基于数据机理耦合建模的车路协同控制架构系统及构建方法
- 国知局
- 2024-08-05 11:39:31
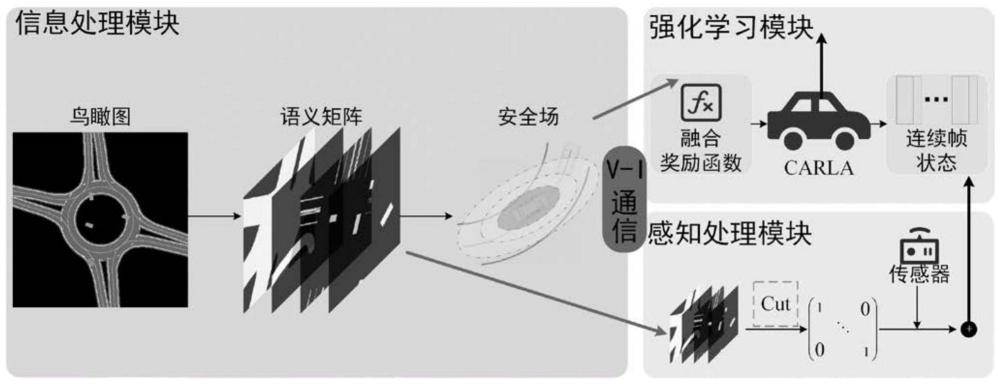
本发明属于交通运输领域,涉及一种基于数据机理耦合建模的车路协同控制架构系统及构建方法。
背景技术:
1、在自动驾驶领域,现有系统是巨大的信息物理系统,通过传统的机理建模方法实现高水平自动驾驶难度极大,其不足主要表现在环境感知受限、交互建模与场景理解困难、决策规划低效,以及驾驶安全性难以保证等方面,直接导致自动驾驶技术在复杂交通情境下的应用受到限制。
2、在应用过程中,自动驾驶算法的主要挑战可以总结为可信任难题和可解释性难题。对于可信任难题,主要体现为基于规则的方法严重依赖人工规则,难以应对复杂的驾驶环境。与之对应,端到端数据驱动方法又严重依赖于训练样本,对长尾案例的训练不足会导致严重的决策失误,从而引发对算法在应用过程中可信度的担忧。对于可解释性难题,主要是由于黑盒算法结构不透明性导致数据驱动方法可解释性不足,无法解释控制过程和决策依据。同时,控制算法缺乏解释将直接影响算法的评估和改进,进一步降低算法可信度。
3、引入联邦学习来解决控制算法可信任难题是一个新颖的想法,通过传输和聚合模型参数,提高算法的迁移性能和鲁棒性,从而缓解控制算法的信任危机。然而,联邦学习的参数聚合过程同样难以解释,这会抵消联邦学习带来的好处。总之,现有自动驾驶算法在平衡算法可信度和可解释性方面面临挑战。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于数据机理耦合建模的车路协同控制架构,提出了数据与机理融合驱动的多智能体系统建模方法,基于联邦强化学习的车路协同群体优化方法,建立了基于多维度经验共享的车辆决策模型参数更新技术,解决了纯数据驱动模型的可解释性、泛化性难题。利用路端优势搭建基于规则的行车安全场,实现了规则引导下的数据驱动训练;针对自动驾驶传统机理建模难度大的问题,提出了数据机理耦合驱动模型,构建了基于智能底盘的二次规划控制框架,创新提出基于底盘反馈的状态量输入,解决了纯数据驱动可信度存疑、依赖大规模数据、决策过程不透明不可解释等问题;基于人体感知度敏感区间,引入横向加速度、横摆角加速度和纵向加速度加权,构建了舒适性量化指标筛选针对当前环境的局部最优策略,通过合成受益于不同环境的全球共享模型,实现了样本效率和模型鲁棒性之间的平衡。
2、本发明,基于数据机理耦合建模的车路协同控制架构的技术方案包括三部分内容:规则引导下的耦合建模部分、数据机理耦合规划控制部分、数据机理耦合评估部分。
3、对于规则引导下的耦合建模部分,主要是路端处理鸟瞰图信息搭建行车安全场,通过建立融合奖励函数实现对数据驱动控制算法训练过程的指导。耦合建模部分包含路端信息处理模块、安全场建模模块,以及奖励函数建模模块,共三部分内容。
4、所述路端信息处理模块,主要是利用路端的视野优势,将鸟瞰图视角下的图像转化为语义鸟瞰图,并通过语义鸟瞰图中的动态信息在路端对智能网联汽车间的交互进行建模,最后将安全场信息和语义鸟瞰图通过v2i通信传输给车端。所述语义鸟瞰图为4通道的矩阵,包含静态的道路信息和车道线信息,以及动态的期望路径信息和车辆信息。
5、所述安全场建模模块,通过以下方程建立:
6、
7、
8、φ=ax/by=lv/wv
9、其中,ssta表示静态安全场场强,ca表示静态安全场场强系数,x0和y0表示静态风险中心o(x0,y0)的坐标,ε表示安全场形状系数,ax和by表示智能网联汽车外观系数,φ为智能网联汽车长宽比,lv表示车长,wv表示车宽。
