一种基于机器学习的基站位置预测方法与流程
- 国知局
- 2024-08-02 12:40:54
本发明涉及机器学习,更具体的说是涉及一种基于机器学习的基站位置预测方法。
背景技术:
1、通信基站是移动通信网络中最关键的基础设施,其参数准确性直接影响相关业务的最终效果,而基站参数通常是由各运营商维护人员手工录入,导致基站参数难免会出现关键信息错误缺失、数据更新不及时等问题。通过基站位置预测,可以更准确地评估基站的布局和分布,从而进行网络优化和资源合理分配。在应急情况下,如需要快速定位和修复故障基站,准确预测基站位置可以大大提高响应速度和修复效率。
2、目前基站位置预测的相关方法较少,如可以基于原始mr数据确定各竞对基站对应的目标重编码标识,根据目标重编码标识获取与竞对基站连接的预设数目的目标测量点,基于各目标测量点和预设反向三角定位算法预测竞对基站对应的基站位置,该方法需要mr数据支撑,其数据量大并且获取难度大,同时规则方法相比机器学习模型泛化能力较弱。再者可以根据粗定位数据获取用户接入时差,进而确定所述目标小区对应的邻区集合,基于工参台帐数据和邻区位置,计算邻区与周围小区距离的均值,生成多个邻区对应的交叠区域,将交叠最密集区域的几何中心点预测为目标小区的基站位置,该方法依然围绕通信规则预测基站经纬度,简单地将几何中心点作为预测位置,并未对周围小区的可靠性进行核验,直接影响最终的预测精度。
3、因此,如何提供一种精度高的基站预测方法是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于机器学习的基站位置预测方法,结合多方数据进行数据筛选,由高精度数据实现对低精度数据的纠正,提高了基站位置的预测精度。
2、为了实现上述目的,本发明采用如下技术方案:
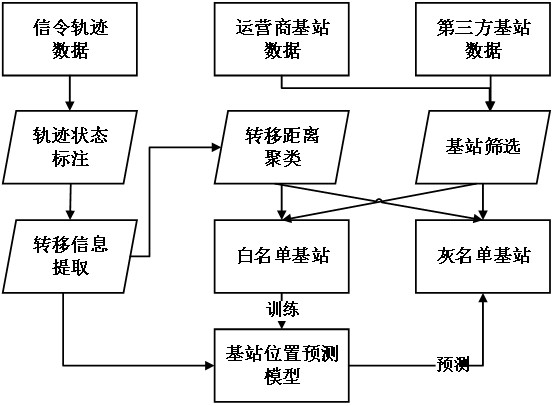
3、一种基于机器学习的基站位置预测方法,包括以下步骤:
4、s1:获取运营商基站数据、第三方基站数据和信令轨迹数据;
5、s2:计算基站在所述运营商基站数据和所述第三方基站数据中的间距,并根据预设的间距阈值进行区分,生成白名单基站表和灰名单基站表;
6、s3:根据所述信令轨迹数据对所述白名单基站表和所述灰名单基站表进行纠正;
7、s4:根据纠正结果,提取白名单基站的基站特征训练机器学习模型,并利用训练好的机器学习模型对灰名单基站的基站特征进行预测,得到灰名单基站的最终位置。
8、优选的,所述运营商基站数据和所述第三方基站数据由基站id和基站位置构成;所述信令轨迹数据是由基站id和时间戳构成的序列。
9、优选的,所述s3具体步骤包括:
10、s31:对信令轨迹数据进行状态标注,区分正常轨迹点和漂移轨迹点;
11、s32:从标注为正常轨迹点的轨迹数据中提取基站转移信息,根据基站转移信息对基站进行聚类,并计算转移距离期望;
12、s33:根据转移距离期望区分正常基站和位置偏移基站,对白名单基站表和灰名单基站表进行纠正更新。
13、优选的,所述s31具体包括:
14、依次计算信令轨迹数据中第一轨迹点至第二轨迹点间的移动速度,当移动速度超过预设的速度阈值时,第二轨迹点标注为漂移轨迹点。
15、依次计算信令轨迹数据中第一轨迹点、第二轨迹点和第三轨迹点形成的夹角及两两间距,当轨迹夹角小于夹角阈值,并且两段间距均大于距离阈值时,第二轨迹点标注为漂移轨迹点。
16、当不满足上述情况时,轨迹点为正常轨迹点。
17、优选的,所述基站转移信息为四元组,所述四元组包括原始基站id、目标基站id、原始基站与目标基站之间的距离以及原始基站与目标基站之间的转移次数。
