce作业提交至hadoop集群,以使得所述hadoop集群中的预设数据转换模块执行所述mapreduce作业,以将所述指定目录中的所述目标orc文件,转换为目标hfile文件;
42、其中,所述mapreduce作业的作业参数包括所述文件路径、所述目标存储地址、所述目标表的表名以及所述目标orc文件的字段信息;
43、所述预设数据转换模块执行所述mapreduce作业的过程包括:
44、基于所述文件路径,从所述hdfs的所述指定目录中读取所述目标orc文件,并解析所读取到的所述目标orc文件,得到所述目标orc文件中的每一行数据;
45、基于目标映射关系,确定所述目标orc文件中的每一行数据对应的目标行数据,并基于各条目标行数据,生成目标hfile文件并存储于所述目标存储地址;所述目标映射关系为依据所述目标orc文件的数据结构和所述目标表的数据结构,确定的所述目标orc文件的各字段和各指定字段的映射关系;所述目标orc文件的数据结构和各字段为基于所述目标orc文件的字段信息确定出的;各指定字段为基于所述表名所确定出的目标表中的各字段;所述目标表的数据结构为基于所述表名所确定出的其中,每一行数据对应的目标行数据为按照所述目标映射关系将该行数据的各字段的字段值,映射到相应指定字段后所得到的、用于写入所述目标表的行数据。
46、可选的,其中,各指定字段中包括所述目标表中的行健,以及,所述目标表中的除所述行键以外的其他各字段,所述行键用于唯一标识目标表中的行数据;
47、所述写入模块包括:
48、生成单元,用于针对所述待同步数据中的每一行数据,基于所述目标表的行键规则,生成该行数据对应的行键的键值;
49、写入单元,用于将每一行数据对应的行键的键值和所述待同步数据,以orc文件格式写入到hadoop集群的hdfs中的指定目录,以在所述hdfs中生成目标orc文件。
50、可选的,其中,各指定字段包括所述目标表的除行健以外的各个字段,所述行键用于唯一标识目标表中的行数据;
51、所述预设数据转换模块解析所读取到的所述目标orc文件,得到所述目标orc文件中的每一行数据后,
52、针对所述目标orc文件中的每一行数据,基于所述目标表的行键规则,生成该行数据对应的行键的键值;
53、所述基于目标映射关系,确定所述目标orc文件中的每一行数据对应的目标行数据包括:
54、基于目标映射关系,将所述目标orc文件中的每一行数据的各字段的字段值,映射到相应指定字段,得到每一行数据对应的映射结果;
55、基于每一行数据对应的映射结果和每一行数据对应的行键的键值,生成每一行数据对应的目标行数据。
56、可选的,所述加载模块包括:
57、发送单元,用于调用所述hbase集群的预定加载工具,以基于所述目标表的分区规则,确定所述目标hfile文件中各行数据对应的至少一个目标区域,针对每一目标区域,将所述目标hfile文件发送到所述hbase集群中该目标区域对应的目标服务器,以使所述目标服务器将所述目标hfile文件中对应于该目标区域的各个行数据,加载到该目标区域中;
58、其中,所述分区规则定义了行键与所述目标区域的对应关系,每一目标分区负责存储所述目标表中的一部分数据。
59、可选的,所述装置还包括:
60、删除模块,用于在调用所述hbase集群的预定加载工具,以将所述目标hfile文件的数据加载到hbase集群的所述目标表中之后
61、向hdfs发送第一删除指令,以将所述hdfs中存储的所述目标orc文件删除;
62、和/或,
63、向hbase集群发送第二删除指令,以将所述hbase集群中存储的所述hfile文件删除。
64、第三方面,本技术提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
65、存储器,用于存放计算机程序;
66、处理器,用于执行存储器上所存放的程序时,实现上述任一所述的数据同步方法。
67、第四方面,本技术提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述任一所述的数据同步方法。
68、本技术实施例还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述任一所述的数据同步方法。
69、本技术实施例有益效果:
70、本技术实施例提供了一种数据同步方法,通过使用orc文件格式,本方法可以准确处理数据中的转义符和分隔符,有效避免了传统文本格式因分隔符冲突导致的数据解析错误,确保数据的结构完整性,将orc文件转换为hbase的原生存储格式hfile进一步提高了与hbase集群的适配性,因为hfile文件作为hbase集群中原生的内部存储格式,与hbase集群的适配度高,从而hbase集群可以高效的同步目标hfile文件中的数据,无需进行额外的数据转换。因此,本技术的方案可以在数据批量同步时兼顾数据同步的准确性和完整性。此外,在本技术的方案中,orc格式的文件的生成和目标hfile文件的生成过程是计算资源耗费较多的过程,但这个两个过程都无需使用hbase集群的计算资源,因此,本技术的方案在进行大批量数据的同步到hbase集群中时,可以减少对hbase集群的影响,并保持hbase集群的稳定性和可用性。
71、当然,实施本技术的任一产品或方法并不一定需要同时达到以上所述的所有优点。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195719.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表