空时多尺度交互的视频摘要生成方法及系统
- 国知局
- 2024-08-22 15:07:46
本发明涉及图像处理,具体为空时多尺度交互的视频摘要生成方法及系统。
背景技术:
1、自媒体时代背景下,每天都有大量的视频产生,仅仅依靠人工无法完成如此海量视频的监管。视频摘要旨在将冗长的视频压缩为更短、更易管理的版本,是一种可行的解决方案。然而,传统的视频摘要方法希望使用一个标准模型来总结所有类别的视频,这需要大量的人工标注数据进行训练,而人工标注的成本很高,因此有效利用可用数据资源至关重要,另一方面,现有的视频摘要方法忽视了一点,即相同类别视频的视频其摘要的重点是类似的,而不同类别的视频很有可能是不同的,因此摘要的重点可以根据视频片段的内容和上下文的不同而大不相同。摘要应捕捉视频的精华,同时满足观众的兴趣和需求,因此理解观众的期望和视频内容的关键要素对于制作有效的摘要至关重要。
2、现有技术中大多使用单一分支预测摘要,例如分别使用动态图和变换器架构的单一分支捕获空间-时间依赖关系,这些方法仅依赖于输入特征的单一尺度操作,这样的特征对于少样本视频摘要来说可能并不足以提供准确的信息。
技术实现思路
1、本发明的目的在于提供空时多尺度交互的视频摘要生成方法及系统,能够将传统视频摘要生成技术改造成面向少样本场景的视频摘要生成技术,模型仅需要少量的样本即可快速掌握同类视频的摘要生成所需关注的重点,对于训练中没有见过的类别可以快速泛化。并且利用双分支结构获取空时特征,并结合多尺度交互方式充分利用空时特征,为生成摘要提供多尺度的信息。
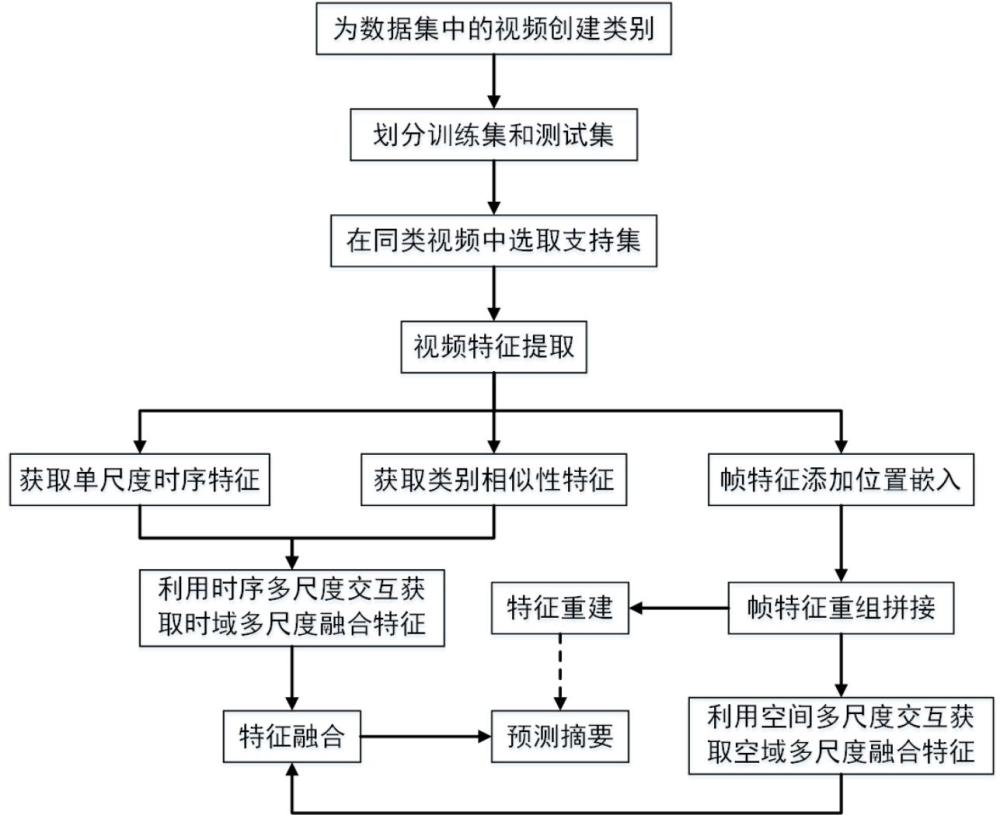
2、根据本发明的第一方面,为实现上述目的,本发明提供如下技术方案:空时多尺度交互的视频摘要生成方法,具体包括以下步骤:
3、接收待处理视频构成数据集,对数据集进行改造,为数据集中每个视频添加类别,并将视频按照类别划分训练集和测试集,要求测试集中的类别不能在训练集中出现;
4、根据划分的训练集和测试集,分别为其查询集选取支持集视频;
5、根据groundtruth为选取的支持集视频生成摘要,支持集视频与支持集摘要共同组成支持集;
6、将获取的查询集、支持集和支持集摘要输入到googlenet网络中获取第五个池化层的特征作为视频帧级特征,并作为空时多尺度交互模型的输入;
7、将获取的视频帧级特征输入时域多尺度模块中的注意力网络,计算得到单尺度时序特征;
8、将获取的支持集视频帧级特征和支持集摘要特征做矩阵乘法,获得类别相似性特征,输入到时域多尺度模块中;
9、将获得的单尺度时序特征和类别相似性特征输入时序多尺度交互组件,得到时域多尺度融合特征;
10、将获得的查询集特征、支持集特征和支持集摘要特征输入到空域多尺度模块中,并将特征向量分别均分为相同大小的片段,并为每个片段添加位置嵌入,利用一个全连接层对视频特征和位置嵌入进行融合;
