一种基于WiFi的目标位置和行为联合识别方法
- 国知局
- 2024-10-09 16:20:23
本发明涉及无线感知,尤其是一种基于wifi的目标位置和行为联合识别方法。
背景技术:
1、目前,很多应用系统要求对人体目标的位置和行为等多维信息进行同时识别。例如:老人远程护理监测系统,精确追踪被监测者的位置与行为至关重要,一旦监测到发生跌倒等潜在风险行为,便会立即触发警报机制,以便迅速启动远程医疗援助服务;在智能家居系统中,为了控制电器设备,就必须准确辨识人体位置和手势(行为)信息。为了实现对人体目标多维信息的准确识别,国内外学者深入研究了计算机视觉、可穿戴传感器以及无线感知等关键技术。基于计算机视觉的多维信息识别技术在应对光线变化、烟雾干扰以及遮挡物等复杂外部环境时,其精度往往受到显著影响,并且耗时较长;可穿戴传感器,需要用户佩戴特定的传感器或在应用场景中部署特定的传感器设备,存在着增加成本及使用不便等问题;基于无线感知的识别技术具备多种显著优势,该技术不受视距限制和光照条件的影响、无需用户携带任何特定设备及在应用场景下额外部署专用传感器,尤其是该项技术能够有效保护用户的隐私,因此逐渐在智能感知领域占据了核心位置。
2、无线感知技术主要包含基于接收信号强度(rss,received signal strength)和信道状态信息(csi,channel state information)两类方法。基于rss的感知技术受限于室内多径效应,稳定性较差,其应用范围主要局限于感知一些粗粒度的任务。相较之下,基于csi的感知技术除了可以获取多个子载波的幅值信息外,还能获得相应的相位信息,在同一传播环境中,接收设备的csi数据具有更高的稳定性,因此更适用于执行细粒度的感知任务,满足更高精度和鲁棒性的应用需求。
3、现有的基于csi的目标位置和行为联合识别算法主要分为两类:基于机器学习和基于深度学习的算法,在进行训练时均需要大量的标注训练样本,才能获得理想的识别精度。为了降低数据采集和标记所产生的高成本,一些学者已经将小样本学习方法应用于人体目标行为或者位置识别算法中,但是,迄今为止,未见关于将小样本学习方法应用于人体目标位置和行为的联合识别算法中的相关报道。
技术实现思路
1、本发明是为了解决现有技术所存在的需要大量训练样本才能达到较高识别精度的问题,提供一种基于wifi的目标位置和行为联合识别方法。
2、本发明的技术解决方案是:一种基于wifi的目标位置和行为联合识别方法,其特征在于按照如下方法进行:
3、步骤1:在t时刻采集csi数据并表示如下:
4、
5、式中:n=1,2,…,n,n表示通信链路的序数,n表示通信链路的总数,m=1,2,…,m,m表示每条通信链路的子载波的序数,m表示每条通信链路的子载波的总数,i=1,2,…,i,i表示每个样本的数据包的序数,i表示每个样本的数据包的总数,|hm,i(n)|和φm,i(n)分别表示第n条通信链路的第m个子载波的第i个csi数据的幅值和相位;
6、采用hampel滤波算法挑选并剔除异常值:设定一个长度为2k+1的窗口,用于在csi幅值数据上滑动并处理数据,其中k为滑动窗口长度系数,计算该窗口的中值meds和中值绝对偏差mads如下:
7、
8、式中:median()为取中值的函数,s为csi幅值的序号,s=k+1,k+2,…,i-k-1,i-k;如果||hm,s(n)|-meds|>qmads,则|hm,s(n)|被认定为异常值,并使用meds进行替换,其中q为权重;
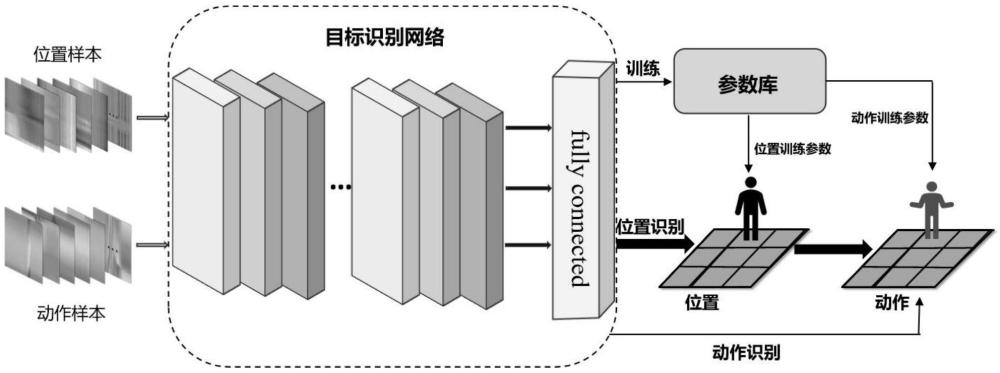
9、进一步采用高斯滤波算法,消除csi幅值中的高频噪声;
10、步骤2:从第n条通信链路的第m个子载波的一个样本幅值向量|hm(n)|中找出所有大于相邻元素数值的元素,构成向量|hm(n)|的峰值集合如下:
11、
12、令high(r)是peak(|hm(n)|)中的第r个元素,在|hm(n)|中找到high(r),然后找到high(r)两端最临近的谷值,分别表示为lowleft(r)和lowright(r);
13、按照如下公式查找符合要求的峰值和谷值:
14、max(min(high(r)-lowleft(r),high(r)-lowright(r))),
