一种云数据库集群在线副本调度方法和系统
- 国知局
- 2024-07-31 23:12:59
本发明属于云数据库,更具体地,涉及一种云数据库集群在线副本调度方法和系统。
背景技术:
1、云数据库服务提供商,如腾讯、亚马逊、微软、谷歌和阿里巴巴等,在提供优质服务的同时希望运营成本可控,实现可持续发展。达成该目标的一个重要方面就是云数据库集群中基于在线副本调度的负载均衡策略。如果数据副本位置分布不合理,云数据库集群中常常会出现节点资源使用不均衡的现象,这在极端情况下会造成节点负载过高,从而影响服务质量。因此需要制定合理的副本调度策略。多租户云数据库集群的在线数据副本调度策略需要达到效果好、实时性强、成本低的要求,才能真正应用于复杂多变的实际场景,持续优化服务质量。
2、现有的云数据库集群在线调度方法通常是基于时间序列预测技术来预测集群中的各类负载,并根据预测结果进行事先调度,其中时间序列预测技术主要包括两大类:基于统计学算法的预测方法以及基于机器学习算法的预测方法;其中,基于统计学算法的预测方法应用最广泛,如移动平均法、指数平滑法等,其主要是使用简单的迭代公式进行预测;基于机器学习算法的预测方法,如随机森林、集成学习等,其主要是根据大量历史数据训练模型,并使用模型进行预测。
3、然而,现有基于上述两种预测技术的云数据库集群在线调度方法均存在一些不可忽略的缺陷:
4、第一,现有基于统计学算法预测的云数据库集群在线调度方法容易低估负载,从而无法有效避免过载;
5、第二,现有基于机器学习算法预测的云数据库集群在线调度方法训练代价大,模型的泛化性不强;
6、第三,现有基于统计学算法预测和机器学习算法预测的云数据库集群在线调度方法对云原生多租户数据库集群场景的适配度不高,无法充分利用负载周期性突发的特点,导致预测召回率不够,调度效果不佳。
7、第四,现有基于统计学算法预测和机器学习算法预测的云数据库集群在线调度方法主要关注数据库实例的放置或迁移,调度代价较高,且速度较慢,实时性不足。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种云数据库集群在线副本调度方法,其目的在于,解决现有基于统计学算法预测的云数据库集群在线调度方法容易低估负载,从而无法有效避免过载的技术问题,以及现有基于机器学习算法预测的云数据库集群在线调度方法训练代价大,模型的泛化性不强的技术问题,以及现有基于统计学算法预测和机器学习算法预测的云数据库集群在线调度方法对云原生多租户数据库集群场景的适配度不高,无法充分利用负载周期性突发的特点,导致预测召回率不够,调度效果不佳的技术问题,以及现有基于统计学算法预测和机器学习算法预测的云数据库集群在线调度方法主要关注数据库实例的放置或迁移,调度代价较高,且速度较慢,实时性不足的技术问题。
2、为实现上述目的,按照本发明的一个方面,提供了一种云数据库集群在线副本调度方法,包括以下步骤:
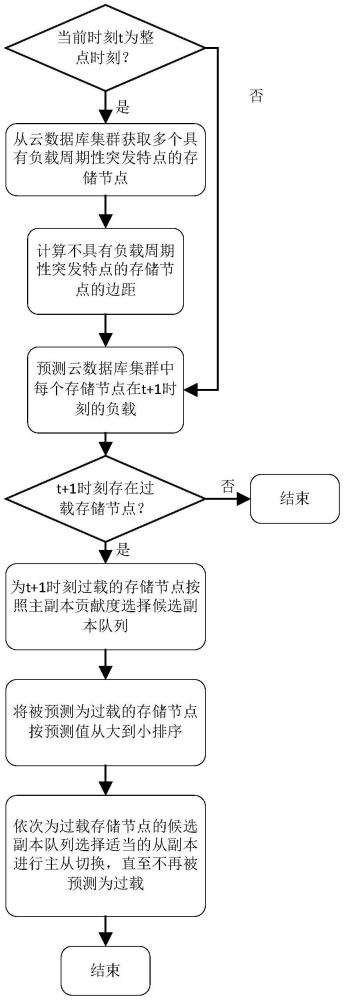
3、(1)判断当前时刻t是否为整点时刻(例如0时或12时),如果是,则转入步骤(2),否则转入步骤(4)。
4、(2)从云数据库集群中获取多个具有负载周期性突发特点的存储节点。
5、(3)对于云数据库集群的所有存储节点中除了步骤(2)获取的具有负载周期性突发特点的存储节点以外的每个存储节点pn而言,计算该存储节点pn在过去12个小时的负载数据的一阶差分序列的90分位数作为后续预测的边距:
6、(4)对于云数据库集群中的每个存储节点p而言,根据其在过去30分钟内的负载数据预测该存储节点p在t+1时刻的负载
7、(5)根据步骤(4)得到的每个存储节点p在t+1时刻的负载预测值设置集合o为所有t+1时刻负载预测值大于过载阈值的存储节点构成的集合,并判断集合o是否为空,如果是,则过程结束,否则转入步骤(6);
