一种低轨卫星网络边缘计算卸载与资源分配联合优化方法
- 国知局
- 2024-08-02 14:46:56
本发明属于卫星通信网络与边缘计算,特别是涉及一种基于分层多智能体强化学习的低轨卫星网络计算卸载与资源分配联合优化方法。
背景技术:
1、与传统的地面无线通信网络相比,低轨卫星网络具有覆盖范围广、传输延迟低等优势,能够为偏远地区和移动用户提供可靠的通信连接。边缘计算则是一种分布式计算模型,它将计算资源和服务从传统的云数据中心移动到离用户更近的边缘设备或边缘节点中进行处理,降低了数据传输延迟,提高了计算效率,并能够更好地满足对实时性和隐私保护的需求。将低轨卫星网络与边缘计算相结合,可以充分发挥两者的优势,使得卫星上的数据可以更快地进行处理和分析,减少对地面数据中心的依赖,为各种应用场景,如灾害响应、农业监测、环境监测等提供更强大的支持。
2、随着低轨卫星网络边缘计算的发展,计算卸载和资源分配的联合优化(jointcomputation offloading and resource allocation,jcora)成为了当前研究的热点之一,具有一定的复杂性和挑战性。传统的方法往往基于静态的规则或启发式算法,无法适应动态和复杂的网络环境。而深度强化学习(deep reinforcement learning,drl)作为一种基于智能体与环境交互学习的方法,具有在复杂环境下进行决策和优化的能力。
3、然而,将drl应用于该联合优化问题也面临一个重要挑战。在低轨卫星网络边缘计算系统中,drl智能体不仅需要考虑将任务卸载到哪里(即离散动作),还需要确定为每个任务分配多少资源(即连续动作)。大多数传统的drl算法不能直接处理这样的混合动作空间。目前很多研究通过连续化或离散化的方式强制将混合动作空间转换为同构动作空间,但会面临可扩展性问题以及在拟合和泛化方面的困难。
技术实现思路
1、本发明旨在解决低轨卫星网络边缘计算中drl智能体所面临的混合动作空间难题,即需联合考虑计算卸载(离散动作)和资源分配(连续动作)。本发明将"分而治之"的思想引入到强化学习算法当中,提出了一种分层多智能体强化学习(hierarchical multi-agent drl,hmadrl)算法。该算法将复杂的jcora问题分解为两层子问题。上层子问题是全局性的计算卸载优化问题,下层子问题是卫星本地的资源分配优化问题。
2、本专利提出通过卫星协作实现任务的全局卸载,采用多智能体drl(madrl)模型进行优化。下层本地资源分配子问题由各卫星根据资源约束独立决策,采用深度确定性策略梯度(ddpg)模型生成连续的资源分配动作。本发明的主要贡献在于创新性地提出了分层多智能体强化学习算法,并通过实验验证了其在降低任务处理延迟、提高任务成功率和实现负载均衡等方面的有效性,所采用的技术方案为:一种低轨卫星网络边缘计算卸载与资源分配联合优化方法,该方法包括:
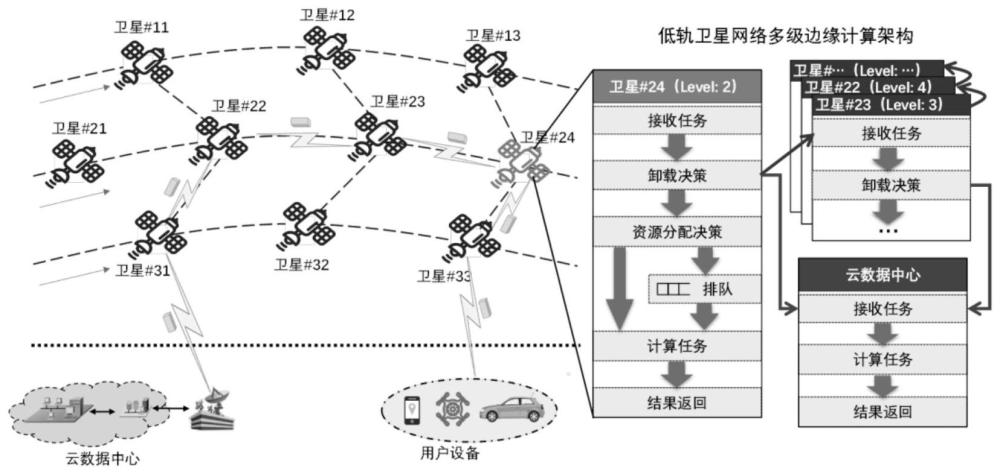
