一种儿童医疗文本数据分类方法
- 国知局
- 2024-10-15 09:37:06
本发明属于医疗数据处理分类领域,尤其是涉及一种儿童医疗文本数据分类方法。
背景技术:
1、儿童医疗数据分类分级是根据医疗数据的特征、敏感性、价值等因素,将医疗数据划分为不同类别和等级,以便对医疗数据进行有效的管理。在医疗场景中医疗文本数据具有数据量庞大,数据异构繁杂,具有多层级类别的特点,将医疗数据划分为不同的类别,对于提高医疗数据的安全性,促进医疗数据的有效利用,实现医疗数据资产化都有重要意义。
2、多标签文本分类旨在从预定义的候选标签集合中选择一个或多个文本对应的类别,是自已语言处理的一项基础任务,层级的标签是以预定的层级结构存储,目前的多标签分类方法中仍存在结合多个模型对一个数据集进行训练和预测,在训练模型以及推理过程中标签排序时静态采样负样本,这种方法会消耗大量的计算资源,同时由于静态采样负样本使得模型在标签排序时只关注少量的负样本标签,使得模型难以收敛。
3、公开号为cn111403028a的中国专利文献公开了一种医疗文本方法及装置、储存介质,电子设备,根据医学特征属性针对待分类医疗文本的注意力值对待分类文本进行分类。
4、公开号为cn109471945a的中国专利文献公开一种基于深度学习的医疗文本分类方法、装置及存储介质,使用递归神经网络和双向注意力机制对医疗文本进行分类。
5、然而,在医疗场景中,分类体系庞大繁杂,公开号为cn111403028a的中国专利文献在计算医疗属性对分类医疗文本注意力值时会耗费大量资源和时间,无法快速准确得出分类结果,公开号为cn109471945a的中国专利文献同样无法高效处理数据庞杂的医疗文本数据。
技术实现思路
1、本发明提供了一种儿童医疗文本数据分类方法,可有效处理儿童医疗数据层级多标签文本分类问题,计算量小、运算速度快,大大提高了儿童医疗文本到标签的匹配效率。
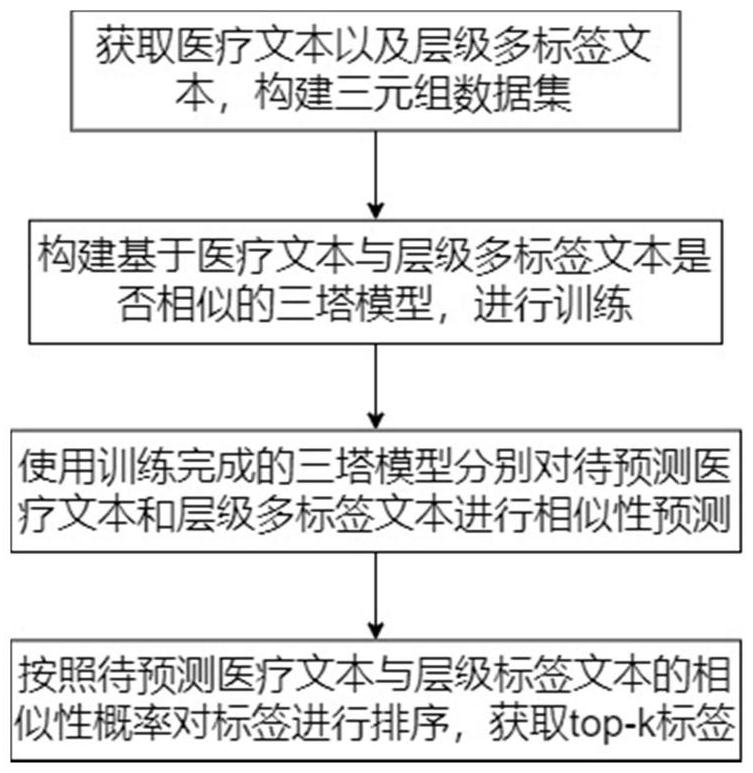
2、一种儿童医疗文本数据分类方法,包括以下步骤:
3、(1)获取儿童医疗文本数据,标注得到层级多标签文本;
4、(2)将儿童医疗文本数据和层级多标签文本处理为医疗文本、正样本标签文本、负样本标签文本,得到三元组数据集;其中,每个正样本标签文本和每个负样本标签文本均包含父类标签文本以及对应的子类标签文本;
5、(3)构建三塔模型,所述的三塔模型包括三个编码器模块、一个标签召回模块和一个标签排序模块;
6、三个编码器模块共享权重,其中,第一编码器和第二编码器分别用于生成医疗文本和父类标签文本的特征向量;标签召回模块将医疗文本和父类标签文本的特征向量进行相似性度量,动态获取相似度最高的几个父类标签对应的子类正负标签文本,输入第三编码器后生成子类标签文本的特征向量;将第一编码器生成的医疗文本特征向量和第三编码器生成的子类标签文本特征向量一起输入标签排序模块,根据相似度值生成top-k标签文本作为预测输出;
7、(4)基于三元组数据集训练三塔模型;
8、(5)使用训练完的三塔模型,分别对层级多标签文本中的父类标签文本和子类标签文本进行处理,将处理得到的所有标签文本对应的特征向量保存至离线特征向量库中;
9、(6)针对待预测的儿童医疗文本,使用训练完的三塔模型进行处理,再结合离线特征向量库,预测获取相似度高于相似度阈值的top-k预测标签。
10、步骤(3)中,所述的编码器模块包括基于transformer的bert编码层、矩阵分解部分和池化层;
11、矩阵分解部分用于将bert编码层编码过程中的注意力矩阵分解为多个更小的矩阵;池化层的作用是将bert编码层的输出进行处理,得到一个固定大小的句子嵌入,即特征向量。
12、bert编码层的每一层均包含一个encoder单元,每个encoder单元由多头注意力机制模块、前馈层、跨层标准化层叠加构成;
13、多头注意力机制模块由多个自注意力机制模块组成,具体公式为:
14、
15、其中,q=wqx、k=wkx、v=wvx分别对应query、key、value,在自注意力机制中为输入x的自身的变换,dk是词向量的维度;
16、矩阵分解部分分别对query矩阵的行和key矩阵的列按照分布分数进行采样,从而分解为对应的子矩阵,具体公式如下:
