一种水轮机振摆预测方法、装置、电子设备及存储介质与流程
- 国知局
- 2024-08-05 11:59:27
本技术涉及水轮机振摆预测,尤其涉及一种水轮机振摆预测方法、装置、电子设备及存储介质。
背景技术:
1、随着我国能源结构改革的推进,水电站已经逐渐成为电力系统不可或缺的组成部分。在水电站中,水轮机是至关重要的生产设备,因此,水轮机的安全稳定运行直接影响水力发电厂的发电能力和电力供应的可靠性。为确保水电站的电气设备能够安全稳定运行,保障电力供应的可靠性,必须深入了解水轮机的状态和性能,并提前识别潜在的故障。传统水轮机检修方法包括事后检修和计划检修,事后检修是在设备故障发生后才进行维修,这种方法无法防止故障的发生。而计划检修则按照预定的维修计划进行,包括正常运行期间的维修。然而,这两种方法都存在缺陷,事后检修无法避免故障,而计划检修可能浪费人力资源并提高设备故障率。然而,由于多种机械和水力因素的综合作用,水轮机的故障可能导致振摆信号发生一定程度的变化。因此,振摆信号可以被视为直观反映机组运行状态的指标。
2、综合所述可知,如何利用水轮机振摆信号预测水轮机设备故障率是目前亟需解决的问题。
技术实现思路
1、本技术旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本技术的第一个目的在于提出一种水轮机振摆预测方法,以解决现有技术手段无法提前预警水轮机故障导致了电气设备故障和事故的不时发生等问题。
3、本技术的第二个目的在于提出一种装置。
4、本技术的第三个目的在于提出一种电子设备。
5、本技术的第四个目的在于提出一种计算机可读存储介质。
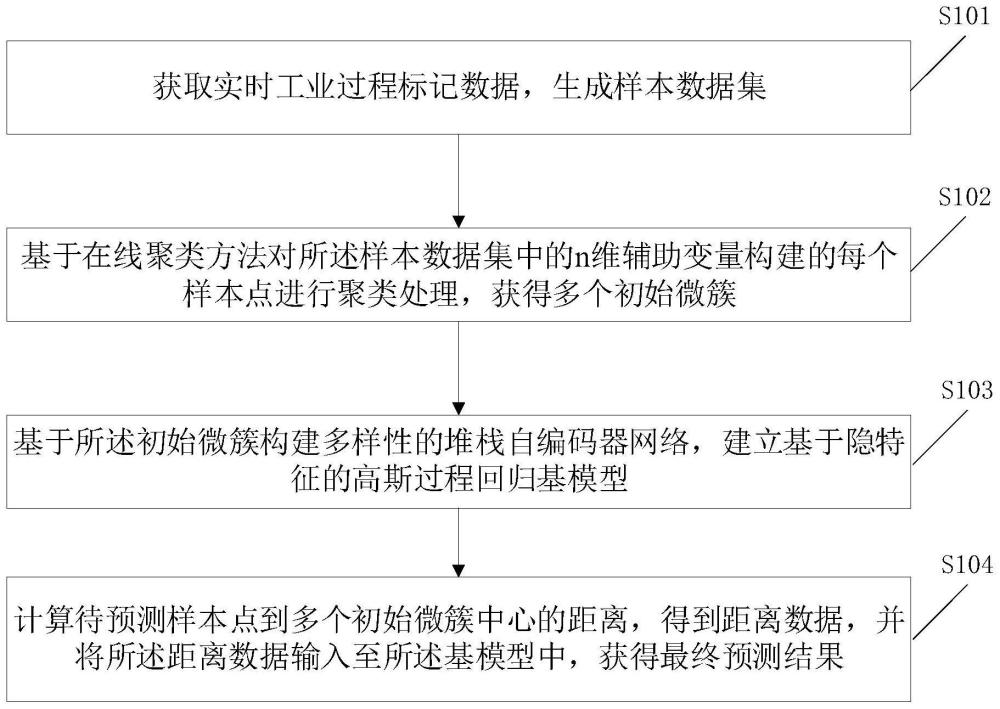
6、为达上述目的,本技术第一方面实施例提出了一种水轮机振摆预测方法,包括:
7、获取实时工业过程标记数据,生成样本数据集;
8、基于在线聚类方法对所述样本数据集中的n维辅助变量构建的每个样本点进行聚类处理,获得多个初始微簇;
9、基于所述初始微簇构建多样性的堆栈自编码器网络,建立基于隐特征的高斯过程回归基模型;
10、计算待预测样本点到多个初始微簇中心的距离,得到距离数据,并将所述距离数据输入至所述基模型中,获得最终预测结果。
11、优选地,还包括:
12、利用在线聚类方法对在线测试样本点进行聚类和即时学习处理,获得在线验证集;
13、利用所述在线验证集对所述基模型进行参数调整,获得更新后的基模型。
14、优选地,所述获取实时工业过程标记数据,生成样本数据集包括:
15、通过收集集散控制系统或离线检测的数据,生成历史数据集;
16、将所述历史数据集中符合预设值的变量作为输入变量,其他变量作为输出变量,生成样本数据集。
17、优选地,所述基于在线聚类方法对所述样本数据集中的n维辅助变量构建的每个样本点进行聚类处理包括:
18、给定一个数据集,将聚类中心到聚类边缘的最大距离作为聚类半径,当数据点之间的距离小于所述聚类半径且数据量达到最小密度阈值时,获得集群;
19、将所述集群中所有样本特征的平均值作为聚类中心;
20、计算新查询样本与所述聚类中心的欧式距离,若所述新查询样本与所述聚类中心的欧式距离不大于所述聚类半径,则将所述新查询样本存储至第m个集群中,基于软化分策略将样本点存入对应集群中,完成聚类更新;
