一种降低5G网络实时音视频传输延时的方法及系统与流程
- 国知局
- 2024-08-02 14:52:39
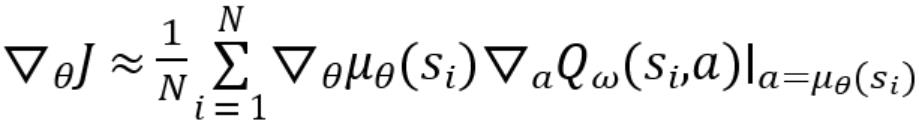
本发明涉及5g通信领域,具体为一种降低5g网络实时音视频传输延时的方法及系统。
背景技术:
1、强化学习是一种机器学习方法,其核心思想是通过代理(agent)与环境(environment)的交互学习来实现目标。在强化学习中,代理通过尝试不同的行动来最大化累积的奖励信号。这一过程通常被建模为马尔可夫决策过程(markov decision process,mdp),其中代理在每个时间步骤中观察环境的状态,并采取行动以影响环境,并获得奖励;5g的出现给移动网络带来了高带宽、低时延、本地分流等新的特性。同时,远程控制作为5g技术的先导,其对于智能化时代具备重要价值,5g可以满足远程控制应用中更多信息的同步需求。可以说,5g技术的成熟促进了远程操控的加速与落地。
2、现有技术中,在远程会议、直播、监控等传统应用场景中为提高传输的效率和抗弱网能力,封包协议通常都是基于标准rtp协议,底层采用udp协议。采用拥塞控制算法对网络状态进行估计,为发送pacing窗口和码率提出建议。使用差错编码抵抗rtp包的丢包,提高前向纠错能力,这样部分丢包可以通过差错解码进行恢复而不依赖重传。
3、并且,传统塞控制算法要是基于网络的时延带宽积,分别探测网络的最大带宽和最小时延,并认为两者乘积是网络上能够承载是数据最大容量,其优点在于可以抵抗随机的网络时延和丢包波动噪声,缺点在于最小时延测量时会降低吞吐,对于突发的网络恶化,需要更长的时间才能降到实际带宽。而在5g环境下随着装置位置的移动网络质量也会随之发生改变。尤其当移动装置处高速运行中,传统的塞控制算法显然无法快速灵敏的监测出网络质量的变化,因此也无法取得良好的视频效果。
技术实现思路
1、本发明的目的在于提供一种降低5g网络实时音视频传输延时的方法及系统,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:降低5g网络实时音视频传输延时的方法,所述方法包括以下步骤:
3、定义状态state;
4、定义动作action;
5、确定奖励信号reward signal;
6、选择强化学习算法进行训练代理。
7、优选的,定义状态state的具体操作包括:
8、选取以下8个参数来定义系统的状态,即要训练的代理agent所能感知的关于网络环境的信息:
9、1)信号强度signal strength;
10、2)信噪比signal-to-noise ratio,snr;
11、3)前20个时间步长的接收端接收数组总和,一个时间步为50ms;
12、4)前20个时间步长的平均数据包间隔;
13、5)前20个时间步长的平均rtt时延;
14、6)前20个时间步长的平均丢包率;
15、7)移动网络类型: 4g、5g sa、5g nsa;
16、8)移动网络频点。
17、优选的,定义动作action的具体操作包括:
18、定义代理可以采取的动作,动作影响系统的拥塞控制策略,代理执行以下三种动作:提高发送的码率、降低发送的码率以及强制模块切换网络:5g切4g、4g切5g。
19、优选的,确定奖励信号reward signal的具体操作包括:
20、将每 50ms 时间步长的奖励定义为,其中 r 是该时间步内的接收数据和单位为 kb,d为该时间步内的平均 rtt,单位为秒,l 为该时间步内的丢包率;c1、c2、c3权重参数,接收更多的数据包会得到奖励,因为这会提高的qoe,提供更好的影音质量,但延迟和丢包会受到惩罚,因为这些会降低 qoe,造成卡断和延时。
21、优选的,选择强化学习算法进行训练代理的具体操作包括:
22、选择ddpg作为使用的强化学习算法,ddpg算法的步骤:
23、随机噪声用来表示,用随机的网络参数和分别初始化 critic 网络和 actor 网络,复制相同的参数和,分别初始化目标网络和;初始化经验回放池;for序列do;初始化随机过程用于动作探索;获取环境初始状态;for时间步do;根据当前策略和噪声选择动作;执行动作,获得奖励,环境状态变为;将存储进回放池;从中采样个元组;对每个元组,用目标网络计算;最小化目标损失,以此更新当前 critic 网络;计算采样的策略梯度,以此更新当前 actor 网络;;更新目标网络:
24、
25、end for
26、end for。
27、一种降低5g网络实时音视频传输延时系统,其特征在于:所述系统由状态定义模块、动作定义模块、信号确定模块以及训练模块组成;
28、状态定义模块,定义状态state;
29、动作定义模块,定义动作action;
30、信号确定模块,确定奖励信号reward signal;
31、训练模块,选择强化学习算法进行训练代理。
32、优选的,所述状态定义模块,选取以下8个参数来定义系统的状态,即要训练的代理agent所能感知的关于网络环境的信息:
33、1)信号强度signal strength;
34、2)信噪比signal-to-noise ratio,snr;
35、3)前20个时间步长的接收端接收数组总和,一个时间步为50ms;
36、4)前20个时间步长的平均数据包间隔;
37、5)前20个时间步长的平均rtt时延;
38、6)前20个时间步长的平均丢包率;
39、7)移动网络类型: 4g、5g sa、5g nsa;
40、8)移动网络频点。
41、优选的,所述动作定义模块,定义代理可以采取的动作,动作影响系统的拥塞控制策略,代理执行以下三种动作:提高发送的码率、降低发送的码率以及强制模块切换网络:5g切4g、4g切5。
42、优选的,所述信号确定模块,将每 50ms 时间步长的奖励定义为,其中 r 是该时间步内的接收数据和单位为 kb,d为该时间步内的平均 rtt,单位为秒,l 为该时间步内的丢包率;c1、c2、c3权重参数,接收更多的数据包会得到奖励,因为这会提高的qoe,提供更好的影音质量,但延迟和丢包会受到惩罚,因为这些会降低 qoe,造成卡断和延时。
43、优选的,所述训练模块,选择ddpg作为使用的强化学习算法,ddpg算法的步骤:
44、随机噪声用来表示,用随机的网络参数和分别初始化 critic 网络和 actor 网络,复制相同的参数和,分别初始化目标网络和;初始化经验回放池;for序列do;初始化随机过程用于动作探索;获取环境初始状态;for时间步do;根据当前策略和噪声选择动作;执行动作,获得奖励,环境状态变为;将存储进回放池;从中采样个元组;对每个元组,用目标网络计算;最小化目标损失,以此更新当前 critic 网络;计算采样的策略梯度,以此更新当前 actor 网络;;更新目标网络:
45、
46、end for
47、end for。
48、与现有技术相比,本发明的有益效果是:
49、本发明提出的一种降低5g网络实时音视频传输延时的方法及系统,利用强化学习技术优化了移动网络拥塞控制,提高了控制可靠性,并减少了音视频传输的延时,为移动网络通信带来了显著的性能提升和用户体验改善;
50、利用强化学习,动态地调整网络传输策略,以应对移动网络中的拥塞情况;通过对移动网络信号指标和带宽变化的学习,可以智能地调整数据传输速率和路由,以最大程度地避免或减轻网络拥塞,从而提高网络性能和用户体验;
51、强化学习的应用使得控制策略能够根据不断变化的网络条件进行实时调整,从而提高了控制系统的可靠性;无论网络环境如何变化,都能够自适应地应对,确保网络传输的稳定性和可靠性;
52、通过优化拥塞控制策略,有效减少音视频传输过程中的延迟,这对于实时通信和多媒体传输应用非常重要,能够提升用户体验,减少传输过程中的卡顿和延迟,使通信更加流畅和自然。
本文地址:https://www.jishuxx.com/zhuanli/20240801/244126.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表