一种大数据混合存储系统、方法和可读存储介质与流程
- 国知局
- 2024-10-09 16:02:54
本申请涉及大数据存储,特别是涉及一种大数据混合存储系统、方法和可读存储介质。
背景技术:
1、当前大数据存储技术方案中,数据只存在于一种存储服务中,无法充分利用各存储服务的长处形成互补,如hdfs文件系统基于本地块存储其性能更好,但存储成本更高,juicefs文件系统是基于对象存储,存储成本低廉但无法大量并发运行作业,io性能差,适合批量读写。在实际大数据场景中,活跃数据占比很小,如果数据只存储于hdfs文件系统,存储成本较高,如果数据只存储于对象存储中,其性能无法得到保障。
2、针对相关技术中,大数据存储技术只能将数据存储在一个文件系统,无法充分利用各存储服务的长处形成互补的问题,目前尚未提出有效的解决方案。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种大数据混合存储系统、方法和可读存储介质。
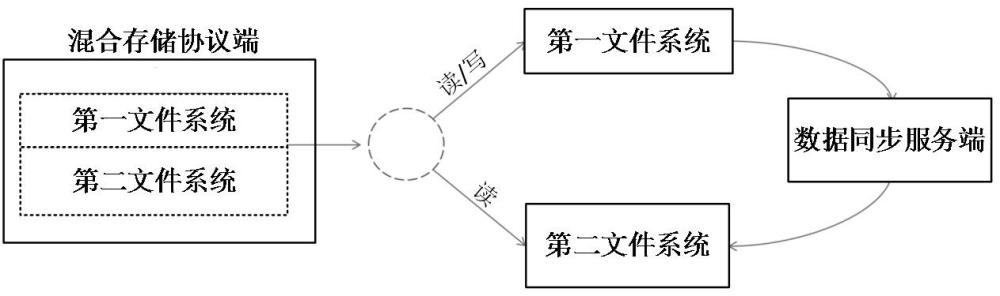
2、第一方面,本申请实施例提供了一种大数据混合存储系统,所述系统包括:
3、基于本地块存储的第一文件系统,用于存储活跃数据;
4、基于对象存储的第二文件系统,用于存储不活跃数据;
5、混合存储协议端,用于对所述第一文件系统以及所述第二文件系统进行数据自动路由读写;
6、数据同步服务端,用于解析所述第一文件系统的审计日志,获得文件使用统计信息;并启动定时任务扫描所述第一文件系统及所述第二文件系统,获得对应的第一文件列表及第二文件列表;基于所述文件使用统计信息以及所述第一文件列表与所述第二文件列表的差异,确定是否将所述第一文件系统中的数据镜像同步至所述第二文件系统中。
7、在其中一个实施例中,所述混合存储协议端包括:
8、数据写入模块,用于将新增数据写入到所述第一文件系统中;
9、数据读取模块,用于基于用户发起的数据读取请求,返回相应的文件列表以及文件内容。
10、在其中一个实施例中,所述数据读取模块包括:
11、文件信息读取模块,用于经过协议转换后,获取所述第一文件系统的第一文件列表以及所述第二文件系统的第二文件列表,对所述第一文件列表和所述第二文件列表中文件类型为目录的求并集后返回,并返回所述第一文件列表中文件类型为文件的文件列表;
12、文件内容读取模块,用于经过协议转换后,读取所述第一文件系统中的相应文件;若所述第一文件系统中不存在,则读取所述第二文件系统中的相应文件。
13、在其中一个实施例中,所述混合存储协议端还包括:
14、数据删除模块,用于基于用户发起的数据删除请求,经过协议转换后同时删除所述第一文件系统和所述第二文件系统中的文件。
15、在其中一个实施例中,所述数据同步服务端包括:
16、解析模块,用于解析所述第一文件系统的审计日志,获得所述第一文件系统中的文件使用统计信息;
17、扫描对比模块,用于启动定时任务,扫描所述第一文件系统和所述第二文件系统,获取对应的文件列表,对比所述第一文件系统与所述第二文件系统的文件列表差异;
18、同步模块,用于基于所述第一文件系统中的文件使用统计信息,以及所述第一文件系统与所述第二文件系统的文件列表差异,确定是否将所述第一文件系统中的数据同步至所述第二文件系统中。
19、在其中一个实施例中,所述同步模块还用于:
20、若所述第一文件系统中的文件使用频率高于预设值,则将所述第一文件系统中的文件同步至所述第二文件系统中,并删除所述第一文件系统中对应的文件。
21、在其中一个实施例中,所述同步模块还用于:
22、若所述第一文件系统中的文件没有存储在所述第二文件系统中,则将所述第一文件系统中的文件同步至所述第二文件系统中。
23、在其中一个实施例中,所述第二文件系统为juicefs文件系统或jindodata文件系统。
