一种在高维近似最近邻搜索中持续优化图结构的框架
- 国知局
- 2024-11-06 14:45:10
本发明涉及近似最近邻搜索,尤其是涉及一种在高维近似最近邻搜索中持续优化图结构的框架。
背景技术:
1、随着深度学习在各个领域的快速发展,使用向量来表示实体已成为一种普遍趋势。现在很多应用都需要在大型数据库中找到与给定查询点最相似的点,这就是近邻搜索问题,广泛应用于人脸识别、推荐系统、信息检索等场景。由于“维度诅咒”,在高维数据集中寻找精确的近邻通常需要大量计算。近似近邻搜索(anns)可以在有限的空间和时间限制下,以可接受的偏差来检索到最近的邻居,因此受到了广泛关注。其允许的偏差以召回率来量化。其中topk召回率表示搜索到的topk个最近邻和精确topk个最近邻的交集的比例。
2、现在已经有许多anns的方法,如基于图的方法、基于树的方法和基于散列的方法。大量研究表明,基于图的算法显示出卓越的搜索性能。基于图的方法首先构建一个近邻图,其中每个节点代表数据库中的一个基本数据点,边连接相似点。为了找到查询点的最近邻点,它们通常会在图索引上选取一个起点,然后贪心地遍历到与查询点最近的目标点。此外,k-最近邻(k-nns)图被用来维护相似点的连接,其中,如果节点u是v的k-nns之一,则节点v与节点u以有向边连接。
3、为了减少空间占用和提高搜索效率,最近的研究在建立近邻图索引时采用了相对近邻图(rng)和单调相对近邻图(mrng)边剪枝策略来删除k-nns图中的边。然而,由于对边的剪枝,在近邻图上的查询可能会返回有偏差的结果,甚至无法检索到近邻。此外,基于图的索引在构建后将保持静态,那么之前失败的类似查询将一再失败,导致召回率很低。换句话说,使用前述方法构建的基于图的索引存在“缺陷”,无法准确检索查询点的最近邻。如何弥补这些缺陷,从而以可接受的空间成本提高基于图的索引的准确性,是anns课题长期面临的问题。为此,本发明提供了一种在高维近似最近邻搜索中持续优化图结构的框架。
技术实现思路
1、本发明的目的是提供一种在高维近似最近邻搜索中持续优化图结构的框架,利用搜索日志和构建日志来动态增强图和补充搜索结果,从而在可接受的空间成本增加的情况下显著提高查询准确性。
2、为实现上述目的,本发明提供了一种在高维近似最近邻搜索中持续优化图结构的框架,包括以下步骤:
3、步骤1:收集目标数据,目标数据的数据信息包括数据量、数据类型、维度、向量和距离度量,向量在目标数据中的顺序作为每个向量的id,将目标数据根据用户指定的分割比例分割成底库数据、历史数据和测试数据三个部分;
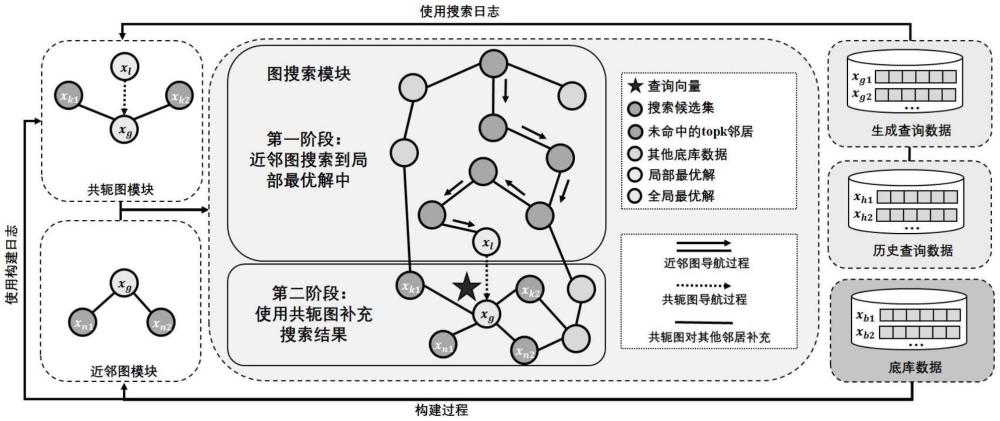
4、步骤2:搭建在高维近似最近邻搜索中持续优化图结构的框架的环境,该环境包括近邻图模块、共轭图模块、图搜索模块;
5、步骤3:基于底库数据,在近邻图模块构建近邻图索引,在构建过程中,记录并整合被裁剪的边作为构建日志,构建日志用于在共轭图模块中构建共轭图索引;
6、步骤4:基于底库数据,使用启发式的方法生成数据,具体步骤如下:
7、41):接受三个参数分别为搜索参数k、搜索列表长度l、一个浮点数w,初始化数据集合;
8、42):遍历每个底库数据,使用步骤2中的图搜索模块,在近邻图上使用长度为l的搜索列表查询k个近似最近邻;
9、43):在遍历的过程中,表示底库数据为xb,对k个近似最近邻分别表示成xk,使用公式生成数据xg=w xb+(1-w)xk,并将其加入生成的数据集合中;
10、44):重复步骤42)至步骤43)的遍历程序,直至所有底库数据被处理完成;
11、45):返回生成的数据集合;
12、步骤5:基于历史和生成的数据,在图搜索模块中搜索其在底库数据中的全局最优解和局部最优解,对于其中找到的全局最优解和局部最优解不一致的数据,记录成搜索日志并作为需要在共轭图中加边的对象;
