一种基于即插即用的特征变换器的人机混合图像编码方法
- 国知局
- 2024-08-02 13:52:38
本发明属于数据通信中信源编码,具体涉及一种基于即插即用的特征变换器的人机混合图像编码方法。
背景技术:
1、随着ai技术的飞速发展和机器学习应用的指数增长,车联网、视频监控、智慧城市、智慧工业、智慧交通等领域已经采用了大量的许多智能平台和智能应用,这些智能平台应用与大量的摄像头等传感器之间产生了海量的数据通信。数据量的增长直接导致传统先前面向人类视觉的压缩编码方法效率无法满足增长的业务需求降低,在传输存储效率、延时和规模上均也难以满足现实需要,面向智能机器智能的编码方法及提上议程。
2、2019年7月iso/iec jtc1 sc29 mpeg成立vcm(video coding for machines)机器视觉编码国际标准标准研究工作组,专门研究面向针对机器视觉任务的视频编码,这里的机器智能处理任务包含多种计算机视觉任务,包括目标检测、目标识别、目标跟踪、实例分割、姿态估计、行为识别等等。机器视觉编码vcm以视频码流压缩性能和计算机视觉任务性能为指标,而非不是传统针对人眼视觉的psnr/ssim等人眼质量评价视频指标。
3、现有的方法如专利cn116366863a《人眼视觉和机器视觉协同的图像特征压缩和解压缩方法》和专利cn117061751a《一种面向机器视觉和人眼视觉的图像压缩系统》为了能够同时兼顾机器视觉的任务性能图片和用于人眼视觉的图片质量,其机器视觉任务和压缩系统性能往往无法达到最佳,而且容易造成人眼视觉效果下降。因此,如何在满足保持已有机器视觉任务性能和压缩性能的前提情况下,提升人眼视觉效果成为亟需解决的技术问题。
4、在视频监控、工业视觉等领域采纳应用,随着ai技术的发展,传统的由人观看视频逐渐转变为由ai算法处理视频,面向机器视觉的视频超过面向人眼视觉的视频流量占比,面向机器视觉的编码和表征技术逐步发展成熟,机器视觉编码技术已经实现技术标准化和标准芯片化,应用于视频监控的人机车非检测识别、检测、跟踪和异常行为如穿越警戒线、打架斗殴等检测场景,以及工业视觉的钢板表面缺陷检测、ocr识别等故障检测识别场景中,极大的提升了数据传输和存储的效率,同时提升了ai分析的效率,得到产业界的广泛采用。然而,在视频监控和工业ai等应用场景中,一方面,机器视觉任务即ai算法是多种多样且种类不断增加的,难以提取一种机器视觉特征实现所有适配的机器视觉任务的性能达到最优,而针对不同的机器视觉任务提取不同的机器视觉特征将极大的增加编码器的复杂度;另一方面,以机器视觉为主要视频消费对象的场景中,仍然存在一定比例的人眼对于异常视频回溯、确认和取证的应用需求。针对这一部分需求,现有的特征编码方案无法满足,多采用视频流+特征流的双流方式实现针对机器和人眼的需求,这样对带宽和存储存在极大的浪费。
技术实现思路
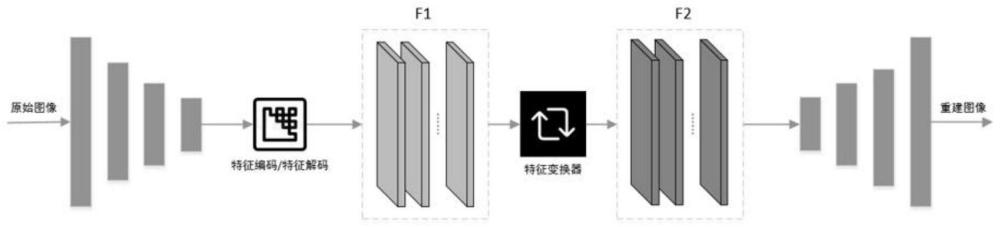
1、针对现有技术中存在的不足,本发明提供一种基于即插即用的特征变换器的人机混合图像编码方法,因此,本发明提出一种面向人机混合的图像编码框架,对端到端图像编解码模型进行机器视觉联合训练;对于联合训练的端到端图像编解码模型的解码器的熵解码、反量化模块之后插入特征变换器,通过特征变换器实现机器视觉特征到多机器视觉任务的转换适配以及机器视觉特征到人眼视觉任务的转换适配,在保证传输和存储效率最优的前提下,满足机器视觉多任务性能要求,并兼顾人眼视觉图像重建需要。
2、本发明的技术解决方案是:
3、一种基于即插即用的特征变换器的人机混合图像编码方法,对端到端图像编解码模型结合机器视觉任务a进行机器视觉联合训练,此时机器视觉特征适配于机器视觉任务a;对于联合训练的端到端图像编解码模型的解码器的熵解码、反量化模块之后插入特征变换器,然后进行如下(1)操作实现机器视觉特征到多机器视觉任务的转换适配,或者进行如下(2)操作实现机器视觉特征到人眼视觉任务的转换适配:(1)基于联合训练的端到端图像编码模型权重结合机器视觉任务b训练特征变换器,通过特征变换器实现机器视觉任务a的视觉特征到多机器视觉任务的视觉特征的变换;(2)基于联合训练的端到端图像编码模型权重结合人眼视觉任务训练特征变换器,通过特征变换器实现机器视觉任务a的视觉特征到人眼视觉任务的视觉特征的变换。
4、所述的特征变换器网络结构包括:特征变换模块、特征激活模块、特征学习模块、特征通道注意力模块、特征空间注意力模块;
5、其中特征变换模块由n个卷积层串联组成,n的大小由输入特征尺寸自适应确定,每个卷积层的步长为1、卷积核尺寸为3×3×m、卷积核数量为m;特征激活模块为leakyrelu激活函数;特征学习模块由n个残差块串联组成,n的大小由输入特征尺寸自适应确定,每个残差块包括两个卷积层,两个卷积层中间是leakyrelu激活函数,每个卷积层的步长为1、卷积核尺寸为3×3×m、卷积核数量为m;特征通道注意力模块由逐通道的全局平均池化层、逐通道的全局最大池化层、n个全连接层、sigmoid激活函数组成,该模块输出每个通道的注意力权重mc;特征空间注意力模块由沿通道维度的最大平均池化层、沿通道维度的最大池化层、卷积层组成,卷积层的步长为1、卷积核尺寸为3×3×2、卷积核数量为1,该模块输出每个空间位置的注意力权重ms。
6、将上述尺寸为(h,w,m)的解码器输出的特征张量f1输入特征变换器,得到尺寸为(h,w,m)的输出特征张量f2。在特征通道注意力模块,将尺寸为1×1×m的通道注意力权重mc与特征张量f'的每个通道相乘,得到注意力加权后的通道特征张量f”,这将强调对当前任务有帮助的通道,并抑制无关的通道。在特征空间注意力模块,将尺寸为h×w×1的空间注意力权重ms与通道特征张量f”的每个空间位置的特征相乘,得到空间注意力加权后的空间特征张量f2。这样可以突出重要的图像区域,并减少不重要的区域的影响。通过特征变换器实现机器视觉特征到多机器视觉任务的转换适配以及机器视觉特征到人眼视觉任务的转换适配。
7、一种基于即插即用的特征变换器的人机混合图像编码方法,包括步骤如下:
8、步骤1:确定端到端图像编解码模型,并结合机器视觉任务a进行机器视觉联合训练;
9、步骤2:对于联合训练的端到端图像编解码模型的解码器的熵解码、反量化模块之后插入特征变换器;
10、步骤3:基于联合训练的端到端图像编码模型权重,结合机器视觉任务b训练特征变换器,通过训练好的插入特征变换器的端到端图像编解码模型实现面向机器视觉任务b的图像编码;
11、步骤4:基于联合训练的端到端图像编码模型权重,结合人眼视觉任务训练特征变换器,通过训练好的插入特征变换器的端到端图像编解码模型实现面向人眼视觉任务的图像编码。
12、进一步的,步骤1具体方法如下:
13、结合机器视觉任务a联合训练端到端图像编解码模型,步骤如下:
14、(1)将训练集原始图像输入端到端图像编解码模型的编码器,根据每个待编码值出现的概率估计得到码率估计结果,并在解码器输出重建机器视觉任务图像y1;
15、(2)将上述重建机器视觉任务图像y1输入机器视觉任务网络,得到机器视觉任务结果;
16、(3)计算上述重建机器视觉任务图像y1与训练集原始图像的失真损失d1,计算机器视觉任务结果与gt(训练数据标签)的任务损失d2,并结合上述码率估计结果r,得到模型训练损失函数:
17、l=r+w1*d1+w2*d2
18、(4)通过损失函数进行反向传播,更新模型参数。
19、基于上述联合训练步骤,得到面向机器视觉任务a的端到端图像编码器e的模型权重we和端到端图像解码器d的模型权重wd。
