一种基于人工智能的假新闻识别方法及系统
- 国知局
- 2024-07-31 23:18:58
本发明属于新闻识别,具体是指一种基于人工智能的假新闻识别方法及系统。
背景技术:
1、假新闻识别方法是综合运用自然语言处理和人工智能技术,提取新闻的特征,根据不同的特征进行分类和判断,能够有效地识别假新闻,提高新闻的真实性和可信度。但是现有的假新闻识别方法存在新闻特征提取不够全面、缺乏对文本和图像数据的综合考虑和对文本数据中关键信息的捕捉能力差的问题;现有的假新闻识别方法存在信息源单一、忽略同领域新闻的关联性和缺乏全局性考虑的问题。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了一种基于人工智能的假新闻识别方法及系统,针对现有的假新闻识别方法存在新闻特征提取不够全面、缺乏对文本和图像数据的综合考虑和对文本数据中关键信息的捕捉能力差的问题,本方案引入字符级和句子级的注意机制来关注不同层级上的重要特征来提取文本数据的全局特征,引入局部特征注意机制和卷积神经网络来提取文本数据的局部特征,从而更有效地捕捉文本数据中的关键信息,并提取图像数据的全局特征和局部特征,综合考虑文本数据和图像数据得到新闻特征,能够更全面地描述新闻内容,并基于新闻类型、新闻领域和不同特征的组合构建特征集,使得新闻特征更具有辨识度和区分度;针对现有的假新闻识别方法存在信息源单一、忽略同领域新闻的关联性和缺乏全局性考虑的问题,本方案设计新闻文本-图像匹配识别器和同领域内新闻真实性识别器,设计相似层计算文本和图像之间的相似度,完成新闻的文本数据和图像数据的匹配检测,有助于解决单一信息源导致识别准确性不高的问题;设计图构建层和卷积层更新节点特征,完成同领域内新闻真实性检测,能够更好地考虑新闻之间的相似性和差异性;通过将两个识别器的输出加权求和作为假新闻识别结果,提高假新闻识别的准确性和可靠性。
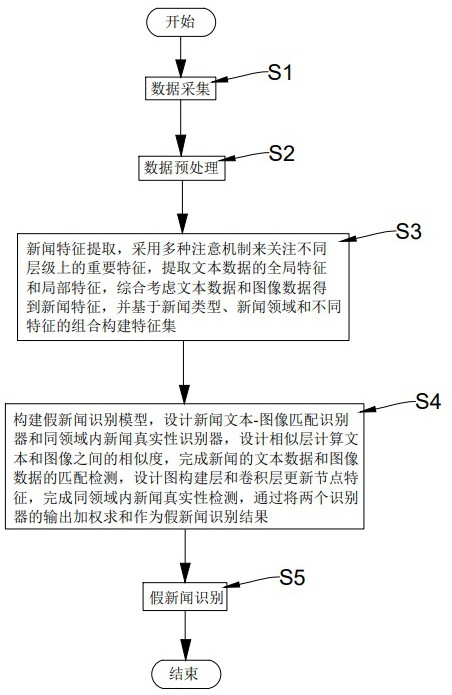
2、本发明采取的技术方案如下:本发明提供的一种基于人工智能的假新闻识别方法,该方法包括以下步骤:
3、步骤s1:数据采集;
4、步骤s2:数据预处理;
5、步骤s3:新闻特征提取;
6、步骤s4:构建假新闻识别模型;
7、步骤s5:假新闻识别。
8、进一步地,在步骤s1中,所述数据采集是采集历史新闻数据,历史新闻数据包括文本数据、图像数据、新闻领域和新闻类型,新闻类型包括真新闻和假新闻,将新闻类型作为数据标签。
9、进一步地,在步骤s2中,所述数据预处理分别对采集的文本数据和图像数据进行文本预处理和图像预处理,具体包括以下步骤:
10、步骤s21:文本预处理,对采集的文本数据进行去除噪声和去除停用词处理;将文本的长度指定为文本中的句子数量,将句子的长度指定为句子中的字符数量,预先规定文本的长度和句子的长度分别为p和q;若去除噪声和去除停用词后文本中句子的长度小于q,则使用结束符号在句子末尾进行填充,使句子的长度为q;若句子的长度大于q,则对句子进行截断,使句子的长度为q;同样,若去除噪声和去除停用词后文本的长度小于p,则使用结束符号在文本末尾进行填充,使文本的长度为p;若文本的长度大于p,则对文本进行截断,使文本的长度为p;
11、步骤s22:图像预处理,对采集的图像数据进行图像增强、图像分割和图像去噪处理。
12、进一步地,在步骤s3中,所述新闻特征提取分别提取文本数据和图像数据的特征,具体包括以下步骤:
13、步骤s31:文本数据特征提取,提取预处理后的文本数据的全局特征和局部特征,包括以下步骤:
14、步骤s311:文本数据全局特征提取,将预处理后的文本分为字符级和句子级,由字符级特征向量得到句子级特征向量,并使用不同的注意机制来关注在不同级别上的重要特征,包括以下步骤:
15、步骤s3111:计算字符级特征向量,使用word2vec模型将预处理后的文本数据转换为字符级表示向量,将bilstm作为字符级编码器,bilstm包含两个方向的lstm结构,分别用于捕捉字符在每个位置的上下文信息,通过字符级编码器获得文本的第i句第j个字符的前向隐藏层结果和后向隐藏层结果,结合前向和后向隐藏层结果,得到文本的第i句第j个字符的特征向量;所用公式如下:
16、;
17、;
18、;
19、式中,和分别是文本的第i句第j个字符的前向隐藏层结果和后向隐藏层结果,是文本的第i句第j个字符的特征向量,和分别是bilstm的前向隐藏层函数和后向隐藏层函数,是文本的第i句第j个字符的表示向量;
20、步骤s3112:计算字符级重要性权重,使用字符级注意机制计算每个字符的特征向量对构建当前句子的语义的重要性权重;所用公式如下:
21、;
22、;
23、式中,是的隐藏表示,tanh(·)是激活函数,是的字符级重要性权重,wf、bf和rf分别是字符级注意机制的权重矩阵、偏置项和查询向量,t是转置操作;
24、步骤s3113:计算句子级特征向量,基于字符级特征向量和字符级重要性权重得到句子级表示向量,将bilstm作为词级编码器,通过字符级编码器获得文本的第i句的前向隐藏层结果和后向隐藏层结果,结合前向和后向隐藏层结果,得到文本的第i句的特征向量;所用公式如下:
25、;
26、;
27、;
28、式中,和分别是文本的第i句的前向隐藏层结果和后向隐藏层结果,是文本的第i句的特征向量,是文本的第i句的表示向量;
29、步骤s3114:计算句子级重要性权重,使用句子级注意机制计算每个句子的特征向量对构建当前文本的语义的重要性权重;所用公式如下:
30、;
31、;
32、式中,是的隐藏表示,是的句子级重要性权重,wv、bv和rv分别是句子级注意机制的权重矩阵、偏置项和查询向量;
33、步骤s3115:计算文本数据的全局特征,基于句子级特征向量和句子级重要性权重得到文本数据的全局特征,和分别是文本的第1句和第p句的特征向量,和分别是和的句子级重要性权重;
34、步骤s312:文本数据局部特征提取,包括以下步骤:
35、步骤s3121:卷积,使用1d卷积神经网络从字符级特征向量中提取局部特征,卷积核we∈d×l,l是卷积核的长度,等于编码器bilstm单元输出的维数,d是卷积核的高度,将卷积核应用于不同的字符间隔得到每个句子的局部特征映射={m1,…,mj,…,mq-d+1};1d卷积神经网络所用公式如下:
36、;
37、式中,be是卷积核的偏置项,、和分别是文本的第i句第1个字符到第d个字符、第j个字符到第j+d+1个字符和第q-d+1个字符到第q个字符的间隔区间,m1、mj和mq-d+1分别是、和的局部特征映射;
38、步骤s3122:计算局部特征重要性权重,使用局部特征注意机制计算每个句子的特征映射对构建当前文本的语义的重要性权重;所用公式如下:
39、;
40、;
41、式中,是的隐藏表示,是的局部特征重要性权重,wl、bl和rl分别是局部特征注意机制的权重矩阵、偏置项和查询向量;
