一种基于智能语义分析的数据识别方法与流程
- 国知局
- 2024-09-05 14:40:13
本发明涉及数据识别,尤其涉及一种基于智能语义分析的数据识别方法。
背景技术:
1、数据识别技术领域涉及从各种数据源中识别、提取和处理信息的方法和系统。这一领域结合了数据挖掘、机器学习和自然语言处理等技术,旨在改善数据的可访问性和可理解性,能够识别其中的意义和关联,从而实现更准确的信息检索和决策支持。数据识别不仅关注于提取特定数据,还包括对数据的分类、标注和概括,支持在海量数据中进行迅速查找。
2、其中,智能语义分析的数据识别方法是一种应用人工智能技术来解析和理解数据中语义内容的技术,通常用于自动化的信息处理任务,如文本分析、情感分析、趋势识别等。主要用途包括但不限于增强搜索引擎的精确度、优化客户服务中的自动响应系统、监测和分析社交媒体趋势,以及在医疗、法律和金融领域中的数据驱动决策,使得机器能够不仅读取文本数据,还能理解其含义,从而提供更为智能和精准的分析工具。
3、现有技术虽整合了多种数据处理技术,但在实际操作中仍存在局限性。特别是在数据关系的动态更新和实时语义分析方面,现有方法依赖于静态模型,缺乏应对快速变化数据环境的灵活性。静态处理逻辑常常导致对新兴数据或突发事件的响应不够及时,未能精确识别出新的或异常的数据模式。此外,现有技术在数据冗余处理和优化方面也显著不足,导致资源浪费和处理效率下降,在大规模数据集处理时尤为明显。限制影响了决策支持和信息检索的质量,限制了技术的应用范围和效果。
技术实现思路
1、本发明的目的是解决现有技术中存在的缺点,而提出的一种基于智能语义分析的数据识别方法。
2、为了实现上述目的,本发明采用了如下技术方案:一种基于智能语义分析的数据识别方法,包括以下步骤:
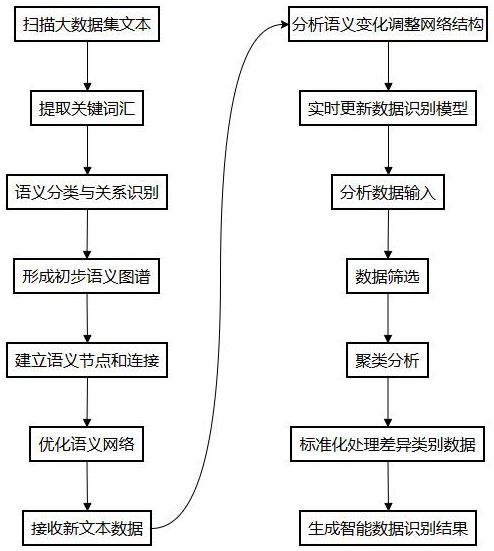
3、s1:对大数据集中的文本内容进行扫描,提取关键词汇,对关键词汇的语义进行分类,根据分类结果识别同义和反义关系,按照语义差异整理归纳,形成初步语义图谱;
4、s2:基于所述初步语义图谱,建立语义节点和连接,每个节点代表一个数据实体,连接显示数据实体间的关系,对重复节点进行识别和削减,生成优化语义网络;
5、s3:利用所述优化语义网络,定期接收新文本数据,分析新文本数据的语义变化,根据分析结果调整网络节点和连接,匹配语义变化,动态更新网络结构,构建实时更新的数据识别模型;
6、s4:基于所述实时更新的数据识别模型,分析数据输入,利用模型中定义的语义规则,进行数据筛选,根据筛选结果进行数据聚类分析,对差异类别数据实体进行标准化处理,生成智能数据识别结果。
7、作为本发明的进一步方案,所述关键词汇的语义分类步骤为:
8、s111:对大数据集进行深度扫描,提取高频词汇集合,采用公式,
9、
10、计算每个词汇的出现频率,生成高频词汇列表,其中,代表单词,是整个文本的总词数;
11、s112:基于所述高频词汇列表,对每个词的文档内外重要性进行量化,采用公式,
12、
13、计算每个词汇的值,并进行筛选,得到关键词表,其中,是文档长度,是总文档数,是包括词汇的文档数;
14、s113:对所述关键词表中的每个词汇进行上下文语义分析,采用公式,
15、
16、计算语义相似度评分,并进行词汇分类,生成分类后的关键词表,其中,和分别是词汇和的向量,和分别表示向量和向量的模。
17、作为本发明的进一步方案,所述初步语义图谱的获取步骤为:
18、s121:使用所述分类后的关键词表,识别词汇间的同义和反义关系,采用公式,
19、
20、计算语义关系得分,生成初步语义关系表,其中,是语义相似度评分,和分别是词汇和的出现位置,和是调整权重,用于控制同义度和位置差异的影响力;
21、s122:对所述初步语义关系表进行深度分析,评估词汇间的语义差异,采用公式,
22、
23、计算词汇间的差异得分,优化语义关系,生成优化后的语义关系表,其中,和是调整参数,用于平衡关系得分和统计差异的影响,median和std分别是相似度的中位数和标准差;
24、s123:利用所述优化后的语义关系表,采用公式,
25、
26、计算词汇间的连接权重,形成初步语义图谱,其中,是所有词汇关系得分的总和。
27、作为本发明的进一步方案,所述优化语义网络的获取步骤为:
28、s211:识别并提取所述初步语义图谱中的每个独立数据实体,采用公式,
29、
30、计算数据实体的重叠度,检查并确认每个实体的唯一性,构建初始语义节点列表,其中,表示第个数据实体,表示其他数据实体,表示数据实体和之间的交集中元素的数量,是数据实体包括的词汇数,是数据实体包括的词汇数;