10、当智能网联汽车运动时,高斯安全场的风险中心o(x0,y0)将随着车辆运动转移为新的风险中心o′(x′0,y′0):
11、
12、
13、其中,kv表示移动调节因子,且符号与运动方向有关,β表示网联汽车转移矢量与笛卡尔坐标系中坐标轴的夹角,表示网联汽车速度矢量。在动态安全场在风险中心转移作用下形成一个虚拟车辆,长为l′v,宽为w′v,sdyn表示动态安全场场强,新的长宽比表示为φ′=a′x/b′y=l′v/w′v。
14、所述奖励函数建模模块,从驾驶期望和驾驶安全性两个角度考虑:
15、r=rexpectation+rsafety
16、其中r表示奖励函数,rexpectation表示驾驶期望相关奖励函数,rsafety表示驾驶安全性相关奖励函数。
17、驾驶期望相关奖励函数包括横向和纵向两方面,首先是横向驾驶期望:
18、d0=min(||a28,28-bdesired route||2)
19、r1lateral=-log1.1(|d0|+1)
20、r2lateral=-10*|sin(radians(θ))|
21、rlateral=r1lateral+r2lateral
22、其中,d0表示离车道中心线距离,a28,28表示自车中心,bdesired route表示期望路径,r1lateral表示横向距离奖励函数,r2lateral表示航向角奖励函数,θ表示车端航向角偏差,rlateral表示横向驾驶期望奖励函数。
23、其次是纵向驾驶期望:
24、dmin=min(||a28,28-bx,y||2)
25、
26、
27、r2longitudinal=-|vego-9|
28、rlongitudinal=r1longitudinal+r2longitudinal
29、其中,dmin表示自动驾驶汽车之间的最小距离,bx,y表示他车中心,x表示碰撞时间,vego表示自车速度,r1longitudinal表示距离奖励函数,r2longitudinal表示速度奖励函数,rlongitudinal表示纵向驾驶期望奖励函数。
30、最后驾驶期望相关奖励函数通过以下公式建立:
31、rexpectation=rlateral+rlongitudinal
32、驾驶安全性相关奖励函数,由路端行车安全场从行车安全性以及行车侵略性两方面计算而得,首先是行车安全性:
33、
34、
35、其中,ri,j(t)表示智能网联汽车j对智能网联汽车i造成的行车风险,表示智能网联汽车j对于智能网联汽车i的场强,kc表示风险认知系数,表示智能网联汽车j在时刻t的速度,θi,j(t)表示智能网联汽车i和智能网联汽车j在时刻t的行驶夹角,rrisk表示行车风险相关奖励函数,frisk(ξ)表示行车风险积分,rthr表示风险阈值,τrc表示超过风险阈值的持续时间。
36、
37、
38、其中,rj,i(t′)表示智能网联汽车i对智能网联汽车j造成的行车风险,表示智能网联汽车i对于智能网联汽车j的场强,表示智能网联汽车i在时刻t′的速度,θj,i(t′)表示智能网联汽车j和智能网联汽车i在时刻t′的行驶夹角,ragg表示行车侵略性相关奖励函数,fagg(ξ)表示行车侵略性积分。
39、驾驶安全性相关奖励函数通过以下公式建立:
40、rsafety=rrisk+ragg
41、对于数据机理耦合规划控制部分,主要是构建基于底盘反馈的强化学习、智能底盘二次规划控制架构,通过汽车底盘机理模型与强化学习算法的实时动态耦合实现数据机理耦合规划控制。耦合规划控制部分包括车端信息处理模块、强化学习一次规划控制模块,以及智能底盘二次规划控制模块,共三部分内容。
