一种基于强化学习的低轨卫星网络任务调度方法及系统
- 国知局
- 2024-07-31 23:20:29
本发明涉及低轨卫星网络,尤其涉及一种基于强化学习的低轨卫星网络任务调度方法及系统。
背景技术:
1、第六代(6g)移动网络旨在提供全球覆盖,以确保互联网可用性和随时随地无缝接入。由于传统的地面网络受到地理位置和经济成本等瓶颈的限制,卫星网络(尤其是低轨卫星网络)由于其无缝覆盖和低传输延迟,是实现这一愿景的潜在技术。近年来,随着物联网的蓬勃发展,偏远地区出现了大量物联网服务,如灾害监测、海洋运输、物体识别和跟踪等,远程物联网概念正在兴起。远端物联网(iort)用户通常在计算能力和电池电量方面受到限制,难以应对激增的计算任务。一种有效的方法是将iort任务卸载到地面上更强大的云服务器上,通过卫星中继传输进一步执行。然而,由于卫星网络物理位置的限制,卫星中继传输将带来不可忽略的长传输距离和重传输负载,这对于低延迟要求的iort服务来说通常是无法容忍的。
2、作为一种新兴的计算范式,边缘计算可以通过将云计算平台扩展到网络边缘,甚至扩展到移动设备本身,为用户提供近距离的计算资源。因此,通过将边缘计算引入卫星网络,卫星边缘计算可以进一步提高卫星传输速率,减少处理延迟,从而有效提高任务的计算性能。在卫星边缘计算中,计算资源普遍分布且仅限于一颗卫星。随着iort用户卸载的数据量的增加,计算需求可能超过单个卫星的处理能力,导致计算响应时间延长和功耗高。此外,卫星边缘计算网络中的计算任务分布不均衡,并随着卫星的高速移动而变化,导致网络资源利用效率低下、不平衡。
3、任务调度是解决上述挑战的一种很有效的方法。通过卫星边缘计算的高效任务调度,可以根据任务的多样性,通过边缘协作和云边缘协作将任务卸载到具有更多可用资源的计算节点进行处理,从而提高任务的计算性能,优化资源利用率。现有方案通常将任务调度问题表述为一次性优化问题。然而,由于卫星边缘计算网络的动态特性,需要在顺序调度时隙上确定任务调度决策,以实现长期计算性能优化。在小时间尺度调度时隙上解决一次性优化问题在计算上还是非常棘手的。另一方面,卫星边缘计算网络中如何为多样化的服务进行资源切片将通过影响任务调度策略来影响计算任务的处理性能,这在现有的方案中没有得到充分考虑。由于存储容量的限制,单个卫星为每个服务切片的资源有限,其任务请求量也随时间和空间的变化而变化。因此,静态资源切片策略是不可行的,导致卫星边缘计算网络的服务性能低下。但是,如果服务部署策略与任务调度一起频繁调整,则会产生大量的部署开销。因此,需要在更大的时间尺度上优化服务部署,以提高卫星边缘计算网络的服务能力,降低服务部署成本。
4、现有技术方案将卫星作为边缘计算网络节点的低轨卫星边缘计算lec(low-orbitedge computing)网络在低轨卫星上部署边缘计算资源,物联网设备生成的数据可以直接由低轨卫星处理。当物联网设备的接入卫星(或其相邻卫星)具有请求的处理功能时,物联网设备与提供处理功能的卫星之间的端到端路径不包括过多的卫星间链路。因此,可以节省这些卫星间链路的带宽。此外,数据处理延迟将大大减少,因为用户可以直接从卫星(lec节点)获得计算服务。但该技术中卫星资源的分配和使用方式采用传统边缘计算的预请求—分配模式,根据业务请求的资源量进行分配和编排,这可能会造成业务并未充分使用被分配的资源的情况,造成高成本的卫星计算存储资源的浪费。另外,当业务运行在接近满载的节点上并且实际使用资源超出预分配量时,无法进行资源扩容和协同处理,造成任务处理失败的同时浪费资源的问题。同时,难以使用多星分布式协同的方式处理计算密集型任务。对于多种业务流而言,可能有不同的优化目标,例如最小化任务完成延迟、平衡卫星负载和最小化通信开销等,该技术方案难以辨别业务种类并做出调度。