8、(6)针对步骤(5)得到的集合o中的每个存储节点pi∈o而言,选择其存储的主副本集合中贡献度排名前r位的多个主副本作为存储节点pi的候选副本队列
9、(7)根据步骤(4)得到的每个存储节点p在t+1时刻的负载预测值和步骤(5)得到的集合o,将集合o中的所有存储节点按照步骤(4)得到的这些所有存储节点在t+1时刻的负载预测值进行降序排列,从而得到存储节点队列p。
10、(8)对于步骤(7)得到的存储节点队列p中的每个存储节点pm而言,为其对应的候选副本队列中的主副本选择合适的从副本进行主从角色切换,直至pm在t+1时刻负载的预测值小于过载阈值为止。
11、优选地,步骤(2)具体为,首先,对于云数据库集群中的每个存储节点p而言,从监控系统中获取该存储节点p在过去12个小时以分钟为粒度的负载数据
12、然后,对负载数据loadp进行stl分解,从而得到如下形式的负载数据loadp:
13、loadp=sp+tp+rp
14、其中sp、tp、rp分别为存储节点p的季节项、趋势-周期项和残差项;
15、最后,对存储节点p的季节项sp进行快速傅里叶变换,若变换结果表明季节项具有明显的周期,且季节项在每个周期内的最大值与均值的比值均超过给定阈值,则表示该存储节点p是具有负载周期性突发特点的存储节点;
16、优选地,步骤(3)是采用以下公式:
17、
18、其中percentile(a,b)表示集合a的b分位数。
19、优选地,步骤(4)是对于步骤(2)得到的每个具有负载周期性突发特点的存储节点py而言,预测该存储节点py在t+1时刻的负载对于云数据库集群的所有存储节点中除了步骤(2)获取的具有负载周期性突发特点的存储节点以外的每个存储节点pn而言,预测该存储节点pn在t+1时刻的负载
20、优选地,步骤(4)包括以下子步骤:
21、(4-1)从监控系统获取每个存储节点p过去30分钟的负载数据
22、(4-2)根据步骤(4-1)得到的每个存储节点p过去30分钟的负载数据loadp,并使用指数平滑法预测该存储节点p在t+1时刻的负载
23、(4-3)根据步骤(4-1)得到的每个存储节点p过去30分钟的负载数据loadp,并使用如下公式计算该存储节点p的边距放缩系数
24、
25、其中:
26、
27、
28、系数γ∈[0,1]用来放缩系数β∈[0,1]用于在o″t<0时,使边距放缩系数按指数平滑的方式递减。
29、(4-4)针对步骤(2)得到的每个具有负载周期性突发特点的存储节点py而言,根据步骤(4-2)得到的该存储节点py在t+1时刻的指数平滑预测结果和步骤(4-3)得到的该存储节点py的边距放缩系数并按照以下公式计算该存储节点py在t+1时刻负载的预测值
30、
31、其中为存储节点py在[t-60,t-60+k1]时间段内的负载数据的一阶差分序列的90分位数,即:
32、
33、其中k1为预测时对前一负载周期的参考时间窗口大小,且有8≤k1≤15;
34、(4-5)对于云数据库集群的所有存储节点中除了步骤(2)获取的具有负载周期性突发特点的存储节点以外的每个存储节点pn而言,根据步骤(4-2)得到的该存储节点pn的指数平滑预测结果步骤(4-3)得到的该存储节点pn的边距放缩系数以及步骤(3)得到的该存储节点pn的边距并按照以下公式计算存储节点pn在t+1时刻负载的预测值
35、
36、优选地,步骤(6)包括以下子步骤:
37、(6-1)设置计数器j=0;
38、(6-2)获取t-j时刻存储节点pi中负载排名前k2位的主副本集合c1;其中k2的取值范围是5到20;
39、(6-3)对于步骤(6-2)得到的集合c1中的每个主副本r∈c1而言,将t时刻主副本r的贡献度和t-j时刻主副本r的负载相加,作为t时刻该主副本r的贡献度其中t时刻主副本r的贡献度的初始值为0;