42、所述车端信息处理模块,主要是各个智能网联汽车通过v2i通信从路端获取语义鸟瞰图信息,根据自车位置传感器信息将全局的语义鸟瞰图进行裁剪。裁剪后的语义鸟瞰图结合传感器信息、以及智能底盘二次规划控制结果,三部分状态量将会经过两个连续帧的堆叠后,作为强化学习一次规划控制模块的输入。
43、所述强化学习一次规划控制模块,主要是将各个智能网联汽车的车端信息处理模块输出的状态量作为强化学习神经网络的输入,输出对应的一次规划控制结果。所述一次规划控制过程包含方向盘控制、油门控制,以及刹车控制,其中:
44、steering∈[-1,1]
45、throttle∈[0,1]
46、brake∈[0,1]
47、其中,steering表示方向盘控制量,throttle表示油门控制量,brake表示刹车控制量,本发明的动作空间∈[-1,1]2,使用两种动作控制,即方向盘控制和油门-刹车控制,对于油门-刹车控制,[-1,0]表示刹车控制,[0,1]表示油门控制。本发明使用beta分布作为强化学习一次规划控制的输出:
48、beta=b(α,β)
49、其中,α和β表示beta分布的两个参数,本发明进一步从beta分布中采样得到相应的动作控制量。本发明之所以使用beta分布,是因为与无模型强化学习中常用的高斯分布相比,beta分布有几个优点。其中一个优点是它能动态模拟各种形状的样本分布。此外,与在正负两个方向上都延伸至无穷大的高斯分布不同,beta分布具有从0到1的有界支持,并且不需要强制约束。总之,beta分布提供了一种灵活、可变和有界的方法来模拟各种样本分布和处理有界变量,使其成为比高斯分布更优越的选择。
50、所述智能底盘二次规划控制模块,主要是根据强化学习一次规划控制模块的输出结合期望路径进行基于智能底盘多子系统的二次规划控制,二次规划控制输出将直接控制车辆的四轮转矩和转角,并且控制量会重新作为状态量的一部分传输给各个智能网联汽车的强化学习一次规划控制过程。二次规划控制过程将智能底盘子系统之间的协调与合作问题建立为考虑全局性能指标的优化问题,通过以下方程描述:
51、
52、其中,ui(t)表示智能子系统i在t时刻的控制量,ji、jj表示智能子系统i、j的总体成本函数,表示智能子系统i未来时刻的预测状态,表示智能子系统i未来时刻的控制量,表示邻居智能子系统j的假设状态,表示邻居智能子系统j的假设控制量,λi表示智能子系统之间成本函数的耦合系数,xi表示智能子系统i的预测状态,m表示智能子系统数量,wi表示智能子系统i的参考状态序列,ui表示智能子系统i的控制量序列,表示状态权重系数序列,表示智能子系统i的控制权重系数序列。
53、
54、其中,xi(k)表示智能子系统i未来k时刻的状态,xk表示智能子系统未来k时刻的状态序列,uk表示智能子系统j未来k时刻的控制量序列,表示智能子系统i控制量序列的转置矩阵,const表示常量,fii、gii、fij、gij、fjj、gjj、fjk、gjk分别表示计算矩阵,fij、gij构造如下:
55、
56、
57、其中,表示子智能体i的状态参数,表示子智能体i和子智能体j的耦合状态参数,表示耦合状态参数,np表示预测时域,nc表示控制时域,其他计算矩阵与其类似,由下面三式表示:
58、
59、
60、
61、其中,qi表示智能子系统i的状态权重系数,ri表示智能子系统i的控制权重系数,表示智能子系统j未来k时刻状态序列的转置矩阵,表示智能子系统j参考状态序列的转置矩阵,qj表示智能子系统j的状态权重系数,表示智能子系统j未来k时刻控制序列的转置矩阵,表示智能子系统j未来k时刻状态序列的转置矩阵,gji表示计算矩阵,结构如上所述。
62、对于数据机理耦合评估部分,主要是搭建舒适性量化指标,通过基于汽车底盘机理模型的神经网络筛选机制实现耦合评估和群体优化。耦合评估部分包括舒适性指标建模模块、神经网络筛选模块,以及神经网络参数聚合模块,共三部分内容。