17、ac=exp(q(kt)c)
18、ar=exp((q)rkt)
19、u=w+
20、其中,ac表示对key矩阵的列进行采样后的子矩阵,c表示对列进行采样,采样数量为k,矩阵ac维度为(k,n);ar表示对query矩阵的列进行采样后的子矩阵,r表示对行进行采样,采样数量为k,矩阵ar的维度为(k,n);中间矩阵为u=w+,其中w是由矩阵ac和矩阵ar相乘获得,w+是其伪逆矩阵;将分解query和key的获得的子矩阵ac、ar和中间矩阵u重构,以获取输出o=acuar。
21、步骤(3)中,标签召回模块包括第一相似度度量模块和动态样本采样模块;
22、其中,第一相似度度量模块分别接受来自第一编码器和第二编码器输出的医疗文本和父类标签文本的特征向量,并进行相似性度量;
23、根据得出的父类标签的相似度排行,动态获取相似度最高的几个父类标签对应的子类正负标签文本,将获取的子类正负标签文本作为第三编码器的输入。
24、步骤(3)中,标签排序模块包括第二相似性度量模块和分类器模块;
25、其中,第二相似性度量模块的结构与标签召回模块中的第一相似性度量模块的结构一致;第二相似性度量模块分别接受来自第一编码器和第三编码器输出的医疗文本和子类标签文本的特征向量,并进行相似性度量;选择相似度值高于相似度阈值的top-k标签文本作为预测输出。
26、步骤(4)中,训练三塔模型时,分别在标签召回模块和标签排序模块设置损失函数,公式如下:
27、loss=α·lossbinary+(1-α)·losstriplet
28、
29、losstriplet=max(d(a,p)-d(a,n)+margin)
30、其中,loss表示在区分父类标签样本和子类标签样本时设置的损失函数,α表示平衡二分类交叉熵损失的权重,lossbinary表示医疗文本与标签文本是否相似的的二分类交叉熵损失,y是二分类中两个样本对是否相似的真实值,是两个样本是否相似的预测值;losstriplet表示医疗文本、正样本标签文本、负样本标签文本之间的三元组损失,d(a,p)表示医疗文本与正样本标签文本的特征向量之间的距离,d(a,n)表示医疗文本与负样本标签文本的特征向量之间的距离,margin表示医疗文本和正标签文本以及负标签文本之间特征向量距离的差值。
31、步骤(5)的具体过程为:
32、利用编码器模块分别对所有的父类标签文本和子类文本标签进行处理,获取对应的特征向量库并进行离线存储;将父类标签离线特征向量库和子类标签文本离线特征向量库按照层级对应关系进行链接,以便快速根据父类标签离线特征向量库定位至子类标签离线特征向量库。
33、步骤(6)的具体过程为:
34、准备待预测医疗文本,使用训练完成的三塔模型中第一编码器获取待预测医疗文本的特征向量,使其与父类标签离线特征向量库中的父类标签进行相似性度量,获取文本对之间是否相似的的概率,根据相似的概率进行排序,并召回相似度较高的父类标签对应的子类标签文本的子类标签离线特征向量库;
35、再次将待预测医疗文本的特征向量与子类标签文本的离线特征向量库进行相似性度量,获取文本对之间是否相似的概率,然后根据相似的概率排序,获取其中相似度值高于相似度阈值的top-k预测标签文本。
36、与现有技术相比,本发明具有以下有益效果:
37、1、本发明提出了一个新的深度学习方法,该方法通过端到端的方法训练,充分发挥transformer神经网络的优势,利用动态负样本采样的方法对标签文本进行召回和排序,使得模型从简单样本到困难样本进行学习,同时本发明方法计算量小,运算速度快,大大提高了文本到标签的匹配效率。
38、2、本发明通过构建的三塔模型,在编码器模块获取高质量文本特征,进行多层次特征抽取,显著提高分类准确性;标签召回模块通过动态负样本采样和标签文本离线特征向量库的使用,有效减少在线计算的资源消耗,提高医疗文本分类效率;标签排序模块在正负标签中区分正确标签,确保分类结果准确可靠。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314736.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表