11、将融合后的特征进行重组,将等长的向量拼接成方阵,得到重组后的查询集视觉特征、支持集视觉特征和支持集摘要特征;
12、将重组的查询集视觉特征、支持集视觉特征和支持集摘要特征输入到空间多尺度交互组件,得到空域多尺度融合特征;
13、将重组的查询集特征和支持集特征拉伸恢复到原有的维度,输入到重建模块,对查询集特征和支持集特征进行重建,利用循环一致性损失对重建特征和原始视觉特征做约束,间接保证摘要生成的质量;
14、将得到的时域多尺度融合特征和空域多尺度融合特征输入到融合模块,进行特征融合,并预测最终的摘要生成。
15、进一步的,关于计算得到单尺度时序特征,计算过程如下:
16、
17、
18、其中,的,分别表示注意力机制中键、查询、值和线性输出层的可学习参数;表示的是查询集视频、支持集视频和支持集摘要的输入,表示的是这三者经过注意力网络提取了时序信息的单尺度特征,即查询特征、支持特征、支持摘要特征。
19、进一步的,关于单尺度时序特征和类别相似性特征输入时序多尺度交互组件,得到时域多尺度融合特征,具体如下:
20、(1)将获得的单尺度时序特征和类别特征利用自适应平均池化操作生成多个尺度的特征;
21、(2)将对应尺度的四个特征拼接在一起;
22、(3)利用插值操作将不同尺度的拼接特征统一到相同的维度;
23、(4)将相同维度的多尺度特征相加,得到时域多尺度融合特征。
24、进一步的,将重组的查询集视觉特征、支持集视觉特征和支持集摘要特征输入到空间多尺度交互组件,得到空域多尺度融合特征,具体如下:
25、(1)将s9中重组的查询集视觉特征、支持集视觉特征和支持集摘要特征利用自适应平均池化操作生成多个尺度的特征;
26、(2)将对应尺度的三个特征拼接在一起;
27、(3)采用卷积对拼接后的特征提取空间信息,得到多个尺度的空间特征;
28、(4)将多个尺度的空间特征拼接在一起;
29、(5)利用插值操作将多尺度空间特征合并,得到空域多尺度融合特征。
30、进一步的,关于循环一致性损失,具体如下:
31、
32、式中,表示查询集视觉特征、表示支持集视觉特征,表示查询集重建特征,表示支持集重建特征。
33、进一步的,所述融合模块包含一个全连接层和两个预测网络,每个预测网络内包含一个全连接层、一个relu激活函数、一个dropout随机失活层和一个归一化层。
34、进一步的,在进行特征融合,并预测最终的摘要生成的过程中,利用焦点损失、时序交并比损失和二元交叉熵损失对预测的y中重要性分数、位置回归和中心度做约束,整体损失如下:
35、
36、
37、
38、其中,和表示第帧预测的重要性分数和人类标注的分数、和表示第个片段预测的时间间隔和真实的时间间隔、和表示第个片段预测的中心度分数和真实的中心度分数。
39、根据本发明的第二方面,本发明提供一种空时多尺度交互的视频摘要生成系统,其特征在于,包括:
40、数据集改造模块,用于接收待处理视频构成数据集,对数据集进行改造,为数据集中每个视频添加类别,并将视频按照类别划分训练集和测试集,要求测试集中的类别不能在训练集中出现;
