基于深度Q网络的无预测风电场日前优化调控方法及系统
- 国知局
- 2024-07-31 17:53:10
本发明涉及风电场的优化调度,具体涉及一种基于深度q网络的无预测风电场日前优化调控方法及系统。
背景技术:
1、风力资源受风速影响很大,风机出力会随风速变化而变化,所以风力发电具有很强的随机性和间歇性,从而引起汇集系统电压的大幅度波动。在大规模风电场内,风力发电的不确定性可能会带来各种挑战,例如造成线路电压波动过大和线路网损增加等问题。
2、为了削弱风机出力波动的影响,文献(马明,杜婉琳,陶然,等.基于鲁棒优化的风电场分层电压优化控制策略[j].天津大学学报(自然科学与工程技术版),2021,54(12):1309-1316.)在日前优化阶段使用风机的日前出力预测数据建立鲁棒优化模型,得到次日“最恶劣”场景下无功补偿装置应该做出的投切决策,以提高风电场内电压控制水平;文献(zhang j,liu y h,zhang d y,et al.multi-time-scale coordinative andcomplementary reactive power and voltage control strategy for wind farmscluster[c]//2018international conference on power system technology(powercon),november 6-8,2018,guangzhou,china:1927-1934.)设计了风电场集群多目标无功优化与电压控制策略,在日前调控阶段,基于风电出力日前预测曲线,对离散式无功补偿设备的容量进行预优化;文献(wang m,wang t,mu y,et al.a volt-var optimalcontrol for power systemintegrated with wind farms considering the availablereactive power from ev chargers[c]//2016ieee power and energy society generalmeeting(pesgm),july 17-21,2016,boston,ma:1-5.)提出了一种电动汽车充电器的可用无功功率与风电场集成的电力系统电压-无功最优控制策略,根据前一天预测的负载和风力输出来最大限度地减少网损。上述日前优化调控方案都能较好地应对风电不确定性带来的负面影响,稳定风电场的电压水平或降低网损,但是这些方法均需要风机的日前预测出力数据作为日前优化调控的研究基础。然而,每台风机的日前预测出力曲线较难得到,且风电的日前预测误差无法完全避免,该误差的引入会造成日前优化调控方案有效性的降低,从而增加了后续日内风机调控的难度。
3、在现阶段电力系统领域的研究中,各种调控策略所采用的方法不仅仅基于传统的数学优化模型,也越来越多地与人工智能算法相结合,其中强化学习因其不依赖具体模型参数的特点和强大的学习能力而广受青睐。文献(yin l,zhang c,wang y,etal.emotional deep learning programming controller for automatic voltagecontrol of power systems[j].ieee access,2021,9:31880-31891.)和文献(hossain rr,huang q,huang r.graph convolutional network-based topology embedded deepreinforcement learning for voltage stability control[j].ieee transactions onpower systems,2021,36(5):4848-4851.)将深度强化学习应用于电压稳定控制场景;文献(范培潇,柯松,杨军,等.