用于混合领域的成分句法分析的方法、装置和介质
- 国知局
- 2024-09-14 14:23:06
本申请涉及自然语言处理,更具体地,涉及一种用于混合领域的成分句法分析的方法、装置和介质。
背景技术:
1、成分句法分析是自然语言处理的一个基础任务,其目标是解析出句子中的短语结构句法树,它可以为机器翻译、自然语言推理、文本摘要等下游的自然语言任务提供帮助。近些年来,随着深度学习与预训练语言模型的发展,一些基于图的成分句法分析器已经在例如ptb(penntreebank dataset)文本数据集和ctb(chinesetreebank dataset)数据集等新闻领域标准数据集上取得了令人满意的成绩,然而由于用于模型训练的领域数据不均衡等原因,使得这些模型在某些训练数据较少的领域,例如生物领域的成分句法分析性能却不尽人意。现有技术往往需要增加语言模型的复杂度,或者还可以对该领域更多的语料数据进行标注,然后将标注数据用于语言模型的训练,以期提高语言模型在该领域的性能表现。也就是说,在不增加语言模型复杂度,也不利用更多的标注数据的情况下,现有技术尚无法提高特定成分句法分析器在混合领域的性能的均衡性。
技术实现思路
1、提供了本申请以解决现有技术中存在的上述问题。
2、需要一种用于混合领域的成分句法分析的方法、装置和介质,其能够在不改变原有的语言模型,也无需利用额外的标注数据的情况下,提高成分句法分析器在特定领域的表现,从而使得成分句法分析器在混合领域进行成分句法分析时具有更均衡的性能。
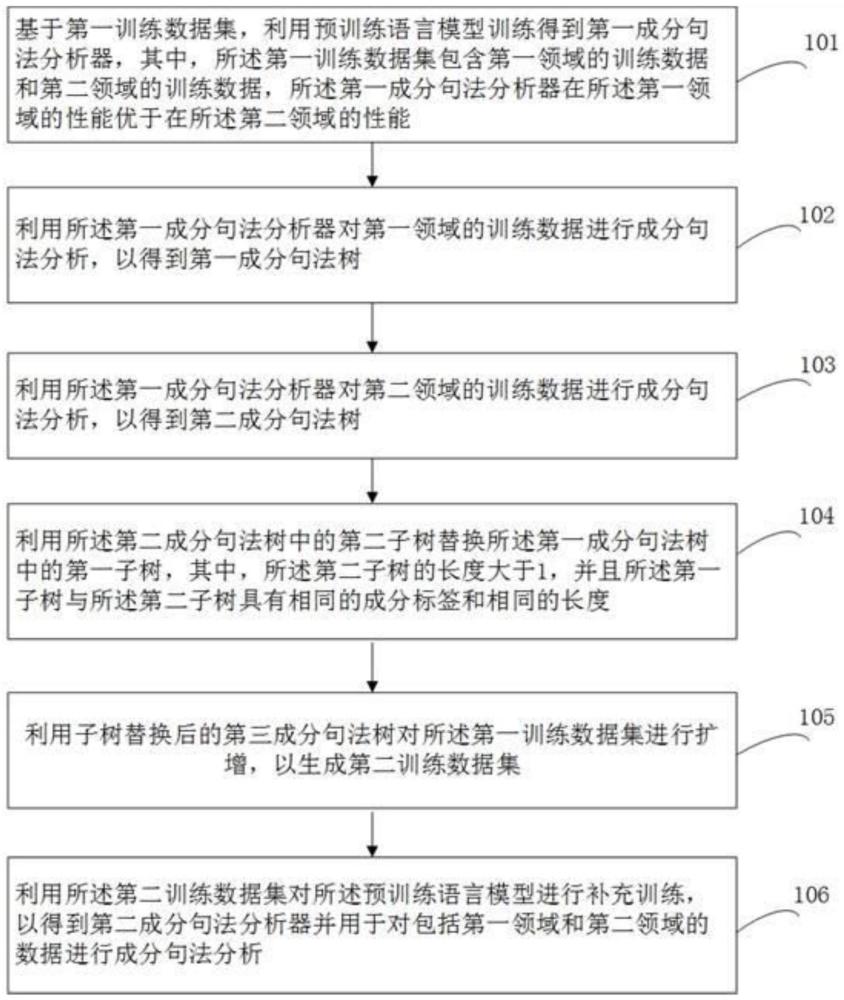
3、根据本申请的第一方案,提供一种用于混合领域的成分句法分析的方法,包括:基于第一训练数据集,利用预训练语言模型训练得到第一成分句法分析器,其中,所述第一训练数据集包含第一领域的训练数据和第二领域的训练数据,所述第一成分句法分析器在所述第一领域的性能优于在所述第二领域的性能;利用所述第一成分句法分析器对第一领域的训练数据进行成分句法分析,以得到第一成分句法树;利用所述第一成分句法分析器对第二领域的训练数据进行成分句法分析,以得到第二成分句法树;利用所述第二成分句法树中的第二子树替换所述第一成分句法树中的第一子树,其中,所述第二子树的长度大于1,并且所述第一子树与所述第二子树具有相同的成分标签和相同的长度;利用子树替换后的第三成分句法树对所述第一训练数据集进行扩增,以生成第二训练数据集;利用所述第二训练数据集对所述预训练语言模型进行补充训练,以得到第二成分句法分析器并用于对包括第一领域和第二领域的数据进行成分句法分析。
4、根据本申请的第二方案,提供一种用于混合领域的成分句法分析的装置,所述装置包括:接口和处理器,所述接口配置为获取第一训练数据集和预训练语言模型,其中,所述第一训练数据集包含第一领域的训练数据和第二领域的训练数据。所述处理器配置为执行如本申请各个实施例所述的用于混合领域的成分句法分析的方法的步骤。
5、根据本申请的第三方案,提供一种非暂时性计算机可读介质,其上存储有指令,其中当由处理器执行时,所述指令执行如本申请各个实施例所述的用于混合领域的成分句法分析的方法的步骤。
6、根据本申请各个实施例的用于混合领域的成分句法分析的方法、装置和介质,当基于第一领域和第二领域的混合训练数据对预训练语言模型训练得到的成分句法分析器在第二领域的性能表现不佳时,通过利用第二领域的子树替换第一领域的具有相同的成分标签和相同的长度的子树,并将子树替换后的数据作为扩增数据,利用扩增后的训练数据集对预训练语言模型成分句法分析器进行补充训练,由此,可以在无需补充第二领域的标注数据,也不改变原有预训练语言模型的前提下,仅通过子树替换,即可提高成分句法分析器在第二领域内的性能表现,从而使得混合领域的成分句法分析器具有更好的鲁棒性,在各个领域的性能表现也更均衡。
