一种基于雷视融合的点云分割方法
- 国知局
- 2024-10-21 14:27:03
本发明涉及计算机视觉,具体涉及一种基于雷视融合的点云分割方法。
背景技术:
1、作为3d场景感知的一种重要方式,点云语义分割,即对三维点云数据进行分割和分类以识别不同物体或地物的类型和边界,在自动驾驶、机器人导航等领域具有重要应用。随着传感器技术的进步,尤其是激光雷达和摄像头的广泛应用,点云语义分割在近年来得到了迅猛的发展。激光雷达和摄像头是两种常用的传感器,它们在感知环境方面各有优势。激光雷达通过激光束测量物体的距离和形状,生成高密度的三维点云数据,具有较高的精度和可靠性,但在识别物体类别和语义信息方面有所不足。相比之下,摄像头可以提供丰富的颜色和纹理信息,有助于物体的识别和分类,但在复杂的光照和天气条件下性能可能受到影响。
2、为了实现更为准确可靠的点云语义分割,国内外工业界、学术界提出了很多方案。其中与本发明较为接近的技术方案包括:发明专利申请号:cn202410176680.6,名称:一种基于交叉注意力及多尺度特征融合的点云分割方法,阐述了一种对多尺度聚合特征进行解码来得到点云分割结果的方法,与本发明不同的是,该技术方案仅利用了激光雷达数据;
3、发明专利申请号:cn202210649696.5,名称:基于雷视语义分割自适应融合的车辆目标检测方法及系统,阐述了一种通过对图像和点云的分割结果进行融合得到车辆目标检测结果的方法,与本发明不同的是,该技术方案的融合策略侧重于结果层级,且仅预测车辆类的对象;
4、zhao lin等人(lif-seg:lidar and camera image fusion for 3d lidarsemantic segmentation[j].ieee transactions on multimedia,2023.)提出了一种通过偏置矫正优化多模态特征的空间对齐度的点云分割方法,与本方案不同的是,该方法仅考虑了多模态特征的空间差异。
5、尽管现有的点云分割技术方案均取得了不错的效果,但仍然存在着如下不足:
6、1)局限于单一模态数据:部分方案只利用了激光雷达的点云数据,点云是稀疏离散的三维坐标点,由于颜色和纹理信息的缺失,可能会导致算法对远距离和微小目标的误检或漏检,使得分割结果的准确性下降;
7、2)多模态信息融合不充分:部分方案采用结果级的粗略融合策略,无法充分发挥多模态数据在特征层级的互补作用;现有的采用特征级融合的方案仅考虑了多模态特征在空间域中的差异,未能有效解决多模态特征不对齐的问题。
技术实现思路
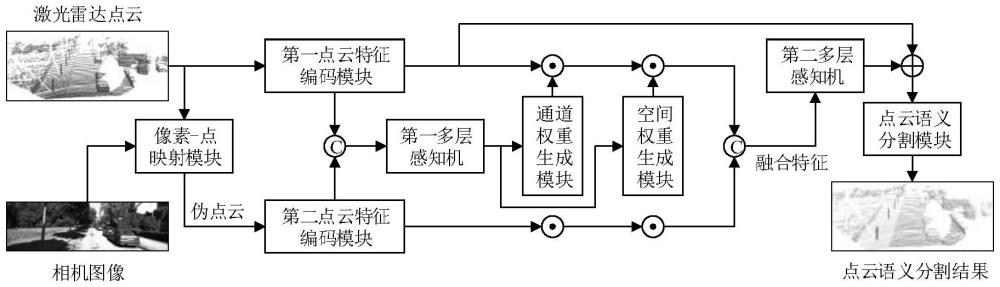
1、为了解决上述技术问题,本发明提供一种基于雷视融合的点云分割方法,即通过融合激光雷达和rgb相机数据,分别在空间域和通道域中对2d图像和3d点云两种模态的数据进行自适应融合,以获得丰富的细节信息,对3d点云进行准确的语义分割。
2、本发明包括如下步骤:
3、步骤1:采用激光雷达获取原生3d点云数据其中,n表示点的数量,pi和fi分别表示第i个点的坐标和特征,fi包括几何特征和反射强度,表示实数空间;通过相机设备获取2d图像数据其中,h、w分别表示图像的高和宽,和分别表示图像中第i个像素点的坐标和rgb颜色特征;
4、步骤2:计算三维点到像素点的映射关系,将2d图像的rgb颜色信息投影到3d点云上,生成伪点云其中,和分别表示第i个点的坐标和rgb颜色特征,具体为:
5、步骤2.1:对激光雷达和相机进行标定,获得相机的投影矩阵和激光雷达到相机的变换矩阵
6、步骤2.2:通过式(1)计算获得每个三维点到像素点的对应关系,将对应像素点的rgb颜色特征赋给三维点,由(2)式计算获得伪点云
7、
8、其中,表示像素点对应的rgb颜色特征;