42、步骤s3123:计算文本数据的局部特征,基于每个句子的特征映射和局部特征重要性权重得到文本数据的局部特征,和分别是文本的第1句和第p句的局部特征映射,和分别是和的局部特征重要性权重;
43、步骤s32:图像数据特征提取,使用gist算法和sift算法分别提取预处理后的图像数据的全局特征k和局部特征z;
44、步骤s33:计算新闻特征,将文本数据的全局特征a和局部特征u与图像数据的全局特征k和局部特征z相拼接,得到新闻特征;
45、步骤s34:构建特征集,基于新闻类型、文本数据的全局特征a和局部特征u与图像数据的全局特征k和局部特征z构建第一特征集,基于新闻类型、新闻领域和新闻特征构建第二特征集。
46、进一步地,在步骤s4中,所述构建假新闻识别模型,包括新闻文本-图像匹配识别器和同领域内新闻真实性识别器,新闻文本-图像匹配识别器基于文本数据和图像数据的相似来区分新闻的真假,同领域内新闻真实性识别器基于同领域内新闻的异同来区分新闻的真假,将两者相结合得到假新闻识别模型的输出,具体包括以下步骤:
47、步骤s41:设计新闻文本-图像匹配识别器,新闻文本-图像匹配识别器包括第一输入层、相似层和匹配输出层;第一输入层接收第一特征集,相似层计算文本和图像的总相似度;匹配输出层输出匹配识别结果;包括以下步骤:
48、步骤s411:设计相似层,相似层分别计算文本和图像的全局相似度、局部相似度和全局-局部相似度,加权求和得到总相似度,所用公式如下:
49、;
50、;
51、;
52、;
53、式中,s是总相似度,s1、s2和s3分别是全局相似度、局部相似度和全局-局部相似度,β1、β2和β3分别是全局相似度权重、局部相似度权重和全局-局部相似度权重,sim(·)是余弦相似度函数,max(·)是求最大值函数,a和u分别是文本数据的全局特征和局部特征,k和z分别是图像数据的全局特征和局部特征;
54、步骤s412:匹配输出层,所用公式如下:
55、;
56、式中,是文本-图像匹配识别器输出的匹配识别结果,sigmoid(·)是激活函数;
57、步骤s42:设计同领域内新闻真实性识别器,同领域内新闻真实性识别器包括第二输入层、图构建层、卷积层和真实性输出层;第二输入层接收第二特征集;图构建层基于属于同领域的新闻特征构建同领域关系图;卷积层用来更新同领域关系图的节点特征;真实性输出层输出真实性识别结果;包括以下步骤:
58、步骤s421:设计图构建层,为每个领域的新闻构建一个同领域关系图,每个新闻作为一个节点,节点内的信息是新闻特征,基于余弦相似度来定义节点之间的边,预先设定相似阈值,若两个节点内新闻特征的余弦相似度大于等于相似阈值,则两个节点之间存在边;否则,两个节点之间不存在边;
59、步骤s422:设计卷积层,卷积层的层为n,卷积层通过卷积操作利用相邻节点来更新节点的新闻特征,这种信息传播机制可以使每个新闻节点获得其相邻节点的特征,从而考虑到新闻在同领域中的相似性和差异性,更好地区分真假新闻,更新节点特征所用公式如下:
60、;
61、式中,fl+1和fl分别是第l+1层和第l层卷积层的节点特征矩阵,gl是第l层卷积层的权重矩阵,u是邻接矩阵,i是单位矩阵,是添加自连接的邻接矩阵,,是的度矩阵,relu(·)是激活函数;
62、步骤s423:真实性输出层,所用公式如下:
63、;
