一种基于强化学习的自适应采样视频编码方法和装置
- 国知局
- 2024-08-02 14:49:50
本发明涉及视频编码领域,特别涉及一种基于强化学习的自适应采样视频编码方法和装置。
背景技术:
1、数据是信息的载体,对于定量的信息设法减少表达这些信息所用数据量的方法称为数据压缩。数据压缩分为有损压缩和无损压缩,无损压缩适用于数据需要严格完全重建的情形;有损压缩以引入一定失真为代价,获取更高的压缩。在视频场景下人眼对某些细节并不敏感的前提下,这些细节信息的丢失是不易被察觉的,因此可以利用人们的感知特性,尽可能使压缩产生的失真发生在人不容易察觉的地方,借此换来较高的压缩比,也因此催生了多种视频编码方法,为了使编码后的码流能够在大范围内互通和规范解码,视频编码标准也应运而生,例如h.26x系列,mpeg系列,我国于2006年也形成具有自主知识产权的音视频编码标准(audio video coding standard,avs),其发展至今已具有相当的国际竞争力。近年来信息技术发展非常迅速,有线与无线网络的带宽都在不断增加,各类存储器的容量也在不断增长。但随着流媒体的不断发展,超高清视频日渐普及,人们对视频源保真度的要求也越来越高,存储容量与网络带宽的增长始终无法满足人们对存储与传输高分辨率视频的要求,因此,视频压缩与编码技术的进步与革新始终没有停歇。
2、近年来人工神经网络发展到了深度学习(deep learning,dl)阶段,模仿人脑架构,使用贪婪逐层训练算法构建通过提取有效特征不断拟合数据。其强大的表达能力使得其在各个机器学习的任务取得极好的效果。目前很多端到端的深度学习视频编码模型在不断探索中被发掘。这些基于深度学习的视频编码器和传统编解码器相比能够在更低的码率下提供更高的重建视频质量。
技术实现思路
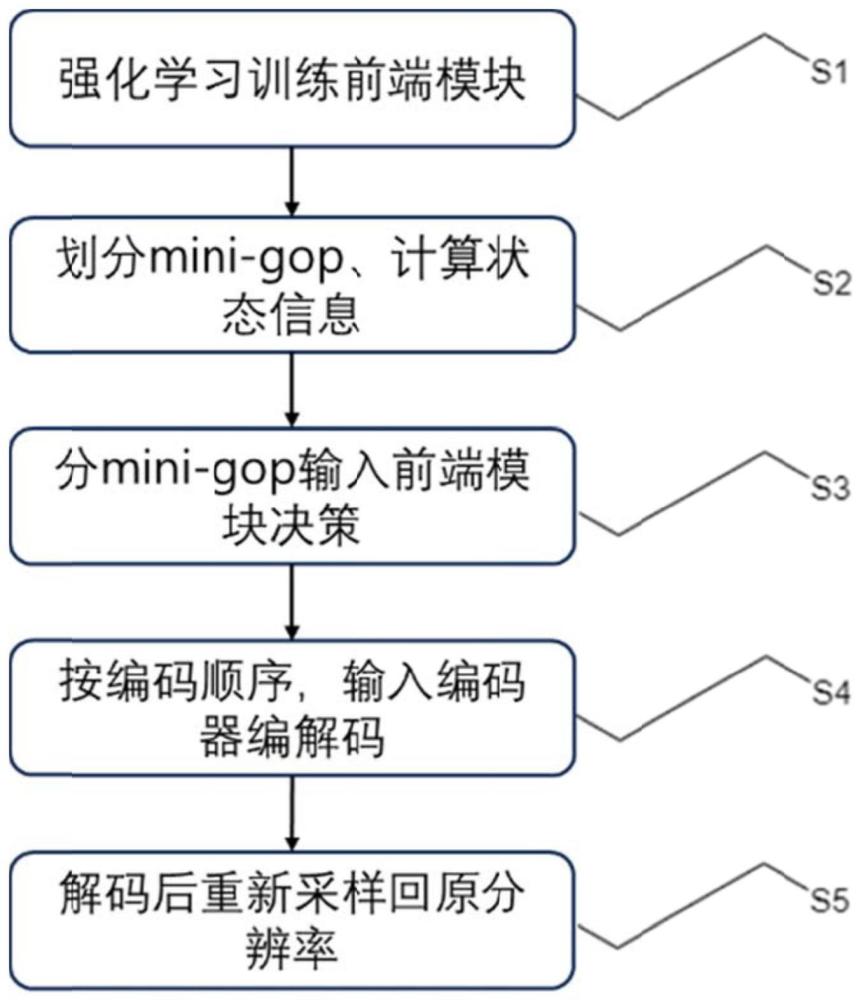
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种自适应采样融合的视频编码方法,包括以下步骤:
2、步骤1,训练阶段:设置训练所需的动作网络actor和评价网络critic,通过评价网络critic优化动作网络actor的训练过程,得到训练好的动作网络actor;
3、步骤2,测试阶段:将包含帧内容复杂度信息、视频时序信息的状态(state)输入到训练好的动作网络actor,得到编码序列每个子图像组的合理的动作对决策action;
4、步骤3,单个子图像组编码时,将其中的全部帧按照步骤2得到的动作对决策进行下采样和量化参数偏移设置后,再输入到编码器编码;
5、步骤4,相邻的子图像组按照编码顺序送进编码器中,当编码到当前子图像组的最后一帧时,相邻子图像组的两帧进行帧间编码时,将参考帧重新采样到与编码帧相同的分辨率;因为相邻子图像组的第一帧的编码和重建需要参考当前帧,因此在完成当前帧的编码后将重建帧重采样到下个子图像组预测出来的尺寸以供参考;
6、步骤5,每帧图像解码后,再重新采样回原分辨率,并且进行后处理增强,最终将全部帧按播放顺序组合输出。
7、步骤1包括:利用强化学习(reinforcement learning,rl)算法,在离散动作空间的柔性动作-评价算法框架(soft actor-critic,sac)中,将训练数据集的视频序列划分为两个以上相同长度的子图像组(mini group of picture,mini-gop),并通过高斯建模的方式计算每个子图像组的组内、组间的平均视频内容复杂度;接着以编码器作为环境进行实际编码交互,得到每一个子图像组编码后的码率-失真(rate-distortion,r-d)点,最后通过率失真优化(rate-distortion optimization,rdo)的奖励reward设置训练所需的动作网络actor和评价网络critic,对动作网络actor进行训练,并通过评价网络critic优化动作网络actor的训练过程,逐渐得到更加合理的动作对决策action,其中所述动作对包括下采样因子s和与量化相关的量化参数λ(在柔性动作-评价算法框架中,评价网络仅用于训练过程,预测动作网络输出的动作决策对所能获得的奖励分数,进而为动作网络的训练提供梯度)。
