一种基于多目标强化学习的智能驾驶汽车加速测试方法
- 国知局
- 2024-07-31 23:16:02
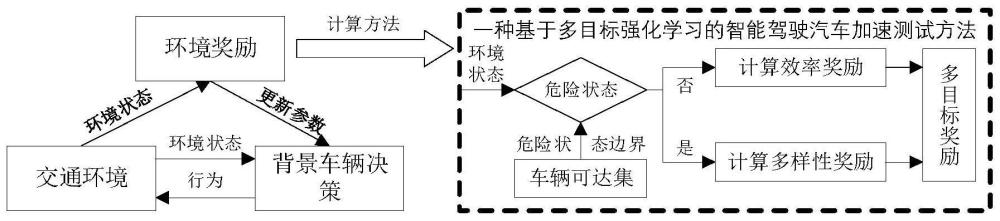
本发明涉及智能驾驶汽车,尤其是涉及加速测试智能汽车安全测试技术。
背景技术:
1、智能驾驶汽车的大规模部署将显著改善道路安全和能源消耗。由于交通场景是复杂且长尾的,使得智能驾驶汽车面临着不确定性的挑战。根据美国国家公路交通安全管理局(nhtsa)在2020年提交的智能驾驶事故报告表明未来每年还将发生数千起涉及2级自动驾驶汽车的车祸放生。目前自然驾驶测试是公认的测试方法,但是关键场景的低暴露率将大幅度增加测试时长和测试费用。因此,一种高效且多样化的测试场景生成方法被迫切需要。
2、现有的智能驾驶测试方法主要分为三类:基于场景分析的测试方法,基于数据驱动的测试方法以及基于生成式模型的测试方法。首先,基于场景分析的测试方法确定关键测试场景的类型依赖于专家经验,这对于黑盒的智能算法以往的经验未必总是有效的。其次,基于数据驱动的测试方法面临着测试覆盖度的挑战,因为复现的场景是观测场景的子集或者邻域场景,且依赖于观测数据集的容量和丰富度。最后,现有的生成式模型的测试方法由于高维的环境状态导致探索空间庞大,导致探索效率低下。此外,基于单一且粗超的场景描述构建的引导函数使得生成的测试场景多样性堪忧。
3、综上可知,由于危险测试场景稀疏的特性,现有的智能汽车安全测试方法存在测试覆盖度不足和训练效率低下的问题。
技术实现思路
1、本发明的目的是针对现有的智能汽车安全测试方法存在测试覆盖度不足和训练效率低下的问题,提供一种基于多目标强化学习的智能驾驶汽车加速测试方法,实现危险场景的高效且多样化的生成。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于多目标强化学习的智能驾驶汽车加速测试方法,包括以下步骤:
4、测试场景描述与危险状态获取:定义测试场景描述,将车辆可达集以内定义为危险状态,车辆可达集以外定义为安全状态,所述危险状态通过车辆状态预测模型对车辆状态进行预测,并基于危险状态筛选模型获取得到;
5、构建用于智能汽车加速测试决策的强化学习网络,所述强化学习网络将环境状态分为车辆可达集以内的危险状态和车辆可达集以外的安全状态,在安全状态内采用效率奖励函数引导网络,在危险状态内采用多样性奖励函数以引导网络生成多样性的危险场景;
6、通过网络与环境的不断交互,利用强化学习网络生成多样化的危险测试场景。
7、所述车辆状态预测模型采用三自由度车辆模型表达车辆动力学特性,模型的输入为车辆的横、纵向车速以及方向盘转角;状态量为车辆的横、纵向速度和航向角变化率,公式如下:
8、
9、式中:为前轮侧偏力;为后轮侧偏力;为前轮纵向力;为后轮纵向力;为横摆角速度;为横摆角加速度;和分别为当前车辆的横、纵向车速,为整车质量;为前轮转角;为车辆质心到前轴的距离;为车辆质心到后轴的距离;为车辆的转动惯量。
10、在车辆状态预测模型中引入了非线性轮胎模型以考虑车辆的非线性特性,计算公式如下所示:
11、
12、
13、
14、
15、式中:和分别为车辆前后轴距距离;为重力加速度;为地面附着系数;α1和α2分别表示当前车辆的前、后轮侧偏角。
16、为获得车辆下一时间步长可能到达的区域,采用三阶三段龙格-库塔公式对车辆状态预测模型进行离散化得到系统离散化模型,并进行预测下一时刻的车辆状态,其中,定义系统离散化模型的输入矩阵u=[fyf fyr fxf fxr δf],状态矩阵则递推预测过程计算公式如下:
17、
18、式中:t为时间步长;x*为预测的下一时刻车辆状态矩阵,f代表离散化的车辆状态预测模型的状态方程。
19、通过判断轮胎状态是否到达附着极限来选择车辆边界状态,定义如下的危险边界状态sbc的获取方法:
20、
21、式中:fyf为前轮侧偏力;fxf为前轮纵向力;m为整车质量;a和b分别为车辆前后轴距距离;g为重力加速度;μ为地面附着系数;
22、根据获得的危险边界状态确定危险边界中心的位置,将危险边界状态简化为一个圆,定义危险状态筛选模型为:
23、
24、st:o(x)=(min(sbc(x))+max(sbc(x)))/2
25、o(y)=(min(sbc(y))+max(sbc(y)))/2
26、r=max((max(|sbc(x)-o(x)|)),(max(|sbc(y)-o(y)|)))
27、式中:sa为被测的智能汽车状态,sr为定义的危险状态,o(x,y)为危险边界状态中心位置的坐标,r为当前被测的智能汽车状态sa距离危险边界状态中心位置的坐标o(x,y)的距离。
28、所述效率奖励函数基于相对距离构建,且与相对距离成反向变化关系,表示为:
29、re=(dba0-dbai)
30、
31、
32、式中:re为效率奖励值;dba0为初始环境下背景车辆与被测车辆的距离;dbai为第i时刻下背景车辆与被测车辆的距离;(xa,ya)为被测车辆坐标,(x0,y0)为初始环境下背景车辆坐标,(xi,yi)为第i时刻下背景车辆坐标。
33、所述多样性奖励函数包括碰撞区域多样性奖励和危险状态多样性奖励。
34、在危险状态区域的中心点构建坐标系,将危险状态区域分割为四个部分,分别对应来自四个方向的碰撞类型事件,即前左、前右、后左以及后右,通过期望分布和实际分布的kl散度构建碰撞区域多样性奖励,公式如下:
35、
36、式中:qsc(x)为期望的碰撞区域分布,初步定义为qsc(x)=[0.25,0.25,0.25,0.25];psc(x)为实际碰撞区域分布;rra为定义的碰撞区域多样性奖励。
37、所述危险状态多样性奖励的目的是期望危险状态被均匀触发,以保证同一碰撞区域内的危险工况的差异性,危险状态多样性奖励通过期望分布和实际分布的kl散度构建,公式如下:
38、
39、式中:qcs(x)为期望的危险状态分布,初步定义为均匀分布,即qcs(x)=n/n;其中n为场景测试到达的危险状态的总次数,n为实际探索过程中发现的危险状态种类数量;pcs(x)为实际碰撞区域分布,即pcs(x)=m/n;其中m为某一个危险状态实际发生的次数;rrc为定义的危险状态多样性奖励。
40、所述强化学习网络的基础参数定义如下:
41、状态空间s:表示智能汽车可能处于的状态集合,即s∈s,s为具体的一个环境状态元素,采用车辆的位置和速度表示环境状态,即s=(sb,sa),其中sb(xb,yb,vxb,vyb)表示背景车辆状态;sa(xa,ya,vxa,υya)表示被测智能车辆状态,(x,y)表示位置坐标,v表示速度;
42、行动空间a:表示智能汽车可以执行的行动集合,即a∈a,a为具体的一个背景车辆操作行为;
43、状态转移函数p(s′|s,a):表示从状态s执行行动a后转移到状态s′的概率,在环境中车辆的状态转移严格受到动力学约束,则其被假定为确定性环境,即p(s′|s,a)=1;
44、奖励函数r(s,a,s′):表示在状态s执行行动a后转移到状态s′时的奖励,包括效率奖励和多样性奖励。
45、与现有技术相比,本发明具有以下有益效果:
46、(1)依据碰撞点必然发生在智能汽车可以到区域的特点,本发明采用可达集定义危险状态和安全状态,提供了环境状态分类准确原则,这为设计多目标奖励函数提供了基础,以保证高效的模型探索能力和高的危险场景覆盖率。
47、(2)本发明构建的车辆状态预测模型和危险状态筛选模型,给出了危险场景的明确且统一的数学定义,这为模型探索多样化的危险场景提供了明确的探索指南。
48、(3)本发明设置了多目标奖励函数,在安全状态内采用效率奖励函数引导网络,以提高危险场景的生成效率,在危险状态内采用多样性奖励函数以引导网络生成多样性的危险场景,以同时保证效率和多样。
49、(4)本发明采用碰撞区域多样性和危险状态多样性描述危险场景的多样性,从大范围探索方向覆盖和局部危险状态覆盖两个方向指导模型危险场景探索,有效避免模型进入局部最优。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196705.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表