基于LoRA的情感分析方法
- 国知局
- 2024-08-19 14:19:08
本发明涉及人工智能,尤其是涉及一种基于lora的情感分析方法。
背景技术:
1、在数字化时代的背景下,情感分析成为了企业和服务提供商关注用户体验的关键工具。其在社交媒体分析、情感驱动的内容推荐、舆情监控等方面得到广泛应用,不仅发挥着重要作用,还蕴含着巨大的商业潜力和应用前景。
2、文本情感分析按照处理文本的粒度不同可以划分为三个层次:篇章级情感分析、句子级情感分析和方面级情感分析。但无论是篇章级还是句子级情感分析,它们都只假设一段文本只包含一种情感色彩,并不能充分反映文本中不同对象的更细致的情感表达。在计算层面的发展来看又可以将其划分为基于词典的统计方法、基于机器学习的方法、基于传统的深度学习方法以及基于预训练模型的方法。基于词典、机器学习以及传统的深度学习方法普遍存在数据依赖性强、标注成本高昂、泛化能力有限、无法充分考虑文本的上下文信息等缺陷。本发明是基于预训练模型的方面级情感分析。
3、现有基于预训练模型的高效微调方法大都是通过冻结预训练模型增加模型深度来实现的,这类方法无疑会增加模型在推理阶段的复杂度。
技术实现思路
1、本发明的目的是提供一种基于lora的情感分析方法,以解决上述背景技术中存在的问题,提出一种在不增加推理时间的前提下实现高效微调,在语义提取、下游任务上的表现能力方面均有所提升的情感分析方法。
2、为实现上述目的,本发明提供了一种基于lora的情感分析方法,包括以下步骤:
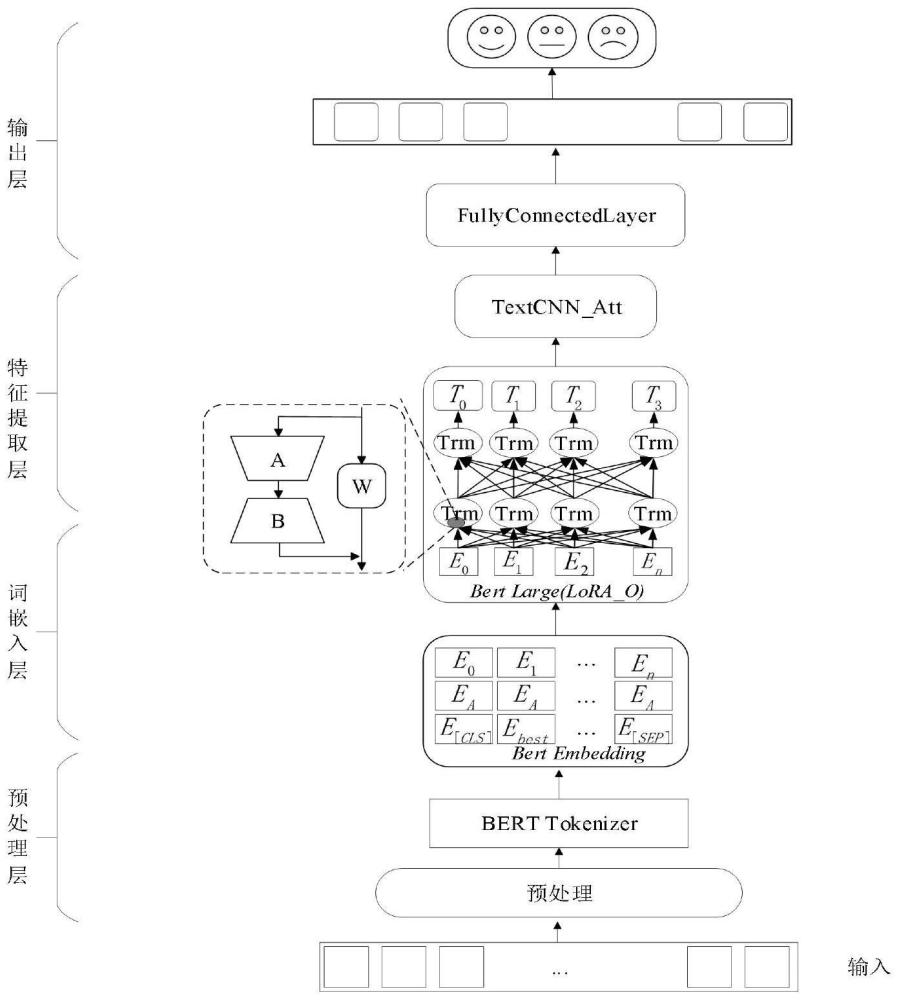
3、s1、在预处理层对数据进行清洗,并使用bert预训练模型对输入样本进行分词;
4、s2、在词嵌入层对分词后的输入样本经过向量表示层,映射为高维连续的词向量以捕捉更丰富的语义信息;
5、s3、在特征提取层将高维词向量作为特征提取层的输入,进一步提取出更具表现力的特征向量;
6、s4、在输出层将生成的特征向量作为最终输入样本表示,并通过情感分类层对文本情感进行极性判断。
7、优选的,s1中,采用工具包对输入样本进行分词得到分词结果s=[t1,t2,...tn],一般以一个完整的单词或符号作为分割标准。
8、优选的,s2的词嵌入层具体步骤如下:
9、s21、在s1中获得一个由n个分词组成的原始样本输入s=[t1,t2,...tn],其中,ti为按照分词规则分解的第i个分词;
10、s22、在原始样本输入的首尾分别插入[cls],[sep]特殊标记,得到初始序列seq={[cls],t1,t2,t3,...tn,[sep]};
11、s23、根据bert预训练模型训练好的词汇表将初始序列中每个标记及分词映射为一个id,若干id组成模型的输入序列;
12、s24、若输入序列长度小于模型的预设长度则使用特殊标记填充至预设长度,然后为每个分词分配一个段id(segmentid),通常用0、1来区分两个不同的句子段;
