基于Kcore和深度强化学习的网络瓦解方法及系统与流程
- 国知局
- 2024-11-06 14:24:06
本发明涉及计算机,尤其公开了一种基于kcore和深度强化学习的网络瓦解方法及系统。
背景技术:
1、网络分解是复杂网络科学领域中的一个关键挑战,随着时间的推移,它吸引了不同研究人员的持续关注。这一挑战围绕着识别节点的最小子集,删除这些节点将严重损害或完全丧失网络的操作功能。这个问题包含了许多广泛的实际应用。例如,在电力系统中,过载或故障等局部事件可能引发一系列级联故障,可能导致系统崩溃。然而,战略性地去除关键节点可以减轻这种风险,并防止这种灾难性的结果。
2、网络鲁棒性是一个基本指标,经常作为衡量网络拆除程度的标准。在之前的研究中,已经提出了许多鲁棒性度量,从基本的图连通性度量(如节点和边缘连通性)到更复杂的连通性增强度量(如超级连通性和条件连通性)。在这些指标中,k核的概念显得尤为重要,值得进一步研究。本质上,k核包含了一个结构属性,其中如果子图中的每个节点都连接到至少k个其他节点,则子图限定为k核。k核配置在网络中起着关键的作用,并与图的鲁棒性密切相关。
3、同样,k核的概念也可以应用于网络分解问题。通常,当k=2时,它被称为2核。在网络拆除过程中,二核发挥着独特的作用。当2核内的节点不是空时,它确保了图中存在循环结构;相反,当2核为空时,图会退化为树。现有的研究主要集中在手工设计的算法,如corehd或bpd,以解决k核问题。
4、因此,现有网络分解k核问题解决方法中存在的智能化程度低,是目前亟待解决的技术问题。
技术实现思路
1、本发明提供了一种基于kcore和深度强化学习的网络瓦解方法及系统,旨在解决现有k核问题解决方法中存在的智能化程度低的技术问题。
2、本发明的一方面涉及一种基于kcore和深度强化学习的网络瓦解方法,包括以下步骤:
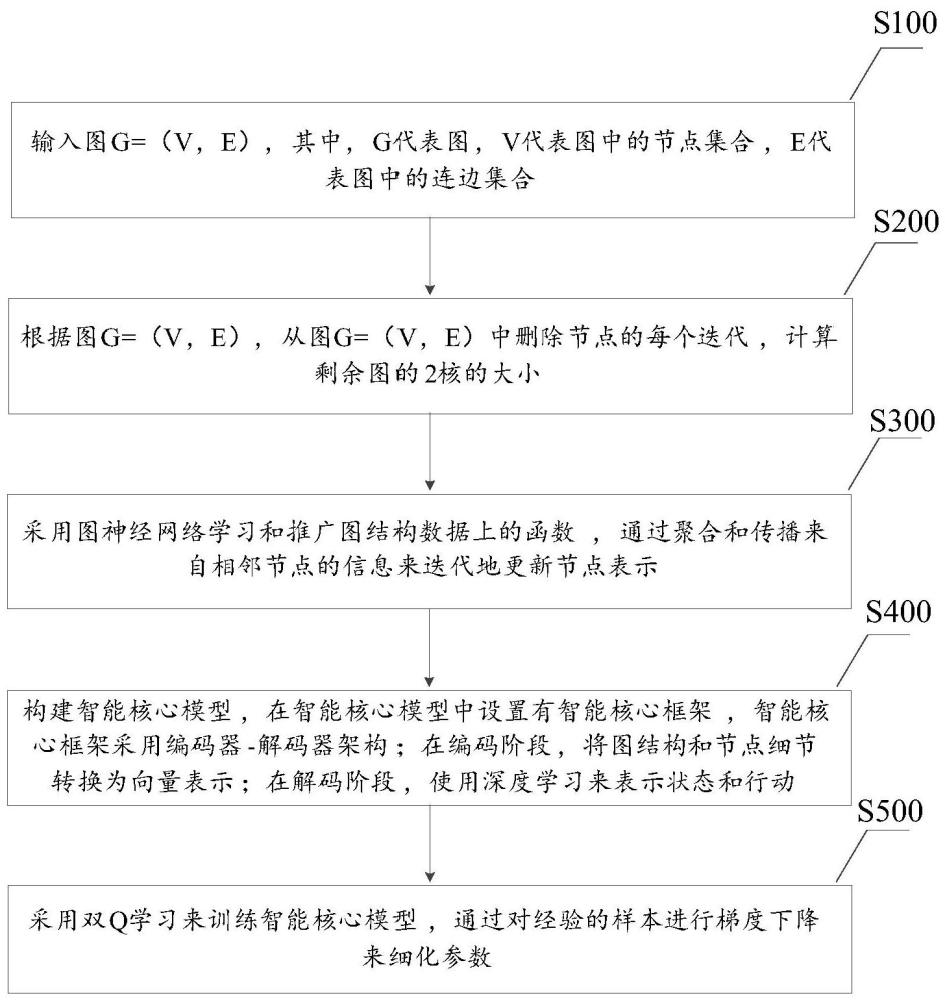
3、输入图g=(v,e),其中,g代表图,v代表图中的节点集合,e代表图中的连边集合;
4、根据图g=(v,e),从图g=(v,e)中删除节点的每个迭代,计算剩余图的2核的大小;
5、采用图神经网络学习和推广图结构数据上的函数,通过聚合和传播来自相邻节点的信息来迭代地更新节点表示;
6、构建智能核心模型,在智能核心模型中设置有智能核心框架,智能核心框架采用编码器-解码器架构;在编码阶段,将图结构和节点细节转换为向量表示;在解码阶段,使用深度学习来表示状态和行动;
7、采用双q学习来训练智能核心模型,通过对经验的样本进行梯度下降来细化参数。
8、进一步地,输入图g=(v,e)的步骤中,图g=(v,e)的核心为g'=(v',e'),其中,g'代表k核网络,v'代表k核子图中的节点集合,e'代表k核子图中的连边集合。
9、进一步地,根据图g=(v,e),从图g=(v,e)中删除节点的每个迭代,计算剩余图的2核的大小的步骤中,每个迭代的2核的相对大小定义为:
10、
11、其中,fi代表第i次迭代时2核网络的相对大小,ci表示第i次迭代后2核网络的大小,c0表示最初时2核网络的大小;
12、迭代后累积的2核大小是所有迭代的总和:
13、
14、其中,f代表第i次迭代后累积的二核网络相对大小,fi代表第i次迭代时2核网络的相对大小。
15、进一步地,采用图神经网络学习和推广图结构数据上的函数,通过聚合和传播来自相邻节点的信息来迭代地更新节点表示的步骤中,图神经网络的消息传递机制用以下公式来描述:
16、
17、
18、其中,表示第t步迭代后节点v汇聚邻居节点后所得的特征向量,aggregate(t)代表第t次时算法所用的聚合函数,代表t-1步迭代时v节点的邻居节点u的特征向量,u代表v节点的邻居节点,n(v)代表v节点的邻居节点集合,代表第t步骤时节点v的特征向量,combine(t)代表第t次迭代时算法使用的合并函数,代表第t-1步骤时节点v的特征向量,代表第t步迭代后节点v汇聚邻居节点后所得的特征向量。
19、进一步地,采用双q学习来训练智能核心模型,通过对经验的样本进行梯度下降来细化参数的步骤中,采用loss来计算损失:
20、loss=e(s,a,r,s′)~u(d)[(r+γq(s′,argmaxa′q(s′,a′))-q(s,a))2]
21、其中,loss代表模型的损失函数,e(s,a,r,s′)~u(d)[(r+γq(s′,argmaxa′q(s′,a′))-q(s,a))2]表示从样本池d利用均匀分布,u表示采样出的样本,(s,a,r,s′)表示未来期望,s表示当前状态,s′表示未来状态,a表示当前神经网络做出的动作,a′表示目标神经网络做出的动作,argmaxa′表示取使得q(s′,a′)最大时的动作a′,q(s′,a′)表示目标神经网络,q(s,a)表示在线神经网络,γ为折扣因子,r为奖励函数。
22、本发明的另一方面涉及一种基于kcore和深度强化学习的网络瓦解系统,包括:
23、输入模块,用于输入图g=(v,e),其中,g代表图,v代表图中的节点集合,e代表图中的连边集合;
24、计算模块,用于根据图g=(v,e),从图g=(v,e)中删除节点的每个迭代,计算剩余图的2核的大小;
25、学习模块,用于采用图神经网络学习和推广图结构数据上的函数,通过聚合和传播来自相邻节点的信息来迭代地更新节点表示;
26、构建模块,用于构建智能核心模型,在智能核心模型中设置有智能核心框架,智能核心框架采用编码器-解码器架构;在编码阶段,将图结构和节点细节转换为向量表示;在解码阶段,使用深度学习来表示状态和行动;
27、训练模块,用于采用双q学习来训练智能核心模型,通过对经验的样本进行梯度下降来细化参数。
28、进一步地,输入模块中,图g=(v,e)的核心为g'=(v',e'),其中,g'代表k核网络,v'代表k核子图中的节点集合,e'代表k核子图中的连边集合。