7、上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
技术特征:1.一种用于混合领域的成分句法分析的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述第一领域的训练数据多于所述第二领域的训练数据。
3.根据权利要求1或2所述的方法,其特征在于,所述方法进一步包括:
4.根据权利要求1或2所述的方法,其特征在于,利用所述第二成分句法树中的第二子树替换所述第一成分句法树中的第一子树,其中,所述第二子树的长度大于1,并且所述第一子树与所述第二子树具有相同的成分标签和相同的长度具体包括:
5.根据权利要求4所述的方法,其特征在于,从所述第二成分句法树中选择长度大于1的第二子树进一步包括:与第二成分句法树中长度大于1的第二子树的长度和/或成分标签的分布相关联地选择第二子树,使得对应长度和/或成分标签的第二子树分布越集中,所选择的具有该长度和/或成分标签的第二子树的数量越多。
6.根据权利要求1或2所述的方法,其特征在于,利用所述第二成分句法树中的第二子树替换所述第一成分句法树中的第一子树,其中,所述第二子树的长度大于1,并且所述第一子树与所述第二子树具有相同的成分标签和相同的长度进一步包括:
7.根据权利要求1或2所述的方法,其特征在于,所述第一子树和所述第二子树均为多棵,利用所述第二成分句法树中的第二子树替换所述第一成分句法树中的第一子树,其中,所述第二子树的长度大于1,并且所述第一子树与所述第二子树具有相同的成分标签和相同的长度进一步包括:利用所述第二成分句法树中对应的第二子树替换所述第一成分句法树中对应的第一子树,其中,各个第二子树的长度大于1,并且对应的第一子树与对应的第二子树具有相同的成分标签和相同的长度。
8.根据权利要求1或2所述的方法,其特征在于,利用子树替换后的第三成分句法树对所述第一训练数据集进行扩增,以生成第二训练数据集进一步包括:
9.根据权利要求8所述的方法,其特征在于,所述判别器以第一训练数据集训练中的第二领域的文本为正样本,以所述第三成分句法树的文本为负样本,利用结构调整后的预训练语言模型训练而得到。
10.一种用于混合领域的成分句法分析的装置,其特征在于,所述装置包括:
11.一种非暂时性计算机可读介质,其上存储有指令,其中当由处理器执行时,所述指令执行如权利要求1-9中任一项所述的用于混合领域的成分句法分析的方法的步骤。
技术总结本申请涉及一种用于混合领域的成分句法分析的方法、装置和介质。所示方法包括利用包含第一领域和第二领域的训练数据的第一训练数据集对预训练语言模型进行训练得到第一成分句法分析器,其在第一领域的性能优于在第二领域的性能;利用第一成分句法分析器分别得到第二领域中成分句法树中的第二子树和第一领域中的第一子树,并用具有相同结构和长度的第二子树替换第一子树,将子树替换后的训练数据集用于第一成分句法分析器的补充训练,并将训练好的第二成分句法分析器用于对包括第一领域和第二领域的数据进行成分句法分析。本申请的方法能够在不额外新增标注数据的情况下,提高成句法分析器在跨领域成分句法分析时的性能和鲁棒性。技术研发人员:崔乐阳,杨森,张岳受保护的技术使用者:西湖大学技术研发日:技术公布日:2024/9/12本文地址:https://www.jishuxx.com/zhuanli/20240914/293744.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表