8、步骤1的训练阶段中,为了便于训练,同时适应超高分辨率的应用场景,所述对动作网络actor进行训练,并通过评价网络critic优化动作网络actor的训练过程,具体包括:
9、步骤1-1,在低分辨率数据集上(本发明中选择480x272的低分辨率数据集,选择这个分辨率的原因是一开始训练时选择比较低的分辨率能够训练得更快一点,但是也不能太小,因为进行了下采样(可以理解为缩小图像),如果太小的话下采样后图像信息丢失太严重可能导致模型预测的不准确。这个分辨率比较适中,而且长宽都是64的倍数,符合网络设置和要求,比较方便,不需要填充)训练动作网络和评价网络模型,依照环境交互输出的编码码率-失真性能与提前设置的目标编码码率-失真性能点的差值设计奖励,指导模型快速收敛到目标编码码率-失真性能点附近;
10、步骤1-2,在低分辨率数据集上,以平衡模型的码率和失真为标准(在低码率点注重降低失真,在高码率点注重降低码率),通过奖励分数的自适应调整来对模型参数进行微调;
11、步骤1-3,为了拟合大分辨率下决策出的参数对和编码输出的编码码率-失真性能之间的建模关系,在数据集(本发明中选择分辨率为1920x1088的数据集)上进行训练完成模型最后的收敛。
12、步骤1中,整个网络使用2个动作网络模型和4个评价网络模型;2个动作网络模型分别记为actor和actor_delay,4个评价网络模型分别记为critic1、critic1_delay、critic2和critic2_delay(delay表示延迟更新网络参数,在本发明的网络中设置每隔100步更新一次delay模型,以实现模型参数更加稳定的软更新);
13、在每一个训练批次epoch的计算过程中,首先从数据池data pool中取得一个批量batch的数据,输入到critic1和critic2中,分别预测当前动作能取得的奖励分数reward1'和reward2',取reward1'和reward2'中较小的一个奖励分数,记为reward',将预测得到的reward'与实际计算得到的奖励分数reward计算均方误差(mean square error,mse),再与当前动作分布的策略熵(strategy entropy)做加权和作为四个评价网络模型critic1、critic1_delay、critic2和critic2_delay的损失函数,并对reward’对应的那一组critici、critic_delayi的参数进行软梯度更新,i=1,2:0.005critici+0.995critic_delayi,接着将奖励分数reward'和策略熵entropy的加权和的负均值作为actor的损失函数,对actor和actor_delay同样做软更新:0.995actor+0.005actor_delay。
14、步骤1中,所述数据池data pool由训练过程的每次迭代过程产生的状态state、动作action、奖励reward、下一步的动作next_action、终止标识符over封装而成,并随着训练过程进行更新。
15、步骤2包括:使用原编码默认设置对视频序列的图像组mini-gop(group ofpicture,gop)进行编码,得到基础的编码结果,即码率-失真(rate-distortion,r-d)参考点,接着将测试视频序列划分为两个以上相同长度的子图像组,并计算包含图像内容信息、视频时序信息和前序决策信息的状态state,联合输入到训练好的动作网络actor中,得到编码序列每个子图像组的合理的动作对决策action。
16、步骤1和步骤2中,强化学习每一次训练迭代所需的状态信息包括:前一次动作选择的下采样因子s、前一次动作选择的量化参数λ、当前子图像组是否以帧内编码帧(intraframe)开始、当前子图像组处于整个视频中的位置、编码到当前子图像组剩余未分配的质量drem、编码到当前子图像组剩余未分配的码率rrem、当前子图像组的平均帧均值、当前子图像组的平均帧方差、当前子图像组与前一个子图像组的平均帧残差的均值、当前子图像组与前一个子图像组的平均帧残差的方差;