技术实现思路
1、鉴于此,本发明实施例提供了一种基于强化学习的低轨卫星网络任务调度方法及系统,以消除或改善现有技术中存在的一个或更多个缺陷,解决现有技术方案存在的卫星计算存储资源浪费、当实际使用资源超出预分配量时,无法进行资源扩容和协同处理、不适用于计算密集型任务以及难以辨别业务种类做出调度决策的问题。
2、一方面,本发明提供了一种基于强化学习的低轨卫星网络任务调度方法,所述方法在低轨卫星网络中执行,所述方法包括以下步骤:
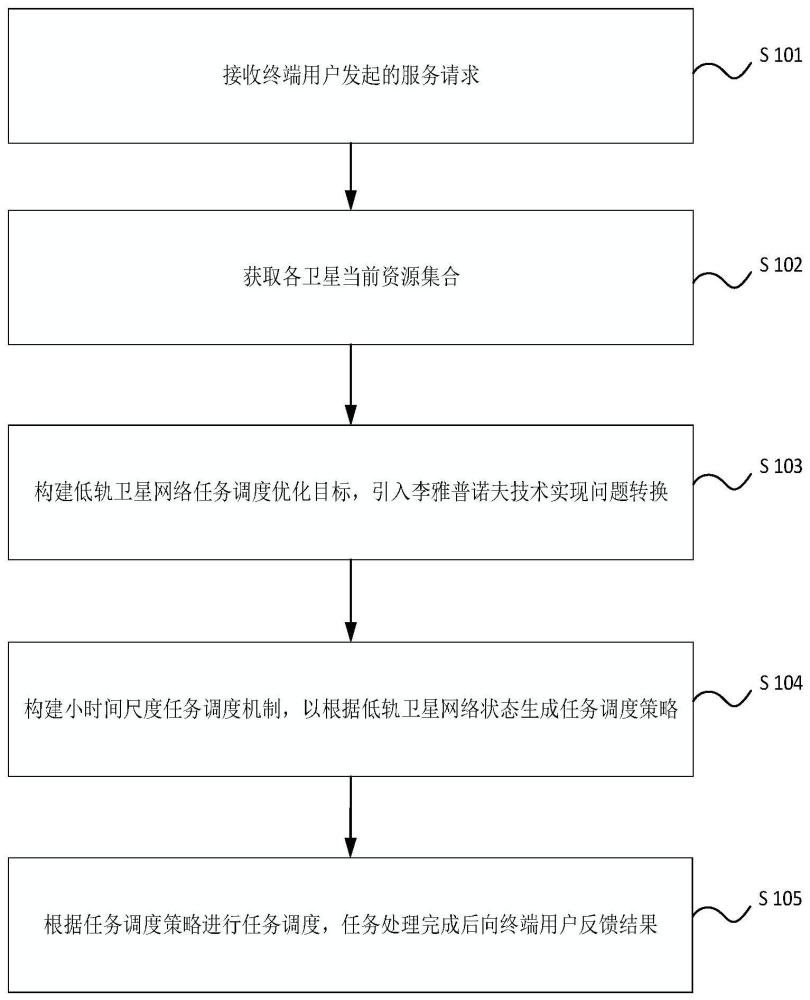
3、接收终端用户发起的服务请求;
4、获取各卫星当前资源状态集合;所述资源状态集合至少包括任务生成状态、各卫星之间的通信状态、各卫星与地面之间的通信状态;
5、将最小化任务处理成本作为任务调度的优化目标,构建延迟赤字队列表示长期延迟约束,引入李雅普诺夫函数表示对延迟要求的满意程度,引入李雅普诺夫漂移跟踪两个连续时隙之间所述李雅普诺夫函数的变化,将所述优化目标转化为最小化所述李雅普诺夫漂移加惩罚项;
6、基于强化学习构建任务调度机制,以所述任务生成状态、数据队列状态、各卫星之间和各卫星与地面之间的通信状态构建状态空间,以各卫星执行的任务调度构建动作空间,以所述优化目标构建奖励函数;采用经验回放的方式训练所述任务调度机制,以根据当前状态生成相应的任务调度策略;
7、根据所述任务调度策略进行任务调度,任务处理完成后向所述终端用户反馈结果。
8、在本发明的一些实施例中,将最小化任务处理成本作为任务调度的优化目标,计算式为:
9、
10、时隙t时的任务处理成本计算式为:
11、
12、其中,π表示所述任务调度策略;t表示时隙,t∈t;n表示卫星节点,n∈n;j表示计算任务,j∈j;ct表示时隙t时的任务处理成本;ek,j,n(t)表示任务序列k的能量损耗;dk,j,n(t)表示任务序列k的传输时延;ψk,j,n(t)表示任务序列k丢弃的任务量;ke、kd、kψ为性能增益系数。
13、在本发明的一些实施例中,构建延迟赤字队列表示长期延迟约束,并引入李雅普诺夫函数表示对延迟要求的满意程度,其中,所述延迟赤字队列的更新过程为:
14、
15、所述李雅普诺夫函数定义为:
16、l(yj.t)=yj.t/2;
17、其中,yj,t+1表示t+1时隙计算任务j的延迟赤字队列;dj,t表示t时隙计算任务j的处理时延;表示t时隙计算任务j的最大容忍时延;yj.t表示t时隙计算任务j的延迟赤字队列。
18、在本发明的一些实施例中,引入李雅普诺夫漂移跟踪两个连续时隙之间所述李雅普诺夫函数的变化,计算式为:
19、δ(yj.t)=l(yj.t+1)-l(yj.t);
20、其中,δ(yj.t)表示所述李雅普诺夫漂移;yj,t+1表示t+1时隙计算任务j的延迟赤字队列;yj.t表示t时隙计算任务j的延迟赤字队列;
21、对所述李雅普诺夫漂移的上限进行限定:
22、
23、其中,dj,t表示t时隙计算任务j的处理时延;表示t时隙计算任务j的最大容忍时延;为常数,表示计算任务j的最大可实现延迟;
24、将所述优化目标转化为最小化所述李雅普诺夫漂移加惩罚项,计算式为:
25、
26、其中,为加权常数。
27、在本发明的一些实施例中,以所述任务生成状态、数据队列状态、各卫星之间和各卫星与地面之间的通信状态构建状态空间,以各卫星执行的任务调度构建动作空间,以所述优化目标构建奖励函数,还包括:
28、所述状态空间计算式为:
29、st={γn(t),φn,j(t),rn,m(t),rn,0(t)|n,m∈n,j∈j};
30、其中,γn(t)表示所述任务生成状态;φn,j(t)表示所述数据队列状态;rn,m(t)表示卫星n和卫星m之间的通信状态;rn,0(t)表示卫星n和地面之间的通信状态;