13、步骤6:利用步骤5中的搜索日志,更新共轭图模块中的共轭图索引:遍历搜索日志中的每对局部最优解和全局最优解,在共轭图中添加一条从局部最优解到全局最优解的边;
14、步骤7:基于测试数据,结合近邻图模块和共轭图模块,测试优化前后的性能和效果对比。
15、优选的,步骤2中构建近邻图模块的具体步骤为:
16、211)近邻图索引构建:接受参数为底库数据和距离度量,构建近邻图索引并存储底库数据,近邻图索引是一个由邻接表构成的图索引,每个底库数据作为近邻图中的一个节点,每条从节点u指向节点v的有向边代表v是底库数据中离u在指定的距离度量较近的另一条数据,对应在数据结构上,每条底库数据都在邻接表中拥有一个列表,列表存有其在近邻图中的邻居,底库数据的存储采用列表的方式,列表的每一行为一条底库向量,行数为底库向量数,列数为底库向量维度;
17、212)近邻图索引更新:接受参数为起点id和终点id,向邻接表中起点id的列表中插入终点id;
18、213)邻居检索:接受参数为一个id,若该id在邻接表中存在,则返回其对应的列表,否则返回空;
19、214)、距离计算:接受参数为两个向量,计算两个向量在索引构建时指定的距离度量下的距离并返回。
20、优选的,步骤2中构建共轭图模块的具体步骤为:
21、221)共轭图索引构建:对共轭图初始化,初始化为一个空的稀疏图,使用哈希表和集合来实现,其中哈希表的键为底库数据的id,哈希表的值为一个集合;
22、222)共轭图索引更新:接受参数为起点id和终点id,其向哈希表中值为起点id的集合中插入终点id;
23、223)邻居检索:接受参数为一个id,若该id在哈希表中作为键存在,则返回其值对应的集合,否则返回空集。
24、优选的,步骤2中图搜索模块的具体内容为:
25、231)暴力搜索:接受两个参数分别为:查询向量和一个整数k,用于在已经建好的近邻图索引上搜索查询向量的k个精确最近邻;暴力搜索过程中,维护一个最大大小为k的最大堆,遍历近邻图中存储的所有底库向量,并计算查询向量和底库向量的距离,将其加入到最大堆中,具体来说,如果最大堆的大小小于k,则将该底库向量和距离插入其中,如果等于k,则判断该次计算距离是否比最大堆顶的距离小,如果是的话,则将最大堆顶的数据弹出,并插入该次计算的底库数据和距离,直至历遍完所有底库向量后,最大堆中的数据即为k个精确最近邻;
26、232)近似最近邻搜索:接受四个参数分别为:查询向量、一个整数k、搜索列表长度l和是否使用共轭图,上述四个参数用于在已经建好的近邻图索引上搜索查询向量的k个近似最近邻,具体方法为:
27、2321)不使用共轭图的搜索:搜索过程使用贪心搜索,贪心搜索过程中,维护一个最大大小为l的搜索列表,初始化使用一个固定的底库数据插入进入搜索列表中,然后进入迭代过程,每次选取搜索列表中离查询向量最近的没有被访问的底库数据,将该数据在近邻图中的邻居加入到搜索列表中,注意,在加入搜索列表的时候需要计算邻居到查询向量的距离,如果搜索列表已满并且该距离大于搜索列表中的数据离查询向量的最大距离,则不能被加入搜索列表中,否则,在搜索列表已满时,须将最大距离对应的数据弹出,并将新的邻居数据加入到搜索列表中,在完成邻居的加入后,将该底库数据标记为被访问过,在若干次迭代后,搜索列表中的所有数据都被访问过,循环终止,返回搜索列表内的前k小距离对应的底库数据作为k个近似最近邻查询结果;
28、2322)使用共轭图的搜索过程:首先重复上述贪心搜索的搜索过程,在贪心搜索结束后,计算搜索结果中的top1最近邻即局部最优解,然后在共轭图中取出该局部最优解所连的所有底库数据,加入到搜索列表中,并根据数据到查询数据的距离进行重排序,重排后计算新的局部最优解,如果新的局部最优解和旧的不同,则继续将其在共轭图中所连的底库数据加入到搜索列表中,并将搜索列表中的数据进行重排序,返回搜索列表的前k小距离对应的底库数据作为k个近似最近邻查询结果。