24、第二方面,本申请实施例还提供了一种大数据混合存储方法,应用于如上述第一方面所述的系统,所述方法包括:
25、基于数据同步服务,解析所述第一文件系统的审计日志,获得文件使用统计信息;并启动定时任务扫描所述第一文件系统及所述第二文件系统,获得对应的第一文件列表及第二文件列表;
26、基于所述文件使用统计信息以及所述第一文件列表与所述第二文件列表的差异,确定是否利用所述数据同步服务将所述第一文件系统中的数据镜像同步至所述第二文件系统中。
27、第三方面,本申请实施例还提供了一种计算机可读存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被处理器执行时实现如上述第二方面所述的方法。
28、上述大数据混合存储系统、方法和可读存储介质,其中,大数据混合存储系统包括第一文件系统、基于对象存储的第二文件系统、混合存储协议端、数据同步服务端,第一文件系统用于存储活跃数据;基于对象存储的第二文件系统用于存储不活跃数据;混合存储协议端用于对所述第一文件系统以及所述第二文件系统进行数据自动路由读写;数据同步服务端用于解析所述第一文件系统的审计日志,获得文件使用统计信息;并启动定时任务扫描所述第一文件系统及所述第二文件系统,获得对应的第一文件列表及第二文件列表;基于所述文件使用统计信息以及所述第一文件列表与所述第二文件列表的差异,确定是否将所述第一文件系统中的数据镜像同步至所述第二文件系统中,解决了大数据存储技术只能将数据存储在一个文件系统,无法充分利用各存储服务的长处形成互补的问题,实现了在大数据实际应用场景下批作业稳定运行并实现数据存储成本降压,并减小了对象存储访问压力。
29、本申请的一个或多个实施例的细节在以下附图和描述中提出,以使本申请的其他特征、目的和优点更加简明易懂。
技术特征:1.一种大数据混合存储系统,其特征在于,所述系统包括:
2.根据权利要求1所述的系统,其特征在于,所述混合存储协议端包括:
3.根据权利要求2所述的系统,其特征在于,所述数据读取模块包括:
4.根据权利要求1所述的系统,其特征在于,所述混合存储协议端还包括:
5.根据权利要求1所述的系统,其特征在于,所述数据同步服务端包括:
6.根据权利要求5所述的系统,其特征在于,所述同步模块还用于:
7.根据权利要求5所述的系统,其特征在于,所述同步模块还用于:
8.根据权利要求1所述的系统,其特征在于,所述第二文件系统为juicefs文件系统或jindodata文件系统。
9.一种大数据混合存储方法,应用于权利要求1至权利要求8中任一项所述的系统,其特征在于,所述方法包括:
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求9所述的方法。
技术总结本申请涉及一种大数据混合存储系统、方法和可读存储介质,其中,大数据混合存储系统包括:第一文件系统,用于存储活跃数据;基于对象存储的第二文件系统,用于存储不活跃数据;混合存储协议端,用于对所述第一文件系统以及所述第二文件系统进行数据自动路由读写;数据同步服务端,用于解析所述第一文件系统的审计日志,获得文件使用统计信息;并启动定时任务扫描所述第一文件系统及所述第二文件系统,获得对应的第一文件列表及第二文件列表;基于所述文件使用统计信息以及所述第一文件列表与所述第二文件列表的差异,确定是否将所述第一文件系统中的数据镜像同步至所述第二文件系统中,实现了数据存储成本降压,并减小了对象存储访问压力。技术研发人员:莫旭强受保护的技术使用者:天翼视联科技有限公司技术研发日:技术公布日:2024/9/26本文地址:https://www.jishuxx.com/zhuanli/20240929/311410.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。