基于大语言模型的核电DCS运维信息抽取系统和方法与流程
- 国知局
- 2024-09-11 14:25:25
本发明涉及核电dcs系统,尤其涉及一种基于大语言模型的核电dcs运维信息抽取系统和方法。
背景技术:
1、核电dcs(distributed control system,分布式控制系统)运维数据中蕴含着丰富的专家经验知识及dcs健康管理知识,精准地将专家经验和实践知识转换成计算机可理解的知识并开展应用,可有效帮助运维人员快速报警响应,有助于获得规范化高质量的响应结果,有助于开展dcs状态风险预测,对电厂运维人员进行报警培训、风险预警、报警干预等进行指导。因此,从核电厂dcs运维需求出发,如何对dcs多源异构的运维数据进行知识抽取,进而开展下游应用,已成为电厂亟待解决的问题。然而,传统的数据处理方法难以有效地从这些复杂的文本数据中提取出有用的知识,存在自动化程度低、处理效率低下等问题。因此,开发一种基于大语言模型的核电dcs多源异构运维数据信息抽取方法及系统显得尤为必要。
2、核电dcs运维领域具有大量的、多源、异构数据,但在实际的工程应用中,核电dcs数据和技术文档数据挖掘的效率不高。主要受到三个方面的影响。一、数据来源范围且数据量大。核电dcs日志数据、运维数据、工单数据等数据种类繁多,且分散在不同系统,难以批量获得,且庞大的数据量也增加了数据分析的难度。二、受限于专业领域知识的限制。文档管理人员和信息技术人员对核电技术文档只能从编目、格式、结构等方面进行管理分析,并不能从内容角度提取关键内容进行逻辑重组,以至于数据的二次利用率较低。三、关系型数据库不利于快速响应。传统的关系型数据库在存储日志数据、工单数据等规则过于冗余,且经常存在信息孤岛,难以对不同数据进行关联或难以表示数据可能具有的不同属性以及基于多表进行规则的快速查询。这些问题直接限制了对核电dcs运维数据的全面认知与科学管理,也一定程度制约了dcs报警异常的快速响应。
3、目前,常见的信息抽取方法主要包括:基于规则、统计和深度学习的方法。传统的基于规则的方法,需要先验知识来设定规则,对于复杂的非结构化数据识别效果不佳,而基于统计的方法则需要大量领域知识作为研究支撑,对于研究者的要求较高;基于深度学习的常用方法有长短期记忆(long short time memory,lstm)神经网络和图神经网络等,虽然可以有效地提取上下文文本特征,但需要大量的数据标注工作。
技术实现思路
1、本发明的目的在于提供一种基于大语言模型的核电dcs运维信息抽取系统和方法,解决了多源异构运维数据在缺少专业领域知识和大量标注情况的信息抽取的问题。
2、为了实现上述目的,本发明提供如下技术方案:
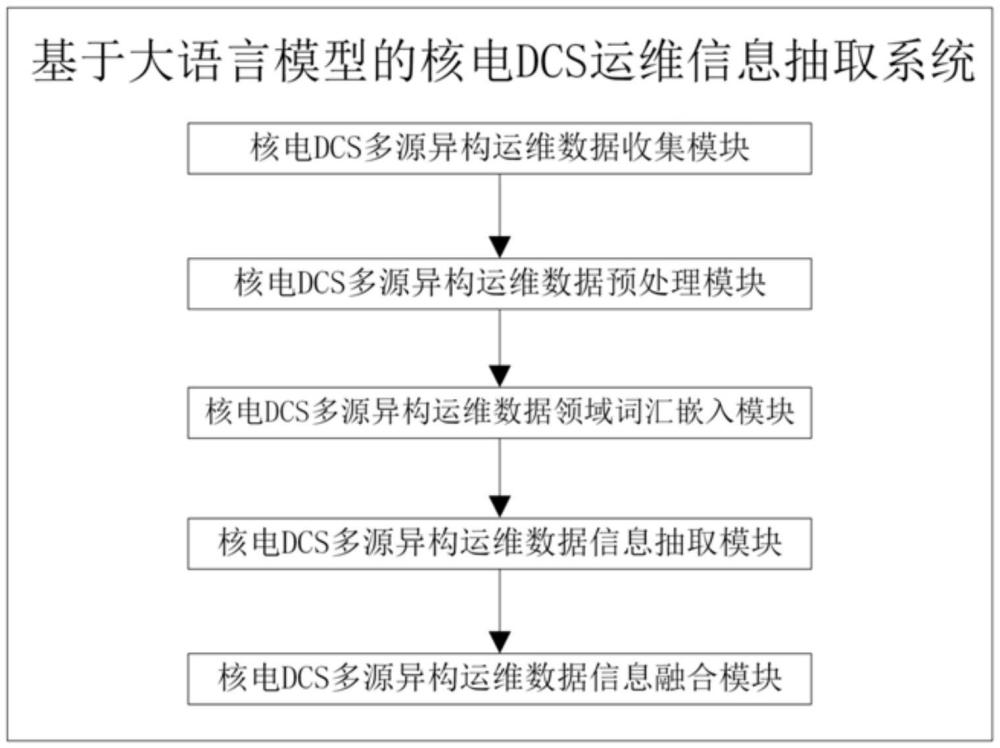
3、一方面,本发明提供了一种基于大语言模型的核电dcs运维信息抽取系统,包括:
4、核电dcs多源异构运维数据收集模块,用于收集核电dcs领域的多源异构运维数据;
5、核电dcs多源异构运维数据预处理模块,用于将收集的核电dcs领域的多源异构运维数据进行数据预处理,形成数据样本集;
6、核电dcs多源异构运维数据领域词汇嵌入模块,用于用于使用嵌入(embedding)模型将dcs领域词汇进行嵌入,提升大语言模型对dcs领域特殊词汇的识别能力;
7、核电dcs多源异构运维数据信息抽取模块,用于本地化部署大语言模型,利用“分步”提示的提示工程模板,引导大语言模型按提示工程进行信息抽取,提升大语言模型信息抽取质量;同时,依托提示工程,利用大语言模型对抽取后的英文文本信息进行翻译;
8、核电dcs多源异构运维数据信息融合模块,用于将大语言模型及其他方法抽取的信息进行知识融合,形成本地知识库。
9、在一些实施例中,多源异构运维数据既包含清单、列表等结构化数据,也包含报告、手册、规程等半结构化和非结构化数据。具体包括报警日志、故障手册、报警规程、风险分析、检修方案、抢修报告等数据文件。
10、在一些实施例中,核电dcs多源异构运维数据预处理模块对收集的数据进行清洗,去除噪声和冗余信息,将不同格式的数据统一转换为标准格式。