基于改进多智能体深度确定性策略梯度的多微网负荷频率协同控制策略[j].电网技术,2022,46(9):3504-3515.)研究基于深度强化学习的多微网负荷频率协同控制;文献(yan z,xu y.real-time optimal power flow:a lagrangian based deepreinforcement learning approach[j].ieee transactions on power systems,2020,35(4):3270-3273.)使用深度确定性策略梯度(deep deterministic policy gradient,ddpg)算法进行基于实时最优潮流的电力系统优化调度研究;文献(孙庆凯,王小君,王怡,等.基于多智能体nash-q强化学习的综合能源市场交易优化决策[j].电力系统自动化,2021,45(16):124-133.)使用多智能体q学习(multi agent q-learning)研究电力市场领域的综合能源市场交易优化。另外在电力系统紧急控制、需求响应和综合能源管理等领域,深度强化学习都得到了广泛的应用。但是,如何充分发挥强化学习模型的决策能力,实现无预测风电场日前优化调控,则仍然是一项亟待解决的关键技术问题。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种基于深度q网络的无预测风电场日前优化调控方法及系统,本发明旨在充分发挥强化学习模型的决策能力,基于深度q网络(dqn)实现无预测风电场日前优化调控方法,在不引入预测误差的情况下直接得出日前优化调控方案。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种基于深度q网络的无预测风电场日前优化调控方法,包括:
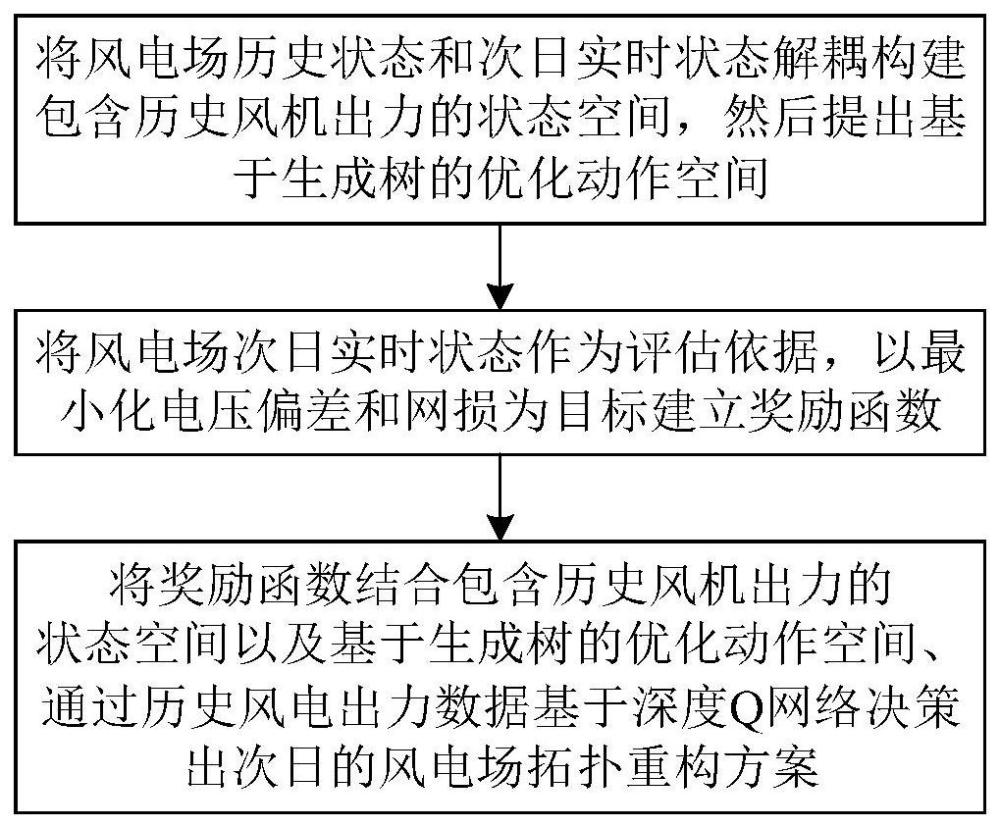
4、步骤s101,将风电场历史状态和次日实时状态解耦构建包含历史风机出力的状态空间,然后提出基于生成树的优化动作空间;
5、步骤s102,将风电场次日实时状态作为评估依据,以最小化电压偏差和网损为目标建立奖励函数,结合包含历史风机出力的状态空间以及基于生成树的优化动作空间、通过历史风电出力数据基于深度q网络决策出次日的风电场拓扑重构方案。
6、可选地,步骤s101中构建的包含历史风机出力的状态空间的函数表达式为:
7、st=[pw,t_,qw,t_,αt,t,kt],
8、上式中,st表示第t时段风机出力的状态,pw,t_表示t时刻的nw台风机的风机有功出力,qw,t_表示t时刻的nw台风机的风机无功出力,αt表示t时刻的风电场的n个拓扑开关的开关状态,开关状态包括闭合和关断两种状态;kt表示t时刻拓扑改变过的次数,且一天的所有时段内拓扑改变过的次数小于等于预设阈值。
9、可选地,步骤s101中提出基于生成树的优化动作空间包括:
10、步骤s201,获取风电场的拓扑结构的无向图,所述无向图中的节点为风电场的风机,风机间闭合的拓扑开关作为无向图中连接节点的通路;
11、步骤s202,利用广度优先搜索算法对风电场的拓扑结构的无向图进行遍历,得到各节点相互连通但无环路的生成树,以作为基于生成树的优化动作空间。
12、可选地,步骤s102中将风电场次日实时状态作为评估依据,以最小化电压偏差和网损为目标建立的奖励函数的函数表达式为:
13、rt=rt,cheng+rt,jiang,
14、上式中,rt为奖励函数,rt,cheng为惩罚部分,rt,jiang为奖励部分,且有;
15、rt,cheng=rt,1+rt,2,
16、
17、rt,jiang=rt,1+rt,2,
18、
