一种基于人脸属性解耦的语音驱动人脸口型替换方法
- 国知局
- 2024-08-30 15:07:02
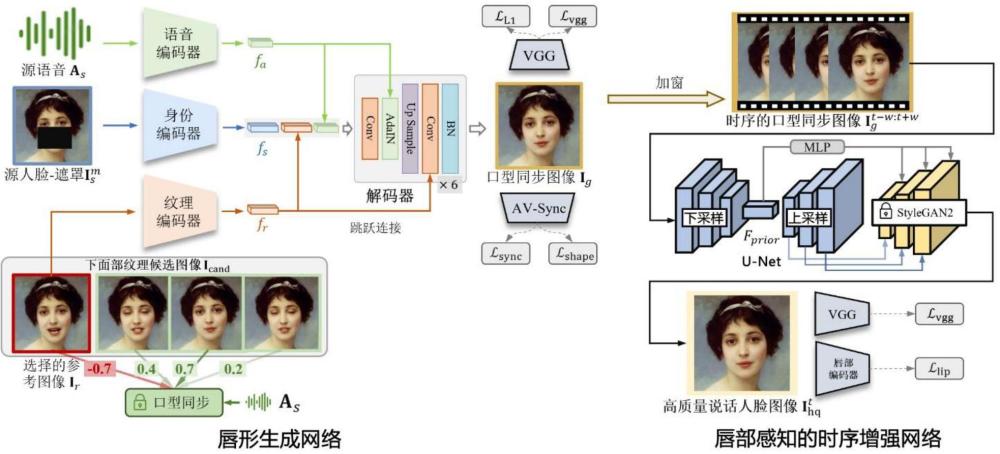
本发明属于计算机视觉和深度学习,尤其是涉及一种基于人脸属性解耦的语音驱动人脸口型替换方法。
背景技术:
1、近年来,随着人工智能和深度学习的发展,基于深度学习的视频内容生成工具也在逐渐增多。除了传统的剪辑、复制、移动和删除等伪造方法外,代表着人脸替换技术的deepfake和faceswap,代表面部表情转换技术的face2face,以及代表语音驱动人脸口型替换技术的speech2vid和davs,已经成为最具代表性的人工智能伪造技术。其中语音驱动的人脸口型替换的目标是将给定的讲话者的面部视频的口型替换成与输入语音同步的口型,该项技术在电影行业、媒体制作和虚拟角色生成领域有广泛应用。
2、speech2vid是一种基于深度学习的语音驱动人脸口型替换技术,工作方式是通过音频内容编码器和面部特征编码器来提取音频特征和人脸图像特征。然后将这两种特征链接起来,作为解码器的输入,以生成与音频同步并保留原始人脸特征的图像。speech2vid主要由音频编码网络、人脸特征编码网络和人脸解码网络三部分组成。音频编码网络和人脸特征编码网络负责对输入的音频或人脸进行编码,以获取降维后的输出特征表示。人脸解码网络则通过利用这些经过合并的特征向量来重构与输入音频同步的人脸图像
3、davs(disentangled audio-visual system)考虑到一个说话者的面部常常是面部外观和口型运动的复杂组合。现有的研究往往过度关注前者,从而导致口型和语音之间的同步性不佳;或者过度侧重于后者,以至于生成的伪装人脸身份有误差。因此,davs同时考虑了这两个方面,并通过学习解耦的视听表示来制作与输入语音同步,并且具有真实外观的篡改视频。在这个模型中,作者做了一个假设,认为来自人脸图像的口型特征和语音特征应该是同步的,而来自人脸图像的人物身份信息和语音特征应该是正交的(不相关的)。为了实现这一目标,该方法设计了别的特征(视觉)编码器、语音特征编码器和口型特征(视觉)编码器来分别获取这些特征。通过对比损失,该方法保证了口型特征和语音特征的同步。与此同时,该方法还使用了预训练的单词分类器和对抗学习方法来在身份特征中强化口型特征,从而实现了说话内容和说话者身份的解耦。
4、前述的语音驱动人脸口型替换技术虽然可以在一定程度上实现口型跟音频的同步,但其生成的说话人脸视频并没有考虑到真实场景下的复杂头部姿势,只能生成固定头部姿势的说话人脸视频,这就大大降低了生成的视频的可信度。因此,国内外的研究者们提出了一种针对复杂头部姿势的语音驱动的人脸口型替换技术,其中与本文研究最为相近的技术方案是一个被称为wav2lip的口型替换技术。wav2lip的输入部分由三个组成部分构成。首先是输入的音频,这部分用于提供最终生成的说话人脸的口型形状。第二部分是与输入音频同步的说话人脸图像(这里的嘴部区域会被掩码遮挡),该部分被用于提供人物的姿势信息以及身份信息。最后一部分是该人物的非同步图像,这部分主要是用于提供嘴部区域被遮盖部分的纹理信息。这三部分信息合在一起,使得wav2lip能够生成出口型、姿势以及身份都与实际情况相符的说话人脸视频。