31、所述动作空间计算式为:
32、
33、其中,表示任务是否从卫星n调度到卫星m的状态;k表示所述任务序列;
34、所述奖励函数计算式为:
35、
36、其中,t表示时隙,t∈t;n表示卫星节点,n∈n;j表示计算任务,j∈j;ek,j,n(t)表示任务序列k的能量损耗;dk,j,n(t)表示任务序列k的传输时延;ψk,j,n(t)表示任务序列k丢弃的任务量;ke、kd、kψ为性能增益系数。
37、在本发明的一些实施例中,采用双延迟深度确定性策略梯度算法对所述任务调度机制进行优化;所述双延迟深度确定性策略梯度算法采用双q网络、延迟策略更新和目标策略平滑,以解决高估偏差问题。
38、在本发明的一些实施例中,采用经验回放的方式训练所述任务调度机制,还包括:
39、初始化critic网络、actor网络和目标网络;
40、在每个时隙中,代理从所述状态空间中获取当前状态,基于当前状态和策略生成动作;通过所选择的动作获得奖励值和下一时隙状态;
41、将所述当前状态、所述动作、所述奖励值和所述下一时隙状态构建四元组,存储在经验回放存储器中;
42、在每个时隙中,从所述经验回放存储器中采样小批量样本,用于训练并更新所述critic网络、所述actor网络和所述目标网络。
43、在本发明的一些实施例中,还包括:
44、对于所述critic网络,每次更新时采用所述双q网络,以q值较小的网络作为q目标,所述双q网络更新的计算过程为:
45、
46、其中,rt表示所述奖励函数;γ表示折扣因子;表示参数为θiq’的q函数;st+1表示t+1时隙的状态;表示目标策略的输出;
47、所述critic网络通过最小化损失实现更新,计算式为:
48、
49、其中,l(θiq)表示损失;
50、对于所述actor网络,更新计算式为:
51、
52、其中,j(φ)表示q函数对策略参数φ的梯度;mb表示小批量样本;表示参数为θ1的q函数;πφ(s)表示策略π对策略参数φ的梯度;
53、使用软更新更新所述目标网络,计算式为:
54、θiq’←τθiq+(1-τ)θiq’;
55、其中,τ表示软更新因子。
56、另一方面,本发明提供一种基于强化学习的低轨卫星网络任务调度系统,所述系统被执行时实现如上文中提及的任意一项所述基于强化学习的低轨卫星网络任务调度方法的步骤,所述系统包括:
57、终端用户,用于发起服务请求;
58、低轨卫星网络,由各卫星节点构成,设有任务调度机制,用于根据所述低轨卫星网络状态生成任务调度策略,对所述卫星节点进行任务调度;任务处理完成后,向所述终端用户反馈结果。
59、另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上文中提及的任意一项所述方法的步骤。
60、本发明的有益效果至少是:
61、本发明提供一种基于强化学习的低轨卫星网络任务调度方法及系统,包括:在低轨卫星网络中,接收终端用户发起的服务请求;获取各卫星资源信息、计算任务状态信息等;基于强化学习构建小时间尺度的低轨卫星网络任务调度机制,使用马尔科夫决策过程实现对计算任务的最优调度,根据任务处理实际的能量损耗、时延等进行合理调度,解决传统任务处理方法中卫星高动态带来的计算任务服务需求不匹配、低轨卫星静态资源与计算任务任务需求之间的不匹配导致的资源浪费等问题,以尽量减少网络能耗和任务处理延迟,提高任务处理性能。
62、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
63、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197082.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。