13、s25、根据分词在句子中的位置,为每个分词分配一个位置id(positionid),为模型提供输入样本的位置信息;
14、s26、将处理好的原始样本输入(包括输入序列、段落信息、位置信息)输入到bert预训练模型,得到每个分词的隐藏状态,将模型输出的隐藏状态转换为词嵌入向量用于后续的任务。
15、优选的,s3中采用lora方法通过低秩矩阵分解来模拟原始权重参数的改变量,具体为在原有网络中引入一个旁路结构,旁路结构由一个低秩矩阵a和低秩矩阵b组成,将低秩矩阵a和低秩矩阵b的乘机的增量作为原始权重矩阵w更新的参照,在不增加额外训练参数和推理时间的情况下,加大模型训练中的可控元素,提升了模型的训练效果,在训练过程中更新低秩矩阵a和低秩矩阵b的同时也利用其乘机的增量动态地更新训练原始权重矩阵w,更新过程如下式:
16、
17、h=wt+1·x+at+1bt+1·x
18、其中,wt为第t时间步的原始权重,at,bt分别是第t时间步的两个低秩矩阵,λ为权重矩阵w更新的比例,若采用梯度下降的方式来更新w,则wt+1=wt-ηg(w),其中η为学习率,g(w)为矩阵的梯度,预训练矩阵的权重增量就为δw=-ηg(w),即全参数微调w矩阵,lora算法最初提出思想便是低秩矩阵a,b的乘机来代表原始权重矩阵w的最终增量,因此在每一步中利用a,b乘机的增量来作为预训练权重矩阵w更新的基数是可行的。通过这种方法,能够在不增加可训练参数数量的前提下,有效地扩展模型的可控性,达到增强模型在提取语义方面能力的目的。
19、优选的,为提升模型在下游任务上的表现能力,结合textcnn方法和注意力机制设计一种在不同感受野下捕捉的局部特征相对于全局信息的特征表示模块,确保模型能够同时关注不同粒度下的局部文本信息和全部信息。输入样本在经过bert预训练模型词嵌入和特征提取后得到具有文本表达能力的特征句向量e=(e1,e2,e3,...,en),将其作为当前特征表示模块的输入,textcnn方法利用不同大小的卷积核来捕捉文本中不同粒度的局部特征,对于一个已经词向量化后的句向量x∈rn×k,其中,n表示句向量中的句子长度,k表示嵌入维度,在textcnn中计算过程如下式:
20、ci=f(w·xi;i+h-1+b)
21、其中,w∈rh×k,h表示卷积核的高度,k表示卷积核的宽度,xi;i+h-1表示由输入句向量的第i行词向量到第i+h-1行词向量拼接而成的h×k维局部向量,b为偏置项,f为非线性函数;
22、卷积核与局部向量xi;i+h-1进行点积运算提取得到局部特征ci,卷积核由上往下依次滑动与局部向量相乘得到局部特征ci到ci-h+1,然后拼接起来得到c=[c1,c2,...cn-h+1]表示一次卷积操作得到了一次特征向量。
23、优选的,卷积操作在一定程度上能够表示短语或某些局部信息,并不能关注句子的整体信息,因此在每个卷积核做完卷积操作之后,接入多头注意力机制模块,为局部向量注入全局信息,进一步提升模型的泛化能力和表示能力,多头注意力机制的计算过程如下式:
24、
25、hi=attention(wi(q)·q,wi(k)·k,wi(v)·v)
26、h=w0·[h1,h2,h3,...,hn]t
27、其中,wi(q),wi(k),wi(v)分别对应于query,key,value输入向量的线性变换参数矩阵,w0为多头输出拼接向量的线性变换矩阵,hi为第i个注意力头的隐层输出,h为多头注意力机制模块的最终输出。
28、优选的,为了避免在引入特征表示模块之后可能出现的深度神经网络退化问题,还加入了残差结构,这种退化问题通常表现为深度神经网络难以充分发挥其强大的特征提取力,从而导致模型性能下降。残差结构的引入旨在通过直接连接层与层之间的输出,来缓解梯度消失和梯度爆炸的问题,从而保持网络的深度和复杂度,其在当前大小的卷积核下的最终输出由下式得出:
29、ci=f(x+mutiheadattention(textcnn(x)))
30、其中,x为textcnn网络层的输入,f非线性激活函数,经过当前模块的最终输出如式:
31、
32、其中,i为卷积核的个数,ci为在卷积核i下得到的卷积结果,pooling函数为池化层。
33、优选的,s4中,将之前提取出来的特征向量经由全连接层再结合softmax函数将网络输出转换为对应的分类类别的概率分布,具体的计算过程如下式:
34、lineroutl=ol·wl+bl
35、out=softmax(lineroutl)
36、class=argmax(out)
37、其中,ol为当前模型特征提取层的输出,wl为全连接层的权重矩阵,bl为全连接层的偏置项,在借助softmax函数后得到当前词向量表示对应于分类类别中每个类别的概率后,最后利用argmax函数求出概率值最大的类别的索引,将索引值映射到具体的情感极性,就是模型对当前输入样本的情感类别的判定。
38、因此,本发明采用上述一种基于lora的情感分析方法,具备以下有益效果:
39、(1)在微调过程中参照低秩矩阵乘机的增量更新原始权重,在增加可控因素的同时做到和全模型微调相同的推理复杂度;
40、(2)在特征提取层加入结合了注意力机制的textcnn模块以进一步提取特征,确保模型能够同时关注不同粒度下的局部文本信息和全部信息,进一步提升模型的泛化能力;
41、(3)引入残差结构,通过直接连接层与层之间的输出,来缓解梯度消失和梯度爆炸的问题,从而保持网络的深度和复杂度,避免在引入textcnn模块和注意力机制模块后可能出现的深度神经网络退化问题。
42、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本文地址:https://www.jishuxx.com/zhuanli/20240819/274743.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表