29、优选的,步骤3的具体步骤为:
30、31)接受三个参数分别为最大出度r、构建搜索列表长度l和构建搜索参数k,其中,参数r限制了每个底库数据在近邻图中最多有r个邻居,参数l限制了在构建时使用近似最近邻搜索的搜索列表长度为l,参数k限制了在构建时搜索k个近似最近邻;
31、32)遍历每个底库数据,使用步骤232)的近似最近邻搜索程序,在近邻图上使用长度为l的搜索列表查询k个近似最近邻;
32、33)在遍历的过程中,基于查询结果,进行裁边;
33、34)将裁边后剩下的边,如果数量小于等于r,则将所有边作为有向边插入到近邻图中,如果数量大于r,则选取距离最短的前r条边作为有向边插入到近邻图中;
34、35)将裁边时被裁剪掉的边,如果数量小于等于r,则将所有边作为有向边插入到共轭图中,如果数量大于r,则选取距离最短的前r条边作为有向边插入到共轭图中;
35、36)重复步骤32)至步骤35)的遍历程序,直至所有底库数据被处理完成;
36、37)返回构建完成的近邻图索引和共轭图索引。
37、优选的,步骤3中33)所述的裁边的方法应用rng裁边策略或mrng裁边策略,rng裁边策略即将所有三个数据构成的三角形中的最长边消去,mrng裁边策略用于保证裁剪后的所有出边的夹角都小于60度。
38、优选的,步骤5的具体步骤为:
39、51)、将历史和生成的数据整合成一个数据集合;
40、52)、遍历数据集合的每个点,使用图搜索模块中构建的暴力搜索程序搜索出k个精确最近邻结果,使用图搜索模块中构建的近似最近邻搜索程序搜索出k个近似最近邻结果;
41、53)、将精确最近邻结果中的top1最近邻记为全局最优解,将近似最近邻结果中的top1最近邻记为局部最优解,如果全局最优解和局部最优解不同的话,将这一局部最优解和全局最优解对记录作为搜索日志。
42、优选的,步骤7的具体步骤为:
43、71):遍历测试数据的每条数据,使用步骤231)中构建的暴力搜索程序搜索出k个精确最近邻结果r1,使用步骤232)中构建的不使用共轭图的近似最近邻搜索程序搜索出k个近似最近邻结果r2,使用步骤232)中构建的使用共轭图的近似最近邻搜索程序搜索出k个近似最近邻结果r3;
44、72):计算r1和r2的召回率为使用共轭图优化前的召回率,计算r1和r3的召回率为使用共轭图优化后的召回率,两者之差即为优化效果。
45、因此,本发明采用上述结构的在高维近似最近邻搜索中持续优化图结构的框架,具有如下有益效果:
46、1、本发明利用了搜索日志和构建日志来对图索引进行优化。优化产生的共轭图可以被用于补充搜索结果,并且不损失搜索的效率。
47、2、本方法使用了生成搜索日志和历史搜索日志中局部最优解到全局最优解的信息,添加局部最优解到全局最优解的连边在共轭图中。进而在未来的搜索过程中,如果相似的查询向量落在了这个局部最优解中,共轭图中的边即可将其导航至全局最优解。进而提升搜索的top1最近邻的召回率。
48、3、本方法使用了构建过程中的构建日志,将被裁剪的边添加到共轭图中。进而在未来的搜索过程中,可以使用这些被裁剪的边补充topk最近邻的搜索结果。进而提升搜索的topk最近邻的召回率。
49、4、本方法可以广泛应用于向量数据库领域,可以提高近似最近邻搜索的top1和topk最近邻的召回率。
50、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本文地址:https://www.jishuxx.com/zhuanli/20241106/323933.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。