11、在一些实施例中,核电dcs多源异构运维数据信息抽取模块通过本地化部署大语言模型,利用满足信息抽取的提示方法,引导大语言模型按用户需求开展信息抽取任务,并结合上述提示工程开展信息抽取并对抽取内容翻译。。
12、另一方面,本发明提供一种基于大语言模型的核电dcs运维信息抽取方法,包括:
13、步骤1:收集与核电运维的多源异构文本数据;
14、步骤2:对步骤1中收集的数据进行数据预处理;
15、步骤3:使用嵌入(embedding)模型将dcs领域词汇进行嵌入;
16、步骤4:用大语言模型进行信息抽取,本地化部署大语言模型,利用“分步”提示的提示工程,针对多源异构数据样本,采用“分步”提示方法+大语言模型抽取数据中的关键信息,并实现抽取文本的自动翻译;
17、步骤5:对抽取的多源异构运维数据进行融合,消除冗余信息和矛盾信息。
18、在一些实施例中,步骤2包括:
19、步骤2.1:对收集的数据进行清洗,去除噪声和冗余信息;
20、步骤2.2:将不同格式的数据统一转换为标准格式;
21、步骤2.3:针对中文文本,进行分词处理,并去除停用词,以降低特征向量的维度大小、提高抽取知识的准确度;
22、步骤2.4:对少量部分数据进行标注,为大语言模型的信息抽取提供少量标注样本。
23、步骤3中,将dcs领域字词映射到低维向量空间,对文本进行向量编码,将自然语言文本转换成计算机能够识别的向量表示,词嵌入公式表达为:
24、e:v→rd
25、
26、式中,e为嵌入函数,v为词汇表,d为嵌入的维度,v为词汇表中的词。
27、步骤4中,利用提示工程,基于提示学习和少样本学习的大语言模型进行实体抽取;同时,依托提示工程,对抽取后的英文文本信息进行英译中的词汇翻译。对于结构化数据,利用抽取关键字段的提示模版,通过大语言模型读取dcs系统导出的字段的数据,经数据预处理后直接作为抽取信息;对于半结构化数据,利用正则表达式匹配、词典匹配、模板匹配等基于规则的提示模版,抽取日志数据中实体信息;对于非结构化数据,使用“分步”提示的提示学习和少样本学习的大语言模型进行实体抽取。
28、步骤4中,对于非结构化数据,以langchain+chatglm3-6b(也可改为其他开源大语言模型,如llama/baichuan/qwen等)为基础模型,在prompt提示方面,以条件和任务进行驱动,采用“分步提示法”(需求提示、领域知识提示、样例提示)提示进行抽取。
29、步骤5中,将提取的同类别实体进行向量化编码,进行文本相似度计算,余弦相似度计算公式为:
30、
31、式中,a·b是向量a和向量b的点积,||a||和||b||是向量的欧几里得范数;
32、欧式距离计算公式为:
33、
34、与现有技术相比,本发明提供的基于大语言模型的核电dcs运维信息抽取系统和方法具有以下有益效果:
35、本发明基于大语言模型(large language model,llm)对自然语言的理解能力和上下文推理能力,提供了一种基于大语言模型的核电dcs运维信息抽取方法及系统,能够免去一般信息抽取繁重的数据标注工作,更好地处理多源异构复杂的文本数据。
36、本发明具有高效的数据处理和强大的理解能力,利用大语言模型处理多源异构运维数据,提高数据整合和知识抽取的效率。大语言模型经过大量文本数据的训练,具备较强的语义理解能力,能够更好地理解文本内容和上下文关系。
37、本发明具有自动化程度高和准确的语义理解,大语言模型可以自动执行实体识别任务,减少了对人工标注的依赖,提高了自动化程度。大语言模型具备强大的语义理解能力,能够准确提取和处理文本中的关键信息。
38、本发明能提高构建效率和易于集成、扩展,大语言模型可以快速处理大量文本数据,提高信息抽取的效率;大语言模型易于与其他系统和工具集成,也便于根据需要进行扩展和优化。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290707.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表