41、选取模块,用于根据划分的训练集和测试集,分别为其查询集选取支持集视频;
42、摘要生成模块,用于根据groundtruth为选取的支持集视频生成摘要,支持集视频与支持集摘要共同组成支持集;
43、获取模块,用于将获取的查询集、支持集和支持集摘要输入到googlenet网络中获取第五个池化层的特征作为视频帧级特征,并作为空时多尺度交互模型的输入;
44、第一计算模块,用于将获取的视频帧级特征输入时域多尺度模块中的注意力网络,计算得到单尺度时序特征
45、类别特征获取模块,用于将获取的支持集视频帧级特征和支持集摘要特征做矩阵乘法,获得类别相似性特征,输入到时域多尺度模块中;
46、第二计算模块,用于将获得的单尺度时序特征和类别相似性特征输入时序多尺度交互组件,得到时域多尺度融合特征;
47、嵌入融合模块,用于将获得的查询集特征、支持集特征和支持集摘要特征输入到空域多尺度模块中,并将特征向量分别均分为相同大小的片段,并为每个片段添加位置嵌入,利用一个全连接层对视频特征和位置嵌入进行融合;
48、重组模块,用于将融合后的特征进行重组,将等长的向量拼接成方阵,得到重组后的查询集视觉特征、支持集视觉特征和支持集摘要特征;
49、第三计算模块,用于将重组的查询集视觉特征、支持集视觉特征和支持集摘要特征输入到空间多尺度交互组件,得到空域多尺度融合特征;
50、重建模块,用于将重组的查询集特征和支持集特征拉伸恢复到原有的维度,输入到重建模块,对查询集特征和支持集特征进行重建,利用循环一致性损失对重建特征和原始视觉特征做约束,间接保证摘要生成的质量;
51、输入融合模块,用于将得到的时域多尺度融合特征和空域多尺度融合特征输入到融合模块,进行特征融合,并预测最终的摘要生成。
52、本发明至少具备以下有益效果:
53、(1)本发明提出了一个新任务,称为少样本视频摘要,旨在仅使用有限数量的支持样本来为视频生成摘要,少样本视频摘要引入了类别信息到视频摘要任务中,只需要在新类别中的少量样本即可快速泛化到未见过的新类别上,减轻了人类注释者的注释负担。
54、(2)本发明为少样本视频摘要任务提供了第一个标准模型,即stemi,它通过双分支结构来提取空间和时间特征,并进一步在多尺度上交互空间和时间特征,为少样本视频摘要任务提供了丰富的信息。
55、(3)本发明将几种视频摘要的最新技术移植到少样本场景中,对模型重新训练后获得少样本场景中的结果,以便于我们的模型可以进行公平比较,以及此项新任务的后续工作可以有比较的参考模型。
56、当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
本文地址:https://www.jishuxx.com/zhuanli/20240822/281277.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。