40、(6-4)设置j=j+1,并判断j是否小于预设的时间窗口大小w,如果是则返回步骤(6-2),否则转入步骤(6-5);
41、(6-5)将得到的所有主副本的贡献度按照从大到小的顺序进行排列,并将排列结果中前r位的主副本选取作为存储节点pi的候选副本队列
42、优选地,步骤(8)包括以下子步骤:
43、(8-1)设置计数器q=1;
44、(8-2)针对步骤(7)得到的存储节点队列p中的每个存储节点pm而言,获取其对应的候选副本队列中第q个主副本leader对应的所有从副本集合f;
45、(8-3)设置计数器k=1;
46、(8-4)针对步骤(8-2)得到的副本集合f中的第k个从副本follower而言,计算其所在存储节点pfollower中主副本数量占所有副本数量的比例,判断该比例是否大于给定阈值,如果是则转入步骤(8-9),否则转入步骤(8-5);
47、(8-5)从监控系统获取第q个主副本leader与其对应的第k个从副本follower在(t-30,t]时间段内的负载数据,计算二者在该时间段内每个时刻的负载数据差值,并将这些负载数据差值分别与第k个从副本follower所在存储节点pfollower在该时间段内相应时刻的负载数据相加,得到的多个结果构成第k个从副本follower在(t-30,t]时间段内的负载序列
48、(8-6)根据步骤(8-5)得到的第k个从副本follower在(t-30,t]时间段内的负载序列并使用与步骤(4)相同的过程预测在主副本leader与从副本follower进行主从角色切换的情况下第k个从副本follower在t+1时刻pfollower的负载
49、(8-7)判断步骤(8-6)得到的第k个从副本follower在t+1时刻pfollower的负载是否小于给定阈值,如果是则转入步骤(8-8),否则转入步骤(8-9);
50、(8-8)将第k个从副本follower的得分设置为步骤(8-7)得到的负载然后转入步骤(8-10);
51、(8-9)将第k个从副本follower的得分设置为正无穷,然后转入步骤(8-10);
52、(8-10)设置k=k+1,并判断k是否大于候选副本队列中第q个主副本leader对应的从副本总数,如果是则转入步骤(8-11),否则返回步骤(8-4);
53、(8-11)从得到的副本集合f中所有从副本的得分中获取得分最少的从副本bestfollower;
54、(8-12)根据步骤(8-11)得到的从副本bestfollower,从监控系统获取第q个主副本leader与从副本bestfollower在(t-30,t]时间段内的负载数据,计算leader与bestfollower在(t-30,t]时间段内每个时刻的负载数据差值,并将pbestfollower在该时间段每个时刻的负载数据加上对应时刻的负载数据差值,得到的多个结果构成从副本pbestfollower在(t-30,t]时间段内的负载序列并将存储节点pm在该时间段每个时刻的负载数据减掉对应时刻的负载数据差值,得到的多个结果构成存储节点pm在(t-30,t]时间段内的负载序列并向云数据库发送主副本leader与从副本bestfollower进行主从角色切换的指令;
55、(8-13)根据步骤(8-12)得到的存储节点pm在(t-30,t]时间段pm的负载并使用与步骤(4)相同的方法预测主副本leader与从副本bestfollower进行主从角色切换后t+1时刻pm的负载
56、(8-14)判断步骤(8-13)预测的主副本leader与从副本bestfollower进行主从角色切换后t+1时刻pm的负载是否小于过载阈值,如果是则过程结束,否则转入步骤(8-15);