31、s212:基于所述初始语义节点列表,为每个节点分配连接强度,采用公式,
32、
33、计算每两个节点之间的潜在连接强度,制定初步节点连接图,其中,和是节点集合,是词汇和之间的权重,是词汇和之间语义相似度评分,和分别是节点和的权重系数;
34、s213:根据所述初步节点连接图,设定阈值并排除低于阈值的连接,采用公式,
35、
36、计算节点连接关系,1表示连接,0表示不连接,生成优化语义网络,其中,是设定的连接阈值,是节点和之间的连接强度。
37、作为本发明的进一步方案,所述新文本数据的语义变化分析步骤为:
38、s311:基于所述优化语义网络,进行定期数据抓取,通过api连接至数据源,自动采集指定时间间隔的新文本数据,采用公式,
39、
40、计算时间间隔内收集到的有效数据贡献量,生成定期采集的新文本数据,其中,代表第个数据源的访问频率,表示数据源的可靠性系数,表示数据源质量和稳定性,是数据源的错误率,表示数据源的错误倾向,是时间间隔,是数据源的数量;
41、s312:对所述定期采集的新文本数据进行预处理,采用公式,
42、
43、计算每条数据的平均有效负载,生成预处理后的文本数据,其中,是第条数据的长度,是第条数据有效性评分,是数据条数;
44、s313:对所述预处理后的文本数据进行语义分析,识别关键变化趋势,采用公式,
45、
46、计算文本数据集的语义分析得分,生成新文本语义分析结果,其中,是第个文本条目中提取的语义得分,是文本条目总数。
47、作为本发明的进一步方案,所述实时更新的数据识别模型的获取步骤为:
48、s321:根据所述新文本语义分析结果,识别新增或更新的节点,更新语义网络结构,采用公式,
49、
50、计算节点的更新优先级得分,生成更新后的节点集合,其中,是节点的语义得分,是节点总数;
51、s322:根据所述更新后的节点集合,重新评估调整节点间的连接,采用公式,
52、
53、计算节点间连接强度调整值,得到调整后的节点连接集合,其中,是节点的更新优先级得分,是节点与其他节点的连接强度,是连接数;
54、s323:整合所述更新后的节点集合和调整后的节点连接集合,动态更新网络结构,优化网络响应性,构建实时更新的数据识别模型。
55、作为本发明的进一步方案,所述数据的筛选步骤为:
56、s411:基于所述实时更新的数据识别模型,根据数据流输入的类型和格式,进行模型配置,得到配置完成的数据识别模型;
57、s412:根据所述配置完成的数据识别模型,对数据进行语义分析,筛选关键数据,采用公式,
58、
59、计算筛选后数据语义得分,生成筛选后的语义数据集,其中,是数据点的重要性系数,是数据点的实际评分,是数据点的频率,是调整系数,用于调整数据点的重要性,是特征阈值,是数据点的总数;
60、s413:对所述筛选后的语义数据集进行精炼,剔除噪声和异常值,采用公式,
61、
62、计算精炼后的数据总和,生成精炼后的数据集,其中,是第个数据点的调整权重,反映数据点的重要性,是噪声抑制因子,用于调整因噪声或异常值而偏离正常范围的数据,表示筛选后的数据点数量。
63、作为本发明的进一步方案,所述智能数据识别结果的获取步骤为:
64、s421:使用所述精炼后的数据集,进行聚类分析,识别数据类别和模式,采用公式,
65、
66、计算数据聚合总值,得到聚类分析结果,其中,是第类的权重,是精炼后的数据集中的第个点,是第类中的数据点总数,是总类别;
67、s422:评估所述聚类分析结果,对每个类别进行标准化处理,统一数据格式和表达,采用公式,
68、
69、计算数据标准化得分,生成标准化后的聚类数据,其中,是第类的标准化系数,是第类的原始聚类数据,是第类的规模因子,用于调整类别大小的影响,是聚类分析结果
70、s423:整理所述标准化后的聚类数据,输出智能数据识别结果。
71、与现有技术相比,本发明的优点和积极效果在于:
72、本发明中,通过对大数据集中文本内容的细致扫描和关键词提取,能够精确地归类语义内容并形成初步语义图谱,利用图谱来构建和优化语义网络,明确数据实体间的联系并有效削减重复节点,提高数据处理的效率和系统整体的性能,定期更新和调整网络结构,动态反映新文本数据中的语义变化,增强了数据处理的灵活性和应变能力,通过深入分析数据输入并利用明确定义的语义规则,实现高效的数据筛选和聚类分析,提升数据识别的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240905/287575.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表