63、所述舒适性指标建模模块,主要是根据车辆行驶时的状态变化程度,将横向加速度、横摆角加速度和纵向加速度,人体感知最明显的三个状态量作为衡量指标,依次绘制出人体感知度的敏感区间,以三个状态量的加权平方和作为量化指标。
64、
65、其中,表示基于智能底盘的人体舒适性量化指标,si(t)表示t时刻下横向加速度、横摆角加速度,以及纵向加速度,ωi表示横向加速度、横摆角加速度,以及纵向加速度的加权参数,i∈[0,m],其中m=3分别表示横向、横摆角,以及纵向。
66、所述神经网络筛选模块,主要是将搭建的基于智能底盘的人体舒适性量化指标作为筛选依据,筛选使得人体感知舒适性最好的智能网联汽车所对应的强化学习神经网络参数。所述筛选过程:
67、
68、其中,表示在时刻t下由智能网联汽车自身参数φt,i和另一辆智能网联汽车参数φt,i′聚合而来的新网络参数。
69、所述神经网络参数聚合模块,主要是通过路端v2i通信获取智能网联汽车的神经网络参数,并通过参数平均计算共享的神经网络参数,最后通过v2i通信下发给车端实现经验共享,直至网络收敛。所述参数平均按照以下方程进行:
70、
71、其中,表示m时刻下的共享神经网络参数,n表示智能网联汽车数量,φ′m,i表示m时刻下的第i辆智能网联汽车的神经网络参数。
72、本发明搭建基于数据机理耦合建模的车路协同控制架构的技术方案包括如下步骤:
73、步骤1:进行规则引导下的耦合建模。首先通过路端进行信息处理,利用路端的视野优势,将鸟瞰图视角下的图像转化为语义鸟瞰图,并通过语义鸟瞰图中的动态信息在路端对智能网联汽车间的交互进行建模,最后将安全场信息和语义鸟瞰图通过v2i通信传输给车端,然后在车端建立安全场,从路端角度对智能网联汽车交互过程实现建模。最后从驾驶期望和驾驶安全性两个角度考虑进行奖励函数建模。
74、步骤2:进行数据机理耦合规划控制。构建基于底盘反馈的强化学习、智能底盘二次规划控制架构,通过智能底盘系统与强化学习算法的实时动态耦合实现数据机理耦合规划控制。耦合规划控制过程包括车端信息处理、强化学习一次规划控制,以及智能底盘二次规划控制三部分内容。首先进行车端信息处理,各个智能网联汽车通过v2i通信从路端获取语义鸟瞰图信息,根据自车位置传感器信息将全局的语义鸟瞰图进行裁剪。裁剪后的语义鸟瞰图结合传感器信息、以及智能底盘二次规划控制结果,三部分状态量将会经过两个连续帧的堆叠后,作为强化学习一次规划控制的输入。然后通过强化学习进行一次规划控制,将各个智能网联汽车信息处理过程输出的状态量作为强化学习神经网络的输入,输出对应的一次规划控制结果。最后进行智能底盘二次规划控制,根据强化学习一次规划控制输出结合期望路径进行基于智能底盘多子系统的二次规划控制,二次规划控制输出将直接控制车辆的四轮转矩和转角,并且控制量会重新作为状态量的一部分传输给各个智能网联汽车的强化学习一次规划控制过程。
75、步骤3:进行数据机理耦合评估。搭建舒适性量化指标,通过基于汽车底盘机理模型的神经网络筛选机制实现耦合评估,以舒适性量化指标为依据实现对智能网联汽车控制效果的量化评估。
76、步骤4:进行神经网络筛选。将搭建的基于智能底盘的人体舒适性量化指标作为筛选依据,筛选使得人体感知舒适性最好的智能网联汽车所对应的强化学习神经网络参数。
77、步骤5:进行神经网络参数聚合。主要是通过路端v2i通信获取智能网联汽车的神经网络参数,并通过参数平均计算共享的神经网络参数,最后通过v2i通信下发给车端实现经验共享,直至网络收敛。
78、优选的,步骤1中,所述奖励函数建模从驾驶期望和驾驶安全性两个角度考虑:
79、r=rexpectation+rsafety
80、其中r表示奖励函数,rexpectation表示驾驶期望相关奖励函数,rsafety表示驾驶安全性相关奖励函数。
81、驾驶期望相关奖励函数包括横向和纵向两方面,首先是横向驾驶期望:
82、d0=min(||a28,28-bdesired route||2)
83、r1lateral=-log1.1(|d0|+1)
84、r2lateral=-10*|sin(radians(θ))|
85、rlateral=r1lateral+r2lateral
86、其中,d0表示离车道中心线距离,a28,28表示自车中心,bdesired route表示期望路径,r1lateral表示横向距离奖励函数,r2lateral表示航向角奖励函数,θ表示车端航向角偏差,rlateral表示横向驾驶期望奖励函数。
87、其次是纵向驾驶期望:
88、dmin=min(||a28,28-bx,y||2)
89、
90、
91、r2longitudinal=-|vego-9|
92、rlongitudinal=r1longitudinal+r2longitudinal
93、其中,dmin表示自动驾驶汽车之间的最小距离,bx,y表示他车中心,x表示碰撞时间,vego表示自车速度,r1longitudinal表示距离奖励函数,r2longitudinal表示速度奖励函数,rlongitudinal表示纵向驾驶期望奖励函数。最后驾驶期望相关奖励函数通过以下公式建立:
94、rexpectation=rlateral+rlongitudinal
95、驾驶安全性相关奖励函数,由路端行车安全场从行车安全性以及行车侵略性两方面计算而得,首先是行车安全性:
96、
97、
98、其中,ri,j(t)表示行车风险,表示智能网联汽车i和智能网联汽车j之间的场强,kc表示风险认知系数,表示智能网联汽车j在时刻t的速度,θi,j(t)表示智能网联汽车i和智能网联汽车j在时刻t的行驶夹角,rrisk表示行车风险相关奖励函数,frisk(ξ)表示行车风险积分,rthr表示风险阈值,τrc表示超过风险阈值的持续时间。
99、
100、
101、其中,rj,i(t′)表示行车风险,表示智能网联汽车j和智能网联汽车i之间的场强,表示智能网联汽车i在时刻t′的速度,θj,i(t′)表示智能网联汽车j和智能网联汽车i在时刻t′的行驶夹角,ragg表示行车侵略性相关奖励函数,fagg(ξ)表示行车侵略性积分。驾驶安全性相关奖励函数通过以下公式建立:
102、rsafety=rrisk+ragg
103、优选的,步骤2中,所述一次规划控制过程包含方向盘控制、油门控制,以及刹车控制,其中:
104、steering∈[-1,1]
105、throttle∈[0,1]
106、brake∈[0,1]
107、其中,steering表示方向盘控制量,throttle表示油门控制量,brake表示刹车控制量,本发明的动作空间∈[-1,1]2,使用两种动作控制,即方向盘控制和油门-刹车控制,对于油门-刹车控制,[-1,0]表示刹车控制,[0,1]表示油门控制。本发明使用beta分布作为强化学习一次规划控制的输出:
108、beta=b(α,β)
109、其中,α和β表示beta分布的两个参数,本发明进一步从beta分布中采样得到相应的动作控制量。本发明之所以使用beta分布,是因为与无模型强化学习中常用的高斯分布相比,beta分布有几个优点。其中一个优点是它能动态模拟各种形状的样本分布。此外,与在正负两个方向上都延伸至无穷大的高斯分布不同,beta分布具有从0到1的有界支持,并且不需要强制约束。总之,beta分布提供了一种灵活、可变和有界的方法来模拟各种样本分布和处理有界变量,使其成为比高斯分布更优越的选择。
