敏感言论识别模型构建方法、设备及介质
- 国知局
- 2024-08-08 16:53:02
本文件涉及敏感言论识别,尤其涉及一种敏感言论识别模型构建方法、设备及系统。
背景技术:
1、关于自动性别歧视言论识别的研究已经取得了巨大的进展。大多数优秀的研究采用了基于transformer的先进深度学习模型使得识别性能显著提升。然而,仅少数研究关注于性别歧视文本的理论、领域、类别、标签和分布等相关问题。这些横跨深度学习领域的研究被严重忽视,而这些研究对于提升模型的泛化性能至关重要。目前存在的问题主要集中在以下几个方面:
2、(1)忽略了社交媒体领域知识的重要性。研究表明,随着社交媒体影响力的扩大,带有性别歧视文本的数据大多产生于社交媒体,在该领域造成的影响也愈加严重。而现有的深度学习方法在处理自然语言处理任务时候常常使用领域知识比重较为稀疏预训练模型,使得预训练模型并没有较强语义和编码的能力更准确地处理性别歧视样本,从而无法提取出性别歧视文本中的特征,导致下游分类器性能受限。
3、(2)忽略了心理学相关理论的重要性。社会偏见学中的“拟人化理论”认为,当人们对某个群体持有负面的刻板印象时,他们可能更倾向于将该群体的行为或特征归因于内部因素。该理论中“歧视锚点”是指在对待某个群体时,存在偏见或负面刻板印象的具体特征或行为。cryan等人通过人工构建偏见词表或emoji词表来增强语言特征,以这样的方式将深度学习和偏见学理论建立联系,结果表明模型性提升较为明显。然而,类似的工作较少,且cryan等人的方法存在一些局限性,无法实现自动化,并忽略了语义和上下文等重要特征。
4、(3)缺乏性别歧视样本类别分布和难易程度不均衡的研究。最新的一些工作表明,性别偏见样本在客观世界中类别分布不均衡,并且大部分数据集同样存在这个问题。同时,随着社交媒体网络不断发展,需要细化性别歧视类别的粒度,从而提高对自动化工具使用的决策的可解释性、信任和理解,这对于分类模型来说增加了不少难度。许多方法仅仅依赖于使用参数更多的语言模型来解决这一问题,但往往性能提升十分微弱,且还存在着内存占用大和推理速度慢的缺点。
技术实现思路
1、本发明提供了一种敏感言论识别模型构建方法、设备及系统,旨在解决上述问题。
2、本发明提供了一种敏感言论识别模型构建方法,其特征在于,包括:
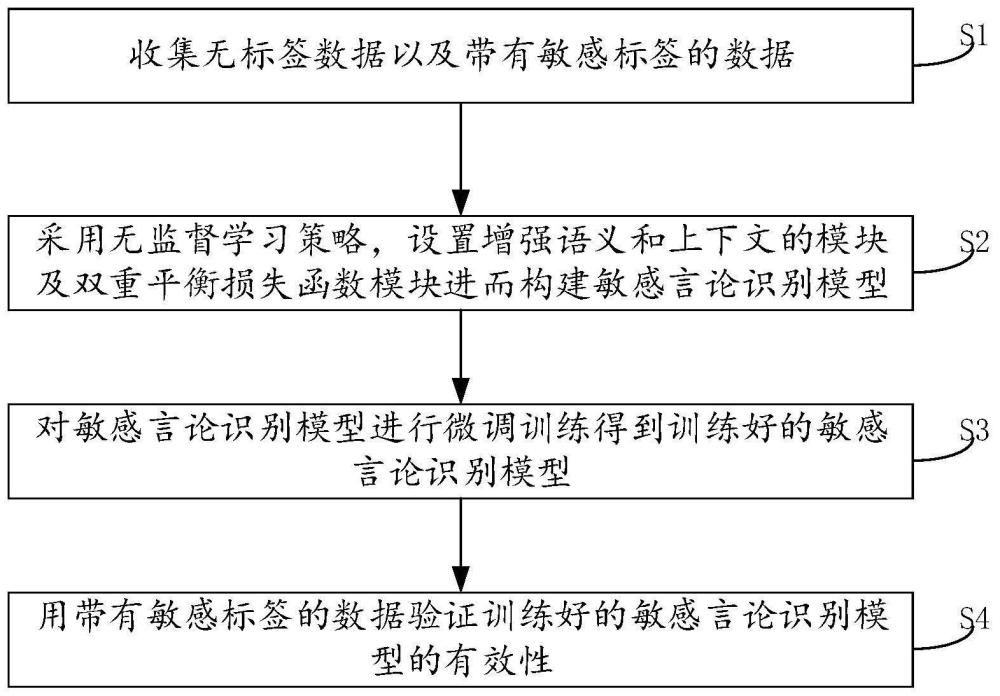
3、s1、收集无标签数据以及带有敏感标签的数据;
4、s2、采用无监督学习策略,设置增强语义和上下文的模块及双重平衡损失函数模块进而构建敏感言论识别模型;
5、s3、对敏感言论识别模型进行微调训练得到训练好的敏感言论识别模型;
6、s4、用带有敏感标签的数据验证训练好的敏感言论识别模型的有效性。
7、本发明实施例还提供了一种电子设备,包括:
8、处理器;以及,
9、被安排成存储计算机可执行指令的存储器,所述计算机可执行指令在被执行时使所述处理器执行如上述敏感言论识别模型构建方法的步骤。
10、本发明实施例还提供了一种存储介质,用于存储计算机可执行指令,所述计算机可执行指令在被执行时实现如上述敏感言论识别模型构建方法的步骤。
11、本发明具备如下有益效果:
12、本发明公开的敏感言论识别模型构建方法首先采用无监督学习策略来增强预训练语言模型在理解含偏见样本方面的深度,以实现对社交媒体领域知识的增强。然后,通过增强语义和上下文的方法,提高模型对性别偏见文本中歧视锚点的全局关注度。最后,敏感言论识别模型构建方法缓解当前社交媒体大量性别歧视样本中类别样本不均衡和难易不均衡的问题。
13、在验证阶段的对比实验中,本方法在三个子任务中的性能表现均显著超越了多个强大的基线模型,如:deberta-v3-base、roberta-base和roberta-large,这一结果不仅充分验证了本发明实施例提供的敏感言论识别模型构建方法的有效性。并且证明了从性别歧视理论和数据分布的角度出发能激发模型在性别歧视识别这项艰难任务的能力,同时提高对自动化模型决策的可解释性。
14、在官方评测阶段实验中,所展示的统计指标,如第一四分位数、平均值、中位数以及第三四分位数等统计排位上也展现出了显著的技术优势。这些指标共同证明了本申请公开的敏感言论识别模型构建方法在多方面的优势,为后续研究提供了有力的参考。
技术特征:1.一种敏感言论识别模型构建方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述s2具体包括:
3.根据权利要求2所述的方法,其特征在于,所述s21中采用遮蔽语言模型进行无监督训练,得到向量序列b具体包括:
4.根据权利要求3所述的方法,其特征在于,所述s22具体包括:
5.根据权利要求4所述的方法,其特征在于,所述s23具体包括:
6.根据权利要求5所述的方法,其特征在于,所述通过考虑样本难易不平衡及类别不平衡问题构建双重平衡损失函数,具体包括:
7.根据权利要求1所述的方法,其特征在于,所述s1进一步包括:对无标签数据进行清洗,并划分为训练集和验证集,将带有敏感标签的数据划分为任务递增的三个子任务数据集,将每个子任务数据集按照预定比例划分为训练集、验证集和测试集。
8.根据权利要求7所述的方法,其特征在于,所述s4具体包括:
9.一种电子设备,包括:
10.一种存储介质,用于存储计算机可执行指令,所述计算机可执行指令在被执行时实现如权利要求1-8中任一项所述敏感言论识别模型构建方法的步骤。
技术总结本发明提供了一种敏感言论识别模型构建方法、设备及系统,其中,方法包括:收集无标签数据以及带有敏感标签的数据;采用无监督学习策略,设置增强语义和上下文的模块及双重平衡损失函数模块进而构建敏感言论识别模型;对敏感言论识别模型进行微调训练得到训练好的敏感言论识别模型;用带有敏感标签的数据验证训练好的敏感言论识别模型的有效性。本申请的双重平衡损失函数充分考虑样本难易不平衡以及类别不平衡的问题,以提高敏感言论识别模型的识别性能。技术研发人员:汪洋涛,黄鹏龙,谢延昭,汤茂斌,彭伟龙,范立生,方美娥受保护的技术使用者:广州大学技术研发日:技术公布日:2024/8/5本文地址:https://www.jishuxx.com/zhuanli/20240808/270972.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表