wav2lip的整体结构由三个部分组成,一个是由残差卷积神经网络(residual convolutional neural network)构成的音频特征提取器和人物身份特征提取器,用于接收输入的音频和图像,并将其映射到一个低维的特征空间,然后在这个空间中融合音频特征和图像特征。第二个部分是一个解码器网络,这个网络接收融合的音频图像特征作为输入,然后基于这些特征来生成与音频同步的对应的说话人的脸部表情。第三个部分是一个判别器网络,这个网络接受真实的图像和生成的图像作为输入,然后通过使用对抗训练的思想来优化解码器的生成效果。音频特征提取器由13个卷积块组成,其中包括7个残差卷积块。人脸特征提取器由18个卷积块组成,其中包括10个残差卷积块。卷积块和残差卷积块由卷积层以及后续的归一化、激活操作组成。解码器网络由14个卷积块和6个反卷积块组成,其中反卷积块用于将输入特征上采样,卷积块用于将编码器得到的特征和解码器上采样得到的特征进行融合处理,这也被称为跳跃连接。判别器网络由14个卷积块组成,该网络将深层的图像特征映射到一个从0到1的区间,这个值被用于判断输入图像的真实性。
5、当前针对语音驱动人脸口型替换技术多种多样,其中存在的缺点大致包括如下几点:人脸唇部形状特征和人脸身份特征耦合在一起,理想的说话人脸的嘴型仅由驱动语音来决定,而生成说话人脸往往直接将参考人脸的嘴部形状拷贝到生成说话人脸中,进而导致口型同步度有待提高;由于音频特征和人脸高频特征的相关性较弱,直接在高分辨率的数据集上学习音频特征和人脸高频特征的联系往往效果不好,最终结果的清晰度有待提高。在以前的方案中,人们往往会使用人脸图像的超分辨率算法进行后处理,但是直接在视频上应用图像的超分辨率算法往往会导致视频变形,从而影响最终视频的自然度和保真度。
技术实现思路
1、为克服当前语音驱动人脸口型替换技术存在的不足,本发明提出一种基于人脸属性解耦的语音驱动人脸口型替换方法,旨在提高语音驱动的口型替换的同步性,并提高生成的面部清晰度。
2、本发明具体采用的技术方案是:
3、一种基于人脸属性解耦的语音驱动人脸口型替换方法,包括以下步骤:
4、定位视频中的面部区域并裁剪视频;
5、从视频中随机抽取一帧作为源人脸图像并遮罩嘴部区域,得到含遮罩的源人脸图像;
6、从视频中提取与源人脸图像对应的源语音;
7、从视频中随机抽取若干帧人脸图像作为候选图像;
8、使用预训练的音视频同步判别器选择与源语音同步性最低的图像作为参考图像;
9、对含遮罩的源人脸图像进行编码,生成身份特征;
10、对源语音进行编码,生成语音特征;
11、对参考图像进行编码,生成纹理特征;
12、将语音特征、身份特征和纹理特征输入到解码器处理,生成口型同步图像;
13、将时序的口型同步图像输入到u-net网络进行下采样,提取时序特征;
14、将时序特征通过多层感知器融合不同时间帧的特征,并输入stylegan2模型的解码器,并将时序特征的上采样特征通过跳跃连接注入到stylegan2模型,生成高质量的说话人脸图像。
15、进一步地,源语音通过语音编码器编码生成语音特征,该语音编码器包括13个卷积块,卷积块中有8个是残差块;每个卷积块是由卷积层、归一化层和激活函数构成。
16、进一步地,含遮罩的源人脸图像通过身份编码器编码生成身份特征,该身份编码器包括17个卷积块,其中15个卷积块分属于5个下采样块;每个下采样块是由3个卷积层以及位于每个卷积层之后的归一化层和激活函数构成。