19、上式中,rt,1、rt,2、rt,1和rt,2为中间变量,r1和r2为高惩罚值,r1<0,r2<0;ui,t表示t时段节点电压标幺值;ui,min和ui,max分别表示节点电压的上下限标幺值;kt表示t时刻拓扑改变过的次数;αt+1和αt表示t+1时刻和表示t时刻的动作,r3表示网损优化的奖励系数,r3>0;r4表示电压优化的奖励系数,r4>0;ploss0,t为原拓扑状态下次日第t时段风电场的网损;ploss,t为次日第t时段风电场的网损;δui0,t表示原拓扑状态下次日第t时段节点i的电压标幺值与基准值之差;δui,t表示次日第t时段节点i的电压标幺值与基准值之差,n为节点数量。
20、可选地,步骤s102中将风电场次日实时状态作为评估依据,结合包含历史风机出力的状态空间以及基于生成树的优化动作空间、通过历史风电出力数据基于深度q网络决策出次日的风电场拓扑重构方案包括:
21、步骤s301,初始化经验回放池d;构建深度q网络的目标q网络和估计q网络,设置随机种子以随机初始化估计q网络的参数θ,并将参数θ复制给目标q网络;设置最大训练回合数和最大步骤数;
22、步骤s302,随机抽取连续四日的风电出力历史数据,其中前三日的风电出力数据作为状态空间的历史风机出力,第四日的风电出力数据作为风电场次日出力,并复位风电场拓扑状态、时刻和拓扑改变次数,返回一个初始风机出力的状态s1;
23、步骤s303,输入状态st给估计q网络,根据预设的ε-greedy策略在基于生成树的优化动作空间中随机选择一个动作at或者选择估计q网络输出中最大回报值对应的动作at,执行动作at对风电场进行拓扑重构,计算出奖励函数rt的值,并通过潮流计算得到下一时刻状态st+1,然后将得到的{st,at,rt,st+1}存放到经验回放池d,从经验回放池d里抽取指定数量的样本,根据目标q网络和估计q网络进行损失函数计算并更新估计q网络的参数θ,且每隔一段时间将估计q网络的参数θ复制给目标q网络;
24、步骤s304,若潮流计算不收敛或执行至最大步骤数,则结束回合内步骤循环,跳转步骤s302进行下一训练回合,训练回合数加1,否则跳转步骤s303继续回合内步骤循环;
25、步骤s305,判断训练回合数是否等于最大训练回合数,若训练回合数等于最大训练回合数,结束回合循环;否则,将训练回合数加1,跳转步骤302继续下一训练回合。
26、可选地,所述目标q网络为卷积神经网络cnn。
27、可选地,所述估计q网络为卷积神经网络cnn。
28、此外,本发明还提供一种基于深度q网络的无预测风电场日前优化调控系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述基于深度q网络的无预测风电场日前优化调控方法。
29、此外,本发明还提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序/指令,该算机程序/指令被编程或配置以通过处理器执行所述基于深度q网络的无预测风电场日前优化调控方法。
30、此外,本发明还提供一种计算机程序产品,包括计算机程序/指令,该算机程序/指令被编程或配置以通过处理器执行所述基于深度q网络的无预测风电场日前优化调控方法。
31、和现有技术相比,本发明主要具有下述优点:本发明方法包括将风电场历史状态和次日实时状态解耦构建包含历史风机出力的状态空间,然后提出基于生成树的优化动作空间;将风电场次日实时状态作为评估依据,以最小化电压偏差和网损为目标建立奖励函数,结合包含历史风机出力的状态空间以及基于生成树的优化动作空间、通过历史风电出力数据基于深度q网络决策出次日的风电场拓扑重构方案,本发明能够旨在充分发挥强化学习模型的决策能力,基于深度q网络(dqn)实现无预测风电场日前优化调控方法,在不引入预测误差的情况下直接得出日前优化调控方案。
本文地址:https://www.jishuxx.com/zhuanli/20240731/177123.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表