29、进一步地,计算模块中,每个迭代的2核的相对大小定义为:
30、
31、其中,fi代表第i次迭代时2核网络的相对大小,ci表示第i次迭代后2核网络的大小,c0表示最初时2核网络的大小;
32、迭代后累积的2核大小是所有迭代的总和:
33、
34、其中,f代表第i次迭代后累积的二核网络相对大小,fi代表第i次迭代时2核网络的相对大小。
35、进一步地,学习模块中,图神经网络的消息传递机制用以下公式来描述:
36、
37、
38、其中,表示第t步迭代后节点v汇聚邻居节点后所得的特征向量,aggregate(t)代表第t次时算法所用的聚合函数,代表t-1步迭代时v节点的邻居节点u的特征向量,u代表v节点的邻居节点,n(v)代表v节点的邻居节点集合,代表第t步骤时节点v的特征向量,combine(t)代表第t次迭代时算法使用的合并函数,代表第t-1步骤时节点v的特征向量,代表第t步迭代后节点v汇聚邻居节点后所得的特征向量。
39、进一步地,训练模块中,采用loss来计算损失:
40、loss=e(s,a,r,s′)~u(d)[(r+γq(s′,argmaxa′q(s′,a′))-q(s,a))2]
41、其中,loss代表模型的损失函数,e(s,a,r,s′)~u(d)[(r+γq(s′,argmaxa′q(s′,a′))-q(s,a))2]表示从样本池d利用均匀分布,u表示采样出的样本,(s,a,r,s′)表示未来期望,s表示当前状态,s′表示未来状态,a表示当前神经网络做出的动作,a′表示目标神经网络做出的动作,argmaxa′表示取使得q(s′,a′)最大时的动作a′,q(s′,a′)表示目标神经网络,q(s,a)表示在线神经网络,γ为折扣因子,r为奖励函数。
42、本发明所取得的有益效果为:
43、本发明提供一种基于kcore和深度强化学习的网络瓦解方法及系统,通过输入图g=(v,e);根据图g=(v,e),从图g=(v,e)中删除节点的每个迭代,计算剩余图的2核的大小;采用图神经网络学习和推广图结构数据上的函数,通过聚合和传播来自相邻节点的信息来迭代地更新节点表示;构建智能核心模型,在智能核心模型中设置有智能核心框架,智能核心框架采用编码器-解码器架构;在编码阶段,将图结构和节点细节转换为向量表示;在解码阶段,使用深度学习来表示状态和行动;采用双q学习来训练智能核心模型,通过对经验的样本进行梯度下降来细化参数。本发明提供的基于kcore和深度强化学习的网络瓦解方法及系统,利用图神经网络来最小化累积的2核大小的端到端模型;在合成数据集和真实数据集上的大量实验表明,智能核心在准确性和速度方面都优于现有的方法,这表明智能核心在实践中应该是网络分解问题的一个更好的选择。
本文地址:https://www.jishuxx.com/zhuanli/20241106/321845.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表