64、式中,是同领域内新闻真实性识别器输出的真实性识别结果,fn是第n层卷积层的节点特征矩阵,wz和bz分别是同领域内新闻真实性识别器的权重矩阵和偏置项;
65、步骤s43:计算假新闻识别模型输出,将新闻文本-图像匹配识别器和同领域内新闻真实性识别器的输出加权求和作为假新闻识别模型的最终识别结果。
66、进一步地,在步骤s5中,所述假新闻识别是采集待识别的新闻数据,待识别的新闻数据包括文本数据、图像数据和新闻领域,对待识别的新闻数据进行数据预处理和新闻特征提取后,输入至假新闻识别模型中,基于模型的输出得到新闻类型,实现假新闻识别。
67、本发明提供的一种基于人工智能的假新闻识别系统,包括数据采集模块、数据预处理模块、新闻特征提取模块、构建假新闻识别模型模块和假新闻识别模块;
68、所述数据采集模块采集历史新闻数据,并将数据发送到数据预处理模块;
69、所述数据预处理模块分别对采集的文本数据和图像数据进行文本预处理和图像预处理,并将数据发送至新闻特征提取模块;
70、所述新闻特征提取模块采用多种注意机制来关注不同层级上的重要特征,提取文本数据的全局特征和局部特征,综合考虑文本数据和图像数据得到新闻特征,并基于新闻类型、新闻领域和不同特征的组合构建特征集,并将数据发送至构建假新闻识别模型模块;
71、所述构建假新闻识别模型模块设计新闻文本-图像匹配识别器和同领域内新闻真实性识别器,设计相似层计算文本和图像之间的相似度,完成新闻的文本数据和图像数据的匹配检测,设计图构建层和卷积层更新节点特征,完成同领域内新闻真实性检测,通过将两个识别器的输出加权求和作为假新闻识别结果,并将数据发送至假新闻识别模块;
72、所述假新闻识别模块采集待识别的新闻数据,进行数据预处理和新闻特征提取后,输入至假新闻识别模型中,基于模型的输出实现假新闻识别。
73、采用上述方案本发明取得的有益效果如下:
74、(1)针对现有的假新闻识别方法存在新闻特征提取不够全面、缺乏对文本和图像数据的综合考虑和对文本数据中关键信息的捕捉能力差的问题,本方案引入字符级和句子级的注意机制来关注不同层级上的重要特征来提取文本数据的全局特征,引入局部特征注意机制和卷积神经网络来提取文本数据的局部特征,从而更有效地捕捉文本数据中的关键信息,提高了文本数据特征的表达能力,并提取图像数据的全局特征和局部特征,综合考虑文本数据和图像数据得到新闻特征,能够更全面地描述新闻内容,提高了特征的多样性和丰富性,并基于新闻类型、新闻领域和不同特征的组合构建特征集,使得新闻特征更具有辨识度和区分度。
75、(2)针对现有的假新闻识别方法存在信息源单一、忽略同领域新闻的关联性和缺乏全局性考虑的问题,本方案设计新闻文本-图像匹配识别器和同领域内新闻真实性识别器,设计相似层计算文本和图像之间的相似度,完成新闻的文本数据和图像数据的匹配检测,有助于解决单一信息源导致识别准确性不高的问题,为假新闻识别提供了更多的维度和依据;设计图构建层和卷积层更新节点特征,完成同领域内新闻真实性检测,考虑了同领域内新闻的特点,能够更好地考虑新闻之间的相似性和差异性;通过将两个识别器的输出加权求和作为假新闻识别结果,提高了假新闻识别的准确性和可靠性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196966.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。