一种基于对抗对比学习鲁棒的产品联邦推荐方法
- 国知局
- 2024-07-31 23:06:03
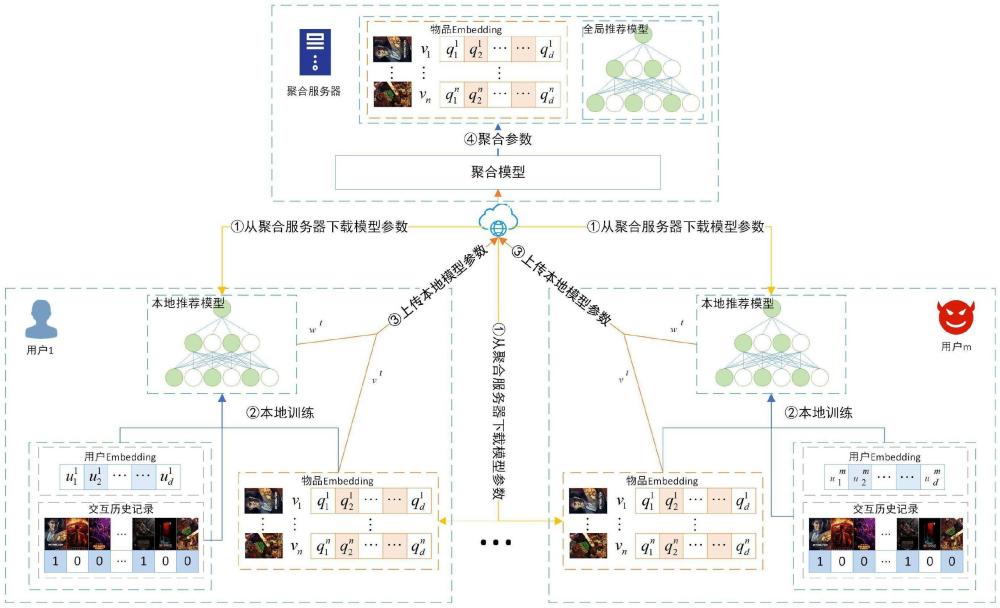
本发明属于推荐系统的安全领域,具体的说是一种基于对抗对比学习鲁棒的产品联邦推荐方法。
背景技术:
1、近十年来,个性化推荐系统已经用于各种领域,在信息过载的时代,为用户浏览自己感兴趣的物品带来便利。现在,大多数的推荐系统都需要收集用户的基本数据和历史行为(例如购买记录、点击、观看等行为数据)等数据,并且把它们集中起来训练个性化的推荐系统。但是,随着用户对个人数据的隐私越来越重视,部分用户禁止平台获取自己的隐私信息,平台想要获取用户的数据变得越来越困难。目前法律明确规定了收集个人信息需要公开透明、处理个人信息未经允许均属于不合法行为,数据的获取也越来越严格,因此没有用户的数据很难对用户的偏好进行建模,也无法训练个性化的推荐系统。最近,由谷歌提出的联邦学习能够在不收集用户数据的情况下训练推荐系统,联邦学习是一个分布式的训练系统,它在保护用户的隐私方面具有很好的潜力。
2、目前,有许多的研究能够证明联邦学习能够应用于推荐系统的训练,并且能够媲美与集中训练的推荐系统的性能。联邦推荐由于其训练的分布式特性,导致其训练过程以及模型参数在用户面前是完全透明的。换句话说,对于恶意用户来说是白盒的模型,恶意用户可以通过控制本地推荐系统的训练数据、训练方式、模型参数和梯度,来精心设计有毒的参数或梯度上传到聚合服务器,导致聚合后的全局模型出现偏差,从而降低推荐系统的性能。根据恶意用户的目的不同主要有两种不同的攻击,分别为目标攻击和无目标攻击。前者指被恶意用户攻击后全局模型会提高或降低恶意用户所期望的物品的曝光率,在现实生活中主要可能用于恶意商家的竞争,提高自己或降低竞争者物品的曝光率。而后者是以降低推荐系统的全体性能为目的,主要由竞争的平台等为了降低竞争平台的推荐服务体验,从而自己获益,所以无目标攻击的危害具有十分严重的影响,因此研究联邦推荐面对无目标攻击时的鲁棒性具有重要意义。
3、目前关于推荐系统鲁棒性的研究都是针对中心化的推荐系统,而针对联邦推荐的鲁棒性研究去很少。此外,由于联邦学习导致推荐系统在恶意用户面前是一个白盒模型,恶意用户的攻击和以往的中心化推荐系统攻击方式也有所不同。所以中心化推荐系统的鲁棒方法也很难有效。不仅在联邦推荐系统如此,在联邦学习的其他任务上也有相同的情况。到目前为止,已经有许多的学者在联邦分类的场景提出了许多的鲁棒方法,其中针对无目标攻击的主要有基于几何的krum、trimmed-mean等方法,但这些方法主要针对独立同分布的数据,由于每个人的偏好都有所不同,而联邦推荐的数据是高度非独立同分布的数据,而且这方法都是主要运行在聚合服务器上。针对上述背景及技术,亟需一种能有效提升联邦推荐投毒攻击时的防御能力,同时不影响推荐精度的解决方案。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出一种基于对抗对比学习鲁棒的产品联邦推荐方法,以期能够提高推荐模型参数分布的稳定性,增强推荐模型的鲁棒性,且能够提高推荐模型对决策边界样本的处理能力,从而能进一步提升推荐模型在复杂场景下的产品推荐性能。
2、本发明为达到上述发明目的,采用如下技术方案:
3、本发明一种基于对抗对比学习鲁棒的产品联邦推荐方法的特点在于,是按如下步骤进行:
4、步骤1、假设有n个客户端构成的客户端集合u以及m个物构成的物品集合r,第u个客户端在本地拥有的物品交互记录集记为并作为第u个客户端的正样本集,其中,是第u个客户端拥有的物品集合;表示第u个客户端交互的第f个物品,并令的标签为“1”,令mu表示第u个客户端的正样本集中物品交互记录个数,mu<m;
5、第u个客户端从r中采样一个物品交互记录集并作为第u个客户端的负样本集,其中,表示第u个客户端交互的第g个物品;并令的标签为“0”;令m'u表示第u个客户端的负样本集中物品交互记录个数;
6、将作为第u个客户端的样本集;
7、步骤2、初始化一个d维向量pu作为第u个客户端的嵌入;
8、对第u个客户端的样本集ru中的第i个物品进行嵌入,得到第i个物品的表征向量qi,从而得到m×d维的物品嵌入矩阵i;
9、步骤3、所述神经协同过滤推荐模型ncf对第u个客户端的嵌入pu和第i个物品的表征向量qi进行处理,得到第u个客户端对第i个物品的预测值
10、步骤4、对第u个客户端的样本集ru中每个物品的预测值进行降序排列,并选取前mu个预测值所对应的物品中属于负样本集合的物品构成筛选后的负对抗样本集合其中,表示第u个客户端的第g'个负对抗样本;