57、(8-15)设置q=q+1,并判断q是否大于存储节点pm的候选副本队列的大小,如果是则过程结束,否则返回步骤(8-2)。
58、按照本发明的另一方面,提供了一种云数据库集群在线副本调度方法,包括:
59、第一模块,用于判断当前时刻t是否为整点时刻,如果是,则转入第二模块,否则转入第四模块。
60、第二模块,用于从云数据库集群中获取多个具有负载周期性突发特点的存储节点。
61、第三模块,用于对于云数据库集群的所有存储节点中除了第二模块获取的具有负载周期性突发特点的存储节点以外的每个存储节点pn而言,计算该存储节点pn在过去12个小时的负载数据的一阶差分序列的90分位数作为后续预测的边距:
62、第四模块,用于对于云数据库集群中的每个存储节点p而言,根据其在过去30分钟内的负载数据预测该存储节点p在t+1时刻的负载
63、第五模块,用于根据第四模块得到的每个存储节点p在t+1时刻的负载预测值设置集合o为所有t+1时刻负载预测值大于过载阈值的存储节点构成的集合,并判断集合o是否为空,如果是,则过程结束,否则转入第六模块;
64、第六模块,用于针对第五模块得到的集合o中的每个存储节点pi∈o而言,选择其存储的主副本集合中贡献度排名前r位的多个主副本作为存储节点pi的候选副本队列
65、第七模块,用于根据第四模块得到的每个存储节点p在t+1时刻的负载预测值和第五模块得到的集合o,将集合o中的所有存储节点按照第四模块得到的这些所有存储节点在t+1时刻的负载预测值进行降序排列,从而得到存储节点队列p。
66、第八模块,用于对于第七模块得到的存储节点队列p中的每个存储节点pm而言,为其对应的候选副本队列中的主副本选择合适的从副本进行主从角色切换,直至pm在t+1时刻负载的预测值小于过载阈值为止。
67、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
68、(1)本发明由于在步骤(4)中预测云数据库集群存储节点负载时,为指数平滑法的预测结果加上边距,进行保守预测,从而大大减少对负载的低估,因此经过调度能够有效避免过载;
69、(2)本发明由于在步骤(4)中预测云数据库集群存储节点负载时,采用了基于统计学算法的预测方法,无需训练机器学习模型,因此代价低,对负载的适应性强;
70、(3)本发明由于在步骤(4)中预测云数据库集群存储节点负载时,考虑节点负载的周期性突发特点,参考了前一周期相应时间段负载的变化情况动态设置边距margin。从而在负载周期性地突发时,边距的添加保证了预测结果能够“跟上”突发,及时地在突发前期预测到过载,解决了现有方法召回率不够高的问题;而在突发结束时相比现有方法又能适当加速减少预测值,避免一部分对负载的高估,从而减少了调度的代价;
71、(4)本发明由于采用了步骤(6),为被预测为即将过载的存储节点选择出对其过载贡献度最高的主副本,这基于云数据库集群存储节点负载组成的特点,即少部分副本的负载之和占据了所在存储节点负载的大部分。从而理论上将这些主副本与适当的从副本进行主从角色切换可以高效地避免存储节点过载,有助于提高在线调度的效率,降低调度的代价;
72、(5)本发明通过采用步骤(8),在步骤(6)的基础上,对被预测即将过载的存储节点的候选主副本,设计了选择合适从副本进行主从角色切换的算法,该算法在完美预测的情况下能避免所有的过载,在结合步骤(4)设计的负载预测算法来评估主从角色切换的收益的情况下能避免90%以上的过载。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196470.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。