17、进一步地,参考图像通过纹理编码器编码生成纹理特征,该纹理编码器包括17个卷积块,其中15个卷积块分属于5个下采样块;每个下采样块是由3个卷积层以及位于每个卷积层之后的归一化层和激活函数构成。
18、进一步地,解码器包括卷积层、自适应实例归一化层、反卷积层和归一化层,其中,语音特征和纹理特征通过跳跃连接注入到自适应实例归一化层和卷积层,身份特征直接输入卷积层。
19、进一步地,解码器的自适应实例归一化层的处理步骤包括:
20、图像特征进行实例归一化,得到归一化图像特征;
21、将语音特征经过两个多层感知器,分别生成缩放因子和偏移因子;
22、将归一化图像特征逐元素乘以缩放因子,得到乘积结果;
23、将乘积结果逐元素加上偏移因子,得到作为输出的图像特征。
24、进一步地,在生成口型同步图像时,计算l1损失:
25、
26、其中,ig为生成的口型同步图像,ir为参考图像,n为图像中的像素总数。
27、进一步地,在生成口型同步图像时,基于预训练的vgg网络计算感知损失lvgg:
28、
29、其中,mse为均方误差,为预训练的vgg网络提取的图像特征,ig为生成的口型同步图像,ir为参考图像。
30、进一步地,在生成口型同步图像时,采用预训练的音视频同步判别器对输出的唇形与语音的同步性进行约束,步骤包括:
31、利用音视频同步判别器的唇部编码器对源图像、生成的口型同步图像和参考图像进行编码得到特征向量fs、fg和fr;
32、以最小化fg和fs之间的余弦相似度,并最大化fg和fr之间的余弦相似度作为目标,计算唇形感知损失lshape:
33、
34、并计算语音-唇形同步损失lsync可表示为:
35、lsync=φsync(as,ig)
36、其中,as为源语音,ig为生成的口型同步图像。
37、进一步地,在生成高质量的说话人脸图像时,利用预训练的音视频同步判别器的唇形编码器作为教师网络,判断生成图像是否与真实唇形一致,并计算唇部损失llip和vgg损失lvgg;
38、计算唇部损失llip的式子为:
39、
40、其中,mse为均方误差,为唇形编码器,为加有时序窗口的真实图像,为加有时序窗口的生成图像;
41、计算vgg损失lvgg的式子为:
42、
43、其中,mse为均方误差,为预训练的vgg网络提取的图像特征,为加有时间窗口的真实图像,为加有时序窗口的生成图像。
44、本发明与现有技术相比的有益效果在于:
45、(1)相对于随机挑选人脸纹理参考图像的传统方法,本发明采用了基于语音的人脸纹理参考候选图像作为负样本的策略,这一策略不仅提供了更准确的嘴部纹理信息,还在后续网络的学习过程中实现了对比学习,从而使得生成的人脸图像更加逼真和自然。
46、(2)为了获得更具真实性的说话人脸图像,本发明采用了基于自适应实例归一化网络,将源语音特征有机地注入到人脸生成过程中。同时,本发明综合运用感知损失和唇形对比损失,以保证生成结果的视觉效果和唇形同步度,从而提高了生成图像的质量和真实感。
47、(3)为进一步提升生成图像的质量和唇部细节,本发明专门设计了唇形感知的时序面部增强网络,该网络旨在优化唇部细节,同时确保基于学习到的先验知识的时间连贯性,使得生成的人脸图像在视觉上更加逼真、生动,并且具备更好的时间感知,符合人眼的观察习惯,提升了整体的视觉体验。
本文地址:https://www.jishuxx.com/zhuanli/20240830/285557.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表