21、若所述新查询样本与所述聚类中心的欧式距离大于所述聚类半径,则将所述新查询样本作为离群值,计算每个离群值之间的距离,若每个离群值之间的距离小于所述聚类半径的离群值数量达到最小密度阈值,则生成新集群。
22、优选地,所述基于所述初始微簇构建多样性的堆栈自编码器网络,建立基于隐特征的高斯过程回归基模型包括:
23、设置多样性的堆栈自编码器网络初始参数,采用随机重采样法对每个微簇划分出2/3的样本集作为该簇的预训练集进行预训练;
24、所述预训练结束后再网络的输出端加一个输出层,以标记样本的主导变量与其映射值之间的均方误差作为多样性的堆栈自编码器网络的损失函数,通过批量梯度下降法和反向传播算法调整所述多样性的堆栈自编码器网络的参数;
25、基于预训练的多样性的堆栈自编码器网络,获得微簇原始数据对应的隐特征数据,基于所述隐特征数据构建基模型。
26、优选地,所述计算待预测样本点到多个初始微簇中心的距离,得到距离数据,并将所述距离数据输入至所述基模型中,获得最终预测结果包括:
27、基于欧式距离计算待预测样本点和微簇聚类中心的距离,评估所述待预测样本点和微簇代表局部相关性;
28、对所述局部相关性进行自适应加权预测处理,得到最终预测结果。
29、优选地,所述利用所述在线验证集对所述基模型进行参数调整,获得更新后的基模型包括:
30、将待预测样本点与各微簇聚类中心的距离排序,选取符合预设值的聚类局部区域;
31、挑选与所述待预测样本点一致的相似样本作为验证集,并将所述验证集作为标记数据集对相关性最大聚类局部区域对应的多样性的堆栈自编码器网络参数进行微调,获得更新后的基模型。
32、为达上述目的,本技术第二方面实施例提出了一种水轮机振摆预测装置,包括:
33、数据获取模块,获取实时工业过程标记数据,生成样本数据集;
34、聚类处理模块,基于在线聚类方法对所述样本数据集中的n维辅助变量构建的每个样本点进行聚类处理,获得多个初始微簇;
35、模型构建模块,基于所述初始微簇构建多样性的堆栈自编码器网络,建立基于隐特征的高斯过程回归基模型;
36、预测模块,计算待预测样本点到多个初始微簇中心的距离,得到距离数据,并将所述距离数据输入至所述基模型中,获得最终预测结果。
37、为达上述目的,本技术第三方面实施例提出了一种电子设备,包括:处理器,以及与所述处理器通信连接的存储器;
38、所述存储器存储计算机执行指令;
39、所述处理器执行所述存储器存储的计算机执行指令,以实现上述任一项所述的方法。
40、为达上述目的,本技术第四方面实施例提出了一种计算机可读存储介质,包括所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现上述任一项所述的方法。
41、本技术提供的一种水轮机振摆预测方法,基于在线聚类方法对所述样本数据集中的n维辅助变量构建的每个样本点进行聚类处理,通过在线动态聚类实现过程数据流样本集群的自动生成,从而实现过程状态的在线动态识别,基于所述初始微簇构建多样性的堆栈自编码器网络,建立基于隐特征的高斯过程回归基模型,充分发挥深度学习在挖掘复杂过程数据特征方面的优越性,实现了利用水轮机振摆信号预测水轮机设备故障率,避免了因水轮机故障导致水电站安全事故的发生。
42、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240802/260473.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表