3、步骤1:建立低轨卫星网络多级边缘计算系统模型;
4、将一个大规模的低轨卫星网络作为目标网络,卫星的集合被表示为其中satnum是系统中卫星的总数,采用边缘计算处理对延迟敏感、计算量有限的任务,这些任务按照生成时间排序为对于任务taski,存在一个任务处理延迟的上限li,如果超过了这个时间限制,任务taski将被视为失败,任务计算量的大小用si表示;
5、卫星satv1和satv2之间的传输时延用表示,传播延迟用表示,从卫星satv1到satv2这一跳星间通信的总时延为:
6、
7、i表示该时延是星间通信导致的,v1和v2分别表示建立通信的两颗卫星;在卫星leov确定要本地执行任务taski后,会进一步为该任务分配边缘计算资源使用ctotal表示星载计算资源总和,使用表示卫星上当前可用的计算资源;在satv上执行taski的计算时延计算为:
8、
9、其中,ξ是cpu的计算密度;如果卫星上的所有资源都被完全占用,taski将进入排队状态,引入排队时延直到相应的资源被节点释放;
10、假设云数据中心具有丰富的计算能力,并且当任务被卸载到云中时不会发生排队,云计算的时延表示为:
11、
12、其中,ccloud表示云数据中心分配给任务的资源;
13、步骤2:建立卸载与资源分配联合优化问题;
14、优化目标在于减轻卫星之间的负载不平衡的同时,最小化所有计算任务的长期延迟;因此,在问题建模中应综合考虑任务时延和资源利用率;
15、步骤2.1:确定任务时延;
16、任务时延由通信延迟和计算延迟组成;将taski的卸载路径上的卫星记为:
17、
18、可做的卸载决策用集合表示;
19、其中表示本地执行任务,表示转发任务给相邻的上、下、左、右低轨卫星,表示将taski转发到地面云数据中心处理;根据通信和计算模型,taski的任务时延tpdi为:
20、
21、其中,表示星地通信时延,fi是taski的卸载路径上的卫星数量;
22、步骤2.2:确定资源利用率;
23、在多级边缘计算架构中,通过将任务从负载较重的卫星转移到资源利用率较低的卫星上,实现负载均衡;因此,资源利用率的变化可以反映负载均衡的有效性;如果taski最终被卸载到边缘节点,则在为taski分配资源之前和之后的资源利用率通过以下方式计算:
24、
25、
26、表示taski的卸载路径上的最后一颗卫星,表示分配之前的星载资源利用率,表示分配之后的资源利用率,卫星上的总资源,表示卫星上的空闲资源,cifi表示卫星为任务分配的资源;
27、利用资源利用率的相对变化率来促使任务被卸载到资源利用率更低的卫星上,进一步优化负载均衡;计算和之间的相对变化率δruri为:
28、
29、以最小化tpdi和最大化δruri为目标,单任务边缘计算成本函数为:
30、costi=tpdi+β(-δruri)
31、其中,β是平衡不同优化目标之间权衡的权重。考虑到对所有边缘计算任务的总体优化,jcora问题最终表示为:
32、p:
33、s.t.