110、优选的,步骤2中,所述智能底盘二次规划控制过程将智能底盘子系统之间的协调与合作问题建立为考虑全局性能指标的优化问题,通过以下方程描述:
111、
112、其中,ui(t)表示智能子系统i在t时刻的控制量,ji表示智能子系统的总体成本函数,表示智能子系统i未来时刻的预测状态,表示智能子系统i未来时刻的控制量,表示邻居智能子系统j的假设状态,表示邻居智能子系统j的假设控制量,λi表示智能子系统之间成本函数的耦合系数,xi表示智能子系统i的预测状态,wi表示智能子系统i的参考状态序列,ui表示智能子系统i的控制量序列,表示状态权重系数序列,表示智能子系统i的控制权重系数序列。
113、
114、其中,fii、gii、fij、gij、fjj、gjj、fjk、gjk分别表示计算矩阵,xi(k)表示智能子系统i未来k时刻的状态,xk表示智能子系统未来k时刻的状态序列,uk表示智能子系统j未来k时刻的控制量序列,表示智能子系统i控制量序列的转置矩阵,const表示常量。由下面三式表示:
115、
116、
117、
118、其中,qi表示智能子系统i的状态权重系数,ri表示智能子系统i的控制权重系数,表示智能子系统j未来k时刻状态序列的转置矩阵,表示智能子系统j参考状态序列的转置矩阵,qj表示智能子系统j的状态权重系数,表示智能子系统j未来k时刻控制序列的转置矩阵,表示智能子系统j未来k时刻状态序列的转置矩阵。
119、优选的,步骤3中,所述舒适性指标建模,主要是根据车辆行驶时的状态变化程度,将横向加速度、横摆角加速度和纵向加速度,人体感知最明显的三个状态量作为衡量指标,依次绘制出人体感知度的敏感区间,以三个状态量的加权平方和作为量化指标:
120、
121、其中,表示基于智能底盘的人体舒适性量化指标,si(t)表示t时刻下横向加速度、横摆角加速度,以及纵向加速度,ωi表示横向加速度、横摆角加速度,以及纵向加速度的加权参数,i∈[0,m],其中m=3分别表示横向、横摆角,以及纵向。
122、优选的,步骤4中,所述筛选过程:
123、
124、其中,表示在时刻t下由智能网联汽车自身参数φt,i和另一辆智能网联汽车参数φt,i′聚合而来的新网络参数。
125、优选的,步骤5中,所述参数平均按照以下方程进行:
126、
127、其中,表示m时刻下的共享神经网络参数,n表示智能网联汽车数量,φ′m,i表示m时刻下的第i辆智能网联汽车的神经网络参数。
128、本发明的有益效果:
129、(1)提出了数据与机理融合驱动的多智能体系统建模方法,基于联邦强化学习的车路协同群体优化方法,建立了基于多维度经验共享的车辆决策模型参数更新技术,解决了纯数据驱动模型的可解释性、泛化性难题;
130、(2)利用路端优势搭建基于规则的行车安全场,实现了规则引导下的数据驱动训练;针对自动驾驶传统机理建模难度大的问题,提出了数据机理耦合驱动模型,构建了基于智能底盘的二次规划控制框架,创新提出基于底盘反馈的状态量输入,解决了纯数据驱动可信度存疑、依赖大规模数据、决策过程不透明不可解释等问题;基于人体感知度敏感区间,引入横向加速度、横摆角加速度和纵向加速度加权,构建了舒适性量化指标筛选针对当前环境的局部最优策略,通过合成受益于不同环境的全球共享模型,实现了样本效率和模型鲁棒性之间的平衡。
本文地址:https://www.jishuxx.com/zhuanli/20240802/258652.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表