20、进一步的,步骤2中所述的特征变换器包括特征变换模块、特征激活模块、特征学习模块、特征通道注意力模块、特征空间注意力模块;
21、其中特征变换模块由n个卷积层串联组成,n的大小由输入特征尺寸自适应确定,每个卷积层的步长为1、卷积核尺寸为3×3×m、卷积核数量为m;特征激活模块为leakyrelu激活函数;特征学习模块由n个残差块串联组成,n的大小由输入特征尺寸自适应确定,每个残差块包括两个卷积层,两个卷积层中间是leakyrelu激活函数,每个卷积层的步长为1、卷积核尺寸为3×3×m、卷积核数量为m;特征通道注意力模块由逐通道的全局平均池化层、逐通道的全局最大池化层、n个全连接层、sigmoid激活函数组成,该模块输出每个通道的注意力权重mc;特征空间注意力模块由沿通道维度的最大平均池化层、沿通道维度的最大池化层、卷积层组成,卷积层的步长为1、卷积核尺寸为3×3×2、卷积核数量为1,该模块输出每个空间位置的注意力权重ms。
22、进一步的,步骤3具体方法如下:
23、冻结训练好的端到端图像编码器e模型权重we和端到端图像解码器d模型权重wd,在步骤1训练的基础上对插入特征变换器t的端到端图像编解码模型进行面向机器视觉任务b的训练,训练步骤如下:
24、(1)将训练集原始图像输入编码器,根据每个待编码值出现的概率估计得到码率估计结果,并在解码器输出重建机器视觉任务图像y2;
25、(2)计算上述重建机器视觉任务图像y2与训练集原始图像的失真损失d'1,计算机器视觉任务结果与gt(训练数据标签)的任务损失d'2,并结合上述码率估计结果r,得到模型训练损失函数:
26、l=r+w1*d′1+w2*d′2
27、(3)通过损失函数进行反向传播,更新模型参数;
28、基于上述训练步骤,得到面向机器视觉任务b的特征变换器权重wt。
29、进一步的,步骤4具体方法如下:
30、冻结训练好的端到端图像编码器e模型权重we和端到端图像解码器d模型权重wd,在步骤1训练的基础上对插入特征变换器t的端到端图像编解码模型进行面向人眼视觉任务的训练,训练步骤如下:
31、(1)将训练集原始图像输入编码器,根据每个待编码值出现的概率估计得到码率估计结果,并在解码器输出重建人眼视觉任务图像;
32、(2)计算上述重建人眼视觉任务图像与训练集原始图像的失真损失d,并结合上述码率估计结果r,得到模型训练损失函数:
33、l=r+w*d
34、(3)通过损失函数进行反向传播,更新模型参数;
35、基于上述训练步骤,得到面向人眼视觉任务的特征变换器权重w't。
36、本发明有益效果如下:
37、本发明通过即插即用且自适应的特征变换器,满足相同编码特征在不同任务下的特征迁移,提高不同任务的任务精度。本发明提出一种面向人机混合的图像编码框架,对端到端图像编解码模型进行机器视觉联合训练;对于联合训练的端到端图像编解码模型的解码器的熵解码、反量化模块之后插入特征变换器,通过特征变换器实现机器视觉特征到多机器视觉任务的转换适配以及机器视觉特征到人眼视觉任务的转换适配,在保证传输和存储效率最优的前提下,满足机器视觉多任务性能要求,并兼顾人眼视觉图像重建需要。
38、因此,本发明所提出的端到端图像编解码模型通过插入特征变换器可以同时适配于多机器视觉任务和人眼视觉任务,满足机器视觉多任务性能要求,并兼顾人眼视觉图像重建需要。所提出的技术方案在智慧城市、工业互联网、安防监控、数字乡村等领域具有广泛的应用潜力。
本文地址:https://www.jishuxx.com/zhuanli/20240801/240916.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表