15、在|hm(n)|中,满足上述公式的两个谷值之间的数据即为csi样本的行为识别部分,其它数据为位置识别部分;
16、步骤3:分别计算不同通信链路的csi行为识别部分和位置识别部分的差,并将获得的矩阵转换成图像形式,构成csi样本的位置识别图像和行为识别图像;
17、步骤4:构建目标识别网络并进行训练,训练完成后分别将获得的位置和行为网络参数存储到参数库中;
18、所述构建目标识别网络进行训练时,是将j个训练样本按照步骤1-3得到位置识别图像和行为识别图像,分别将位置识别图像和行为识别图像的垂直中心线和水平中心线的交点定为原点,建立直角坐标系,将图像的所有像素点a(x1,y1)水平翻转为a'(-x1,y1),生成一个新的图像,得到j×2个位置识别图像和行为识别图像;设置每个图像对应的位置类别标签a,a=1,2,…,a,以及行为类别标签b,b=1,2,…,b,a为位置类别的总数,b为行为类别的总数,分别将位置识别图像和标签,以及每个位置对应的动作识别图像和标签输入到目标识别网络进行训练;
19、步骤5.将待测的csi样本的位置识别图像和行为识别图像先后输入给训练完成的目标识别网络,分别识别目标的位置和行为;
20、具体是计算多个位置识别图像对应像素的平均值,获得1个平均位置识别图像,将平均位置识别图像输入给目标识别网络,采用参数库中的位置网络参数识别目标的位置,然后再计算多个行为识别图像对应像素的平均值,获得1个平均行为识别图像,将平均行为识别图像输入给目标识别网络,采用上述已识别的位置对应的行为网络参数识别目标的行为。
21、优选的技术方案是所述构建的目标识别网络为多注意力层结构残差网络,由特征提取模块和预测分类模块构成;
22、所述特征提取模块是依次设有卷积层conv1、最大池化层maxpool、利用通道注意力层ca1和空间注意力层sa1的组合结构、卷积块层conv block1和空间注意力层sa2的组合结构、卷积块层conv block2和空间注意力层sa3的组合结构、卷积块层conv block3和空间注意力层sa4的组合结构、卷积块层conv block4、通道注意力层ca2和空间注意力层sa5的组合结构及平均池化层avgpool;所述卷积块层conv block1-4是由2个无卷积残差块和1个有卷积残差块串联构成;
23、具体操作是将输入图像p通过卷积层conv1进行一次卷积运算,再通过最大池化层maxpool进行运算,然后利用通道注意力层ca1为不同通道分配不同的权重,函数如下:
24、map1(p)=σ(mlp(avgpool(p))+mlp(maxpool(p))),
25、式中:avgpool()和maxpool()分别为平均池化和最大池化函数,mlp()为多层感知器函数,σ()表示sigmoid函数,再将map1()与图像p进行元素相乘获得重构特征图f;
26、利用空间注意力层sa1为不同像素分配不同的权重,函数如下:
27、f′=σ(f7×7([avgpool(f);maxpool(f)])),
28、式中:f7×7()表示进行卷积核大小为7×7的卷积运算;
29、经过空间注意力分配权重的特征图像f′顺序经过卷积块层conv block1和空间注意力层sa2的组合结构、卷积块层conv block2和空间注意力层sa3的组合结构、卷积块层conv block3和空间注意力层sa4的组合结构的运算,然后再经过卷积块层conv block4、通道注意力层ca2和空间注意力层sa5的组合结构的处理,接下来经过平均池化层avgpool的运算,最终获得输入图像的特征矩阵;
30、所述预测分类模块是两个全连接层fc1和fc2。
31、本发明通过多链路数据作差计算和水平翻转的方式对少量训练样本进行扩展,利用提出的寻峰算法将csi数据分解为位置识别部分和行为识别部分,并转换为图像形式,再分别将两类图像样本和对应的标签输入给构建的目标识别网络进行训练,从而对待测csi数据进行位置和行为联合识别。实验结果表明本发明实现了小样本情况下较高的位置和行为联合识别准确率和鲁棒性,为相关应用提供了一种切实可行的人机交互方案。
本文地址:https://www.jishuxx.com/zhuanli/20240929/312729.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表