11、选取后m'u个预测值所对应的物品中属于正样本集合的物品构成筛选后的正样本集合其中,表示第u个客户端的第f'个正对抗样本;
12、由和构成作为第u个客户端的对抗样本;
13、步骤5、构建神经协同过滤推荐模型ncf对第u个客户端的总损失函数lu;
14、步骤6、从u中随机选择γ%的客户端构成客户端训练集所述客户端训练集中的每个训练客户端按照步骤1-步骤2的过程进行处理,得到每个训练客户端的输入数据;
15、步骤7、所述输入数据输入所述神经协同过滤推荐模型ncf中进行一次训练,得到每个训练客户端在一次训练下的模型参数并发送给服务器;
16、步骤8、所述服务器利用式(9)对每个训练客户端一次训练下的模型参数进行聚合,得到一次训练下的聚合后的参数w:
17、
18、式(9)中,wu'表示第u'个训练客户端的模型参数;
19、步骤9:所述服务器将参数w发送给每个训练客户端后,用于更新自身的神经协同过滤推荐模型ncf,从而按照步骤7的过程对更新后的神经协同过滤推荐模型ncf进行训练,并按照步骤8的过程对模型参数聚合,直至模型收敛为止,从而得到最优聚合参数所对应的神经协同过滤推荐模型,用于实现对任一客户端的产品推荐。
20、本发明所述的基于对抗对比学习鲁棒的产品联邦推荐方法的特点也在于,所述步骤3包括:
21、所述神经协同过滤推荐模型ncf包括:两个并行的mlp模块和gmf模块、预测层;
22、步骤3.1、所述mlp模块利用式(1)得到第u个客户端的第i个物品在隐藏层的输出
23、
24、式(1)中,φ表示l层串联的线性神经网络;
25、步骤3.2、所述gmf模块利用式(2)得到第u个客户端的第i个物品的逐元素乘积向量
26、
27、式(2)中,表示向量的逐元素乘积;
28、步骤3.3、所述预测层利用式(3)得到第u个客户端对第i个物品的预测值从而得到第u个客户端的样本集ru中每个物品的预测值并构成预测向量
29、
30、式(3)中,φo表示单层的线性神经网络,softmax表示激活函数;表示向量的逐元素拼接。
31、所述步骤5包括:
32、步骤5.1、利用式(4)构建第u个客户端的推荐损失
33、
34、式(4)中,yu,i表示第u个客户端的第i个物品的样本标签;
35、步骤5.2、利用式(5)构建第u个客户端的正对抗样本的对比损失
36、
37、式(5)中,为分类正确的正样本集合中的第个物品;
38、步骤5.3、利用式(6)构建第u个客户端的负对抗样本的对比损失
39、
40、式(6)中,为分类正确的正样本集合中的第个物品;
41、步骤5.4、构建对抗样本的总对比损失
42、步骤5.5、利用式(7)构建第u个客户端的参数的约束损失
43、
44、式(7)中,和var(i)表示i的均值和方差,||i||为i的二范数;
45、步骤5.4、利用式(8)构建第u个客户端的总损失lu:
46、
47、式(8)中,α和β是两个超参数。
48、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述产品联邦推荐方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
49、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述产品联邦推荐方法的步骤。
50、与现有技术相比,本发明的有益效果在于:
51、1.本发明提出的一种基于对抗对比学习鲁棒的产品联邦推荐方法,利用对抗样本进行对比学习的方法,能够增强硬样本的鲁棒性,同时对物品的embedding进行了约束限制,增强了参数的鲁棒性,能够针对多种无目标攻击提升的鲁棒性,从而提高了产品推荐的推荐性能。
52、2.本发明不同于前人提出的方法都运行在服务端,本发明提出方法完全运行在客户端的防御方法,能够减轻聚合服务器的负担提高运行效率。
53、3.本发明不仅适合ncf模型,而且适合所有使用用户-物品embedding建模的推荐方法,并且提出的方法与前人提出运行在服务器端的防御方法相互兼容,两者互相结合使用能够达到更好的防御效果。
54、4.本发明通过联邦推荐的鲁棒性安全的研究,有助于提升推荐系统的安全性,对提升个性化推荐系统服务质量与用户体验有一定的现实意义,同时能够帮助研究人员设计更加安全有效的相关推荐系统。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195944.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表