基于多重交织深度学习模型的电网数据校核方法、系统、设备及存储介质与流程
- 国知局
- 2024-11-19 09:51:36
本发明属于电力系统中的电网数据校核,具体为一种基于多重交织深度学习模型的电网数据校核方法、系统、设备及存储介质。
背景技术:
1、卷积神经网络(convolutional neural network,cnn)是一种深度学习技术,主要用于处理图像和其他二维数据,在计算机视觉、图像识别和模式分类等领域取得了巨大成功。cnn由卷积层、池化层和全连接层组成,其中卷积层是cnn的核心,使用卷积核(也成为滤波器)来扫描输入图像,从中提取特征。卷积操作有效地减少了需要训练的参数量,使得cnn适用于大规模的数据;池化层用于减小特征图的尺寸,同时保留重要信息。最常见的池化操作是最大池化,它选择每个区域中的最大值作为输出,有助于减少计算量并提高模型的鲁棒性;全连接层在卷积和池化之后,用于将特征映射转化为最终的分类或回归结果。全连接层的神经元与前一层的所有神经元相连,形成一个密集连接的网络。cnn的应用范围广泛,包括人脸识别、自动驾驶、医学图像分析等,它的成功部分归功于其对图像中局部特征的有效捕捉能力,以及对大规模数据集的训练。
2、门控循环单元(gated recurrent unit,gru)是一种简化而性能强大的循环神经网络(recurrent neural network,rnn)结构,旨在更好地捕捉时间序列中时间步之间较大的依赖关系。gru引入了门的概念,其结构主要包括四大部分:重置门、更新门、候选隐藏状态、隐藏状态。重置门的作用是帮助捕捉时间序列中的短期依赖关系;更新门的作用是捕捉时间序列中的长期依赖关系;候选隐藏状态根据当前输入和前一个隐藏状态计算得出;隐藏状态是最终的输出状态。gru的每个隐藏单元都有独立的重置门和更新门,因此可以学会捕捉不同时间范围内的依赖关系。gru作为rnn的一种变体,在自然语言处理、语音识别、时间序列预测等领域均表现出惊人的能力。
3、在电网系统中,提高电网利用率、降低电网损耗是各个电力公司亟待解决的问题之一。由于用电用户较多,配电网络中的沉重负荷不断加重,受网络中各种不定因素的影响,电力系统中的电压容易出现不稳定的情况,如果电压过高,严重时会产生电压崩溃、火灾等严重事故。因此,如何及时检测到电网中的异常数据成为保护电网安全的关键。
4、电网系统运行过程中会产生大量电网数据,比如温度、湿度、压力、纹波、真空、磁场、热电偶、热电阻、电压、电流、电阻、频率等运行数据,这些数据不仅彼此之间存在一定的联系,并且在一定时间范围内的动态变化也存在一定的联系。传统配电网在检测异常数据时,需要人为地设定异常数据的阈值,且对于缺失数据的填补也效率低下。
技术实现思路
1、发明目的:为解决传统配电网在检测异常数据时,需要人为地设定异常数据的阈值,且对于缺失数据的填补也效率低下等问题,本发明针对电网数据的特点,提出了一种基于多重交织深度学习模型的电网数据校核方法、系统、设备及存储介质,利用电网数据间的内在联系和数据在时序上的联系,动态为每一个数据生成判定阈值,从而实现实时监测电网中异常数据的目的,保障电网安全运营。
2、技术方案:一种基于多重交织深度学习模型的电网数据校核方法,包括以下步骤:
3、步骤1:同一抽样时刻的所有电网数据称作一组数据,取i个抽样时刻的电网数据作为i组历史数据,取第i+1个抽样时刻的一组电网数据作为一组预测数据,将该组预测数据复制i份作为i组预测数据;
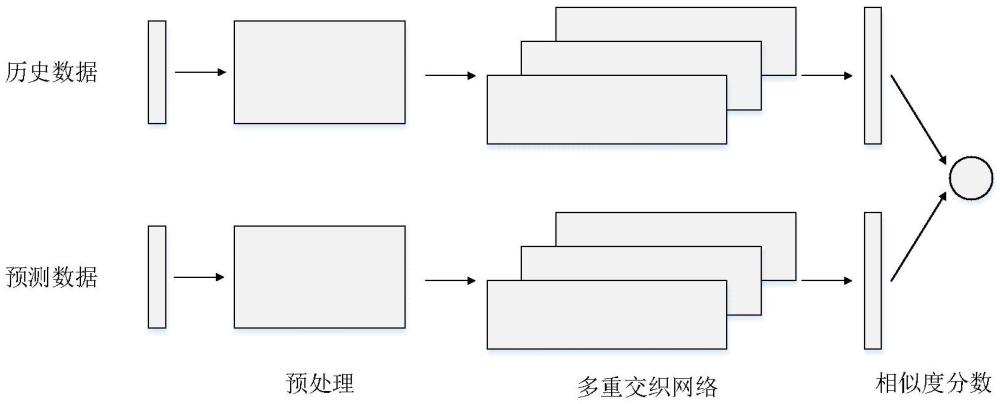
4、步骤2:对每组历史数据和每组预测数据进行预处理,得到各自固定大小的嵌入矩阵;