34、c1:
35、c2:
36、c3:
37、c4:
38、c5:
39、c6:
40、c7:
41、其中,c2将六个卸载决策限制为{0,1}二进制变量,c3指定每个卫星能且只能从中选择一个决策;c4表示要么执行taski,要么将其转发到云数据中心;c5表示任务卸载路径中间的卫星必须将任务转发给相邻卫星;此外,c6对卫星资源分配施加限制,确保不超过当前可用资源;c7要求taski在上限时延内执行完毕,否则任务将被视为失败;
42、步骤3:使用分层强化学习框架将jcora联合优化问题解耦;
43、步骤3.1:确定全局计算卸载问题;
44、目标是通过卫星之间的协作实现全局优化的任务卸载决策,表示为:
45、p1:
46、s.t.c1-c5,and c7
47、步骤3.2:确定本地资源分配问题;
48、在这个子问题中,目标是根据全局计算卸载决策,在每个卫星上独立地分配资源以有效地执行任务,表示为:
49、p2(v):
50、s.t.c6 and c7
51、步骤4:将计算卸载问题转换为马尔可夫决策过程;
52、步骤4.1:计算卸载;
53、在大规模低轨星座中,卫星实际难以获取全局状态,因本发明将每个卫星上的计算卸载决策过程表示为部分可观测马尔可夫决策过程(pomdp),其中每个智能体仅基于其局部观测而不是全局状态来采取行动。
54、步骤4.2:确定状态空间;
55、假设智能体satv在时隙t接收到taski,则智能体satv可观测到的的状态空间表示为ov(t)={resinfo,queinfo,cloudinfo,taskinfo},作为指导智能体决策的基础;其中,satv和四个相邻卫星的当前可用资源状态构成了可观测状态空间的一个关键组成部分,表示为当边缘计算资源完全被占用时,任务队列的长度更好地反映了卫星的工作负载;在观测空间中包括satv和其相邻卫星的任务队列长度,表示为queinfo={qv,qv_up,qv_down,qv_left,qv_right};
56、利用cloudinfo={acv,acv_up,acv_down,acv_left,acv_right}表示卫星是否连接到云端,cloudinfo中的所有元素都是{0,1}二进制变量;最后taskinfo={si,li,leveli}包含taski的计算量小、时延上限li以及已卸载的级数leveli;
57、步骤4.3:确定动作空间;
58、在接收到边缘计算任务并观察到观测空间中的网络状态后,每个智能体可以从离散的动作空间中选择一个卸载决策,分别是本地执行任务、将任务转发到相邻卫星之一以及转发到地面云数据中心;
59、步骤4.4:确定奖励函数;
60、分为及时奖励和长期奖励,奖励时采用延迟奖励,即在每个任务完成后,才能计算沿任务卸载路径由卫星选择的先前卸载行动的奖励;延迟奖励仅在训练过程中使用,长期折扣奖励,使用了折扣因子γ∈(0,1]在即时奖励和长远奖励之间取得平衡;智能体与环境持续交互,并以最大化长期折扣奖励为目标更新其策略;
61、步骤5:将资源分配问题转换为马尔可夫决策过程;
62、步骤5.1:确定状态空间;
63、在每个时隙中,每个智能体satv负责为卸载到本地的任务分配必要的计算资源,这些任务表示为其中m表示等待资源分配的任务数;在为satv分配资源时要考虑的因素不仅包括当前可用的计算资源容量还包括关键的任务中心信息,即数据大小和剩余存活时间因此,satv的状态空间设计为:
64、
65、步骤5.2:确定动作空间;
66、每个智能体的动作空间具有m个维度,表示为其中是表示分配给的资源,特征为连续动作;此外,动作空间中的值应满足约束条件可用资源约束条件,以防止超过可用资源限制;
67、步骤5.3:确定奖励函数;
68、每个智能体的目标是学习一种最优策略,有效利用边缘计算资源,减少平均任务计算延迟,并确保任务成功执行。若任务失败,还会对智能体给予一定的惩罚值。同时,进一步计算长期折扣奖励;
69、步骤6:根据步骤4建立的马尔可夫决策过程计算卸载策略;
70、步骤7:根据步骤4建立的马尔可夫决策过程计算资源分配策略。
71、进一步的,所述步骤6的具体方法为:
72、在每颗卫星上部署了双重深度q网络,建立专为离散动作空间设计的基于值函数的drl模型;给定卸载策略πv,双重深度q网络旨在学习一个q值函数,对状态-动作进行计算;
73、所述双重深度q网络包括估计q网络和目标q网络,使用观测状态sv(t)作为输入,q网络输出动作空间av(t)内动作的q值,以此为依据选择最优卸载策略。
74、进一步的,所述步骤7的具体方法为:
75、采用深度确定性策略网络计算资源分配,所述深度确定性策略梯度网络包括:策略网络和值网络,策略网络学习一个策略μ,根据其输出直接生成动作,而值网络估计一个值函数q,对状态-动作对进行更好的评估。actor将根据值网络的评估来更新其策略;