17、最终状态信息长度共计为10;
18、强化学习所需要的动作空间action包括:下采样因子s和量化参数λ,下采样因子s有[0.5,0.6,0.7,0.8,0.9,1.0]共6个离散值,量化参数λ包括在原编码器的λ取值范围内线性插值得到的8个离散值,则动作空间action共包含48个选择;
19、强化学习所需要的奖励分数reward为:
20、
21、其中r、d分别代表当前子图像组实际编码测试得到的码率和失真,rrem、drem分别代表编码到当前子图像组mini-gop剩余未分配的码率和失真,rtar、dtar分别代表目标码率和失真,β为与图像内容复杂度相关的超参数(默认为0.15);第一项是与当前子图像组状态信息中的剩余码率和剩余失真相关的分段函数;第二项表示标准化后的编码码率-失真r-d性能。
22、步骤3中,强化学习训练得到的模型结构简单,且无需输入原图,只需输入每一个子图像组mini-gop的状态信息,计算复杂度极低。
23、步骤4中,将帧内编码帧的下采样因子s固定为1,即针对i帧只更改量化参数λ,不进行下采样;另外值得注意的是对于编码器的内部结构并未做任何修改,仅在编码前后做处理,因此不会改变编码器本身特性。
24、步骤3和步骤5中,重新采样的方法仍是简单的插值方式,如bicubic双线性插值等。
25、步骤5中,所述后处理增强包括:在每帧图像解码后,利用参考帧对采样帧做质量增强,计算参考帧和采样帧的相似性,针对采样帧的每一个区域,都从参考帧中找到与其最相似的区域进行融合增强,从而补偿因为下采样后导致的高频信息丢失。
26、本发明还提供了一种基于强化学习的自适应采样视频编码装置,包括前端自适应下采样模块和修改后的编码器模块;
27、所述前端自适应下采样模块用于执行如下步骤:
28、步骤1,训练阶段:设置训练所需的动作网络actor和评价网络critic,通过评价网络critic优化动作网络actor的训练过程,得到训练好的动作网络actor;
29、步骤2,测试阶段:将包含帧内容复杂度信息、视频时序信息的状态(state)输入到训练好的动作网络actor,得到编码序列每个子图像组的合理的动作对决策action;
30、步骤3,单个子图像组编码时,将其中的全部帧按照步骤2得到的动作对决策进行下采样和量化参数偏移设置后,再输入到编码器编码;
31、所述修改后的编码器模块用于执行如下步骤:
32、步骤4,相邻的子图像组按照编码顺序送进编码器中,当编码到当前子图像组的最后一帧时,相邻子图像组的两帧进行帧间编码时,将参考帧重新采样到与编码帧相同的分辨率;因为相邻子图像组的第一帧的编码和重建需要参考当前帧,因此在完成当前帧的编码后将重建帧重采样到下个子图像组预测出来的尺寸以供参考;
33、步骤5,每帧图像解码后,再重新采样回原分辨率,并且进行后处理增强,最终将全部帧按播放顺序组合输出。
34、有益效果:本发明可以在这些现有的编码器基础上通过在mini-gop级别调整自适应采样因子和量化参数来进一步细化编码策略,从而提供更好的r-d性能;原理如下:通过强化学习可以为不同内容复杂度的mini-gop的选择合适的下采样因子和量化参数,前者可以大量减少视频的时间域和空间域冗余信息被编码从而降低码率,后者可以为下采样后分辨率较大的mini-gop提供较大的量化步长,进一步降低码率,为下采样后分辨率较小的mini-gop提供较小的量化步长,避免因为编码过程丢掉更多高频信息导致最后恢复视频质量较低。无论是单独调整下采样因子s还是量化参数λ会导致码率过高或视频质量较差的情况。同时分配合理的s和λ能很好的平衡码率和视频质量。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243991.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表