9、步骤3:将原生点云x和伪点云输入到骨干网络中进行特征编码,分别得到两种不同模态的多尺度特征和其中,l表示特征层数,cl表示第l层特征的通道数;
10、步骤4:将步骤3所述的多尺度特征fl和分别在通道域和空间域中进行自适应加权融合,最终得到多模态融合特征具体为:
11、步骤4.1:将fl和进行拼接后输入到多层感知机mlp得到特征
12、步骤4.2:通过式(3)和式(4)分别计算得到特征flcm在通道域上的均值和最大值通过式(5)计算分别得到原生点云特征和伪点云特征的通道域权重
13、flavg=mlp(avg(flcm)) (3)
14、flmax=mlp(max(flcm)) (4)
15、
16、其中,σ表示sigmoid激活函数,avg和max分别表示空间域上的平均池化函数和最大值池化函数,用于计算每个通道上的平均值和最大值;
17、步骤4.3:将flcm输入多层感知机mlp,并经过sigmoid函数进行激活,分别得到原生点云特征和伪点云特征的空间域权重如式(6)所示:
18、(swlraw,swlpse)=σ(mlp(flcm)) (6)
19、步骤4.4:利用对应的通道域权重和空间域权重分别对与原生点云特征和伪点云特征进行加权,将加权后的特征进行拼接,并经过多层感知机mlp处理后与原生点云特征进行残差连接,得到多模态融合特征flfusion,如式(7)所示:
20、
21、其中,concat表示拼接函数,用于将两个特征张量在特征维度上进行拼接;
22、步骤5:将点云融合特征flfusion输入分割头进行特征解码,分割头由l个transformer解码块组成,解码块主要由掩码注意力层、自注意力层和线性层串联而成,具体为:
23、步骤5.1:首先需要将多尺度融合特征的通道数进行统一,即将l层融合特征全部映射成大小为的张量,其中,c表示特征的通道数;
24、步骤5.2:第1层融合特征经由线性层映射后得到所有点在k个类别上的预测分数生成随机初始化的查询查询qinit经由线性层映射后与第1层融合特征相乘得到m(m>k)个掩码提议将查询qinit、第1层融合特征和掩码提议输入掩码注意力层,再依次经过自注意力层和线性层的处理,输出查询
25、步骤5.3:将第1层解码块的输出作为第2层解码块的输出查询,同理步骤5.2,第2层解码块输出m个掩码提议p2、类别预测分数s2和查询以此类推,直到得到第l层解码块的输出结果,即pl、sl和其中每一层的掩码提议和类别预测分数均受到真实值的监督,在训练过程中计算相应的损失;
26、步骤5.4:将类别分数sl输入softmax函数进行处理后得再与掩码提议pl相乘,得到m个掩码预测及其对应的类别,最后合并所有掩码预测,得到最终的点云语义分割预测结果。
27、与现有技术相比,本发明具有以下优点:
28、1)本发明将图像中的rgb颜色信息投影到点云上以完成初步的特征对齐,又通过通道和空间权重生成模块分别在通道域和空间域中对多模态特征进行更进一步的对齐,减少多模态特征不对齐对分割结果的影响,充分利用多模态数据的优势;
29、2)本发明提出的通道和空间权重生成模块实现了自适应加权融合策略,利用可学习参数生成不同模态的权重,通过模型的训练实现权重优化,减少了人工调优的复杂度,并提高了算法的鲁棒性;
30、3)本发明采用基于掩码transformer架构的分割头对多尺度特征进行解码,每层特征都由对应的解码块进行逐层解码,每层解码块输出的掩码提议和类别分数都接收真实值的监督,深层监督策略充分利用了多尺度特征的信息,又强化了模型的学习效率。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318203.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。