76、在深度确定性策略网络的训练过程中,反复从经验池中随机抽样一个小批量,使用确定性策略梯度来更新策略网络;同时,采用td-target算法,在每轮训练迭代的多次更新中利用目标值网络和目标策略网络μθ来计算固定的目标价值;估计值网络通过梯度下降算法来最小化损失;在每次迭代之后,目标值网络的参数会进行软更新;训练完成后,根据值网络做出的资源分配决策。
77、进一步的,所述双重深度q网络中通过以下方式计算最优q值函数
78、
79、其中,γ是折扣因子,表示当前动作的长远影响,是在t时刻计算卸载决策的即时奖励,e[.]表示求期望;
80、利用深度神经网络来逼近最优q值函数;更详细地说,每个卫星使用两个深度神经网络,一个是估计q网络qv(sv(t),av(t);δv),另一个是目标q网络q′v(sv(t),av(t);δv′);δv和δv′是深度神经网络的参数;使用观测状态sv(t)作为输入,q网络输出动作空间av(t)内动作的q值;在深度神经网络训练过程中,卫星根据这些q值和ε-greedy策略做卸载决策:
81、
82、其中,random action表示随机动作,probability表示用均匀分布概率生成的随机数,范围在0和1之间,argmaxa表示取q值最大的动作,ε表示使用随机策略的概率;
83、任务完成后,卫星将从环境反馈中接收到延迟奖励一个经验元组{sv(t),sv(t+1),av(t),rv(t)}被记录在经验池中,用于打断相关训练数据的关联性,优化训练过程;每个智能体通过从经验池中随机抽样一个小批量,随后更新q网络的参数值来进行训练;目标q网络用于计算每个状态-动作对的固定目标q值,在每个训练迭代中为每个状态-动作对(sv(t),av(t))计算一个固定的时序差分目标q值yi(t):
84、
85、其中,是(sv(t),av(t))的延迟奖励,γ是折扣因子,表示当前动作的长远影响;根据计算得到的时序差分目标,损失函数定义如下:
86、lossv(t)=(yv(t)-qv(sv(t),av(t);δv))2
87、估计q网络通过最小化损失来进行训练,采用梯度下降算法:
88、
89、和δv分别表示更新后和更新前的神经网络参数;表示更新梯度,α表示学习率;
90、在每轮训练迭代之后,目标q网络的参数根据估计q网络进行更新;逐步地提高其逼近最优q值函数的能力,实现对计算卸载决策的更准确评估。
91、进一步的,所述深度确定性策略网络包括:策略网络和值网络;策略网络学习一个策略μ,根据其输出直接生成动作,而值网络估计一个值函数q,对状态-动作对进行更好的评估;策略网络将根据值网络的评估来更新其策略,由于leo卫星在星座中是同质的,参数共享方法在所有智能体之间实施;
92、智能体与环境进行交互,然后将经验元组{s(t),s(t+1),a(t),r(t)}记录在经验池中,s(t),s(t+1),a(t),r(t)分别表示当前状态、下一时刻状态、当前动作和即时奖励;在交互过程中,将高斯噪声添加到动作输出中,以在动作空间中实现更广泛的探索;在训练过程中,反复从经验池中随机抽样一个小批量,使用确定性策略梯度算法来更新策略网络:
93、
94、其中,
95、其中,和θ分别表示值网络和策略网络的参数值,表示两个参数的更新梯度,μθ(a|s)表示选择不同策略的概率,μθ(s)表示在状态s时选择的策略,表示值网络估计的值函数,它以状态和动作作为输入,输出每个状态-动作对(s,a)的价值,为了更新值网络,采用td-target算法,在每轮训练迭代的多次更新中利用目标值网络和目标策略网络μθ′计算固定的目标价值y(t):
96、
97、其中,r(t)是(s(t),a(t))的即时奖励,而(s(t+1),a(t+1))表示后续的状态-动作对,为了消除过高估计问题,使用两个值网络和并行估计经验池的相同小批量数据的值,并选择较小的值作为最终结果,然后目标价值y(t)被修改为:
98、
99、μθ'(s(t+1))表示在状态s(t+1)时选择的策略,是状态-动作的q值值网络的损失函数表示为:
100、
101、其中,表示状态-动作的q值;
102、估计值网络通过梯度下降算法来最小化损失,在每次迭代之后,目标值网络的参数会进行软更新,最终做出的资源分配决策。
103、本发明采用一种高效的分层深度强化学习(hmadrl)算法,巧妙地将jcora问题拆分成两个层级的子问题,有效解决了传统深度强化学习在应对混合动作空间时所面临的挑战。通过这种层次化的分解手段,本发明能够更加精准地驾驭问题的复杂性,并实现更高效的jcora优化,显著提升了低轨卫星网络边缘计算性能,展现出较传统方法更高的效率和精确度。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243873.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表