18、优选的,所述s32中,计算转移距离期望,具体为:
19、s321:在基站转移信息中,选择一个未被标记的原始bs_idi作为起始点。
20、s322:找到在起始点半径r范围内所有目标基站bs_idj,并将它们加入到一个新的聚类中。
21、s323:对于新聚类中的每个目标基站bs_idj,找到其半径1km内所有基站bs_idk,并检查这些基站是否属于当前聚类;如果是,则将它们加入到当前聚类中;如果不是,则为它们创建新的聚类。
22、s324:重复s322和s323,直到所有基站都被访问过,每个基站形成至少一个聚类。
23、s325:计算每个基站bs_idi的转移距离期望。
24、
25、其中,为bs_idi对应的聚类,dj为该聚类中第j个转移距离,为dj的出现次数。
26、s326:将转移期望大于期望阈值的白名单基站更新到灰名单基站表,白名单基站表只保留转移期望和不同数据源间距均小于阈值的基站,期望阈值优选1km。
27、优选的,所述s4中在进行训练时,提取白名单基站表中转移次数最多的前n个目标基站的经纬度作为训练数据。
28、优选的,所述s4中,机器学习模型的训练步骤包括:
29、s41:初始化模型参数。
30、s42:将训练数据输入至机器学习模型中,进行迭代训练。
31、在每轮的迭代中,均添加一个新的决策树改进模型,并计算模型损失。
32、机器学习模型的目标函数为:
33、
34、
35、
36、其中,l是损失函数,优选均方误差,yi是第i个白名单基站的实际经纬度,yi’是第i个白名单基站的预测经纬度,ft(xi)是第t棵树对第i个白名单基站的预测经纬度,xi是第i个白名单基站的转移基站特征,是第t棵树的权重,γ是每棵树叶子节点的惩罚系数,k是叶子节点的数量,λ是权重的l2正则化系数,是树的权重向量。
37、然后根据模型损失进行参数优化:
38、对于每个节点,使用损失函数关于模型的梯度gi和海森矩阵hi来计算分裂的增益,并选择增益最大的分裂点。梯度表示损失函数随模型预测的变化率,海森矩阵表示损失函数的曲率。
39、其中,每个节点的计算分裂增益gain为:
40、
41、其中,l、r、p分别是左子节点、右子节点、父节点,yl’、yr’、yp’分别表示分裂后左子节点、右子节点、父节点的预测值。j表示相应子节点中的基站序号;gj表示该子节点中第j个基站的梯度,hj表示该子节点中第j个基站的海森矩阵。
42、分裂节点后,通过计算新树对每个样本的预测值来更新模型权重:
43、
44、其中λ 是正则化参数,用于控制树的复杂度。
45、s43:重复分裂节点的步骤完成迭代,得到训练好的机器学习模型。
46、进一步的,在进行迭代训练时,在每次迭代开始前,添加一颗决策树,进行后续的训练;所述训练好的机器学习模型为:
47、
48、其中,f(0)表示初始化的模型,t表示总迭代次数,t表示当前迭代轮次;是每棵树的权重,是第t次迭代的预测经纬度。
49、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于机器学习的基站位置预测方法,结合多方数据对各个基站的进行划分,得到白名单基站和灰名单基站;由白名单基站提供高精度的基站特征训练模型,并利用训练好的模型对灰名单基站进行预测,实现对灰名单基站位置的校正,提高了基站定位的精度。
本文地址:https://www.jishuxx.com/zhuanli/20240802/237299.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。