5、步骤3:采用训练好的多重交织深度学习模型对每组历史数据和每组预测数据对应的嵌入矩阵进行特征提取和最大池化处理,得到每组历史数据和每组预测数据对应的向量表示形式;然后采用相似度计算公式,计算每组历史数据与其对应组的预测数据之间的匹配程度,根据匹配程度输出电网数据校核结果。
6、进一步的,所述对每组历史数据和每组预测数据进行预处理,得到各自固定大小的嵌入矩阵,具体操作包括:
7、首先,对每组历史数据和每组预测数据进行清洗;
8、其次,利用gensim工具,得到适合的嵌入模型;
9、最后,嵌入模型通过查表将每组历史数据和每组预测数据映射为一个固定长度的嵌入矩阵,对于在嵌入模型中找不到对应关系的电网数据,将被映射为同等长度的零向量。
10、进一步的,所述多重交织深度学习模型由多个单重交织网络的叠加构成;每个单重交织网络的输入为步骤2得到的嵌入矩阵,输入的嵌入矩阵经过双向门控循环单元bi-gru得到一个关注到嵌入矩阵内部各抽样时刻之间关联的、与原嵌入矩阵大小相同的新的嵌入矩阵;新的嵌入矩阵与输入的嵌入矩阵相加后送入卷积神经网cnn,以提取单个抽样时刻内部各电网数据之间的关联特征。
11、进一步的,每个单重交织网络的输入输出形状相同。
12、进一步的,所述卷积神经网cnn中采用的卷积核的长度与嵌入矩阵长度保持相同。
13、进一步的,所述的进行特征提取和最大池化处理,具体包括:所有单重交织网络叠加产生的最终特征矩阵,再经过最大池化处理,得到每组历史数据和每组预测数据对应的向量表示形式。
14、进一步的,所述的进行特征提取和最大池化处理,具体包括:每层单重交织网络产生的特征矩阵经过最大池化处理,得到向量;再将所有向量进行堆叠得到每组历史数据和每组预测数据对应的向量表示形式。
15、进一步的,按照以下步骤得到训练好的多重交织深度学习模型:
16、将所有历史数据和所有预测数据对应的嵌入矩阵、以及带有历史数据和预测数据之间匹配/不匹配的标签,当匹配时,标签为1,当不匹配时,标签为0;输入至多重交织深度学习模型中,利用多重交织深度学习模型计算历史数据和预测数据之间的匹配得分;
17、在训练阶段,使用以下边际损失函数指导多重交织深度学习模型中参数的更新,使用adam优化算法来训练多重交织深度学习模型和更新参数:
18、
19、其中,n为(h,p+,p-)三元组的数量,h表示一组历史数据,p+表示一组匹配该组历史数据的预测数据,p-表示一组不匹配该组历史数据的预测数据;m为一个常量,用于控制匹配预测数据与不匹配预测数据的边缘;在训练过程中,该边际损失函数使某历史数据与其匹配的预测数据之间的匹配得分越来越高,与其不匹配的预测数据之间的匹配得分越来越低,直到匹配预测数据比不匹配预测数据之间的匹配度得分高出m。
20、进一步的,各单重交织网络的网络参数相互独立。
21、本发明公开了一种基于多重交织深度学习模型的电网数据校核系统,包括:
22、数据预处理模块,用于取i个抽样时刻的电网数据作为i组历史数据,取第i+1个抽样时刻的一组电网数据作为一组预测数据,将该组预测数据复制i份作为i组预测数据;对每组历史数据和每组预测数据进行预处理,得到各自固定大小的嵌入矩阵;
23、电网数据校核模块,用于采用训练好的多重交织深度学习模型对每组历史数据和每组预测数据对应的嵌入矩阵进行特征提取和最大池化处理,得到每组历史数据和每组预测数据对应的向量表示形式;然后采用相似度计算公式,计算每组历史数据与其对应组的预测数据之间的匹配程度,根据匹配程度输出电网数据校核结果。
24、进一步的,所述对每组历史数据和每组预测数据进行预处理,得到各自固定大小的嵌入矩阵,具体操作包括:
25、首先,对每组历史数据和每组预测数据进行清洗;
26、其次,利用gensim工具,得到适合的嵌入模型;
27、最后,嵌入模型通过查表将每组历史数据和每组预测数据映射为一个固定长度的嵌入矩阵,对于在嵌入模型中找不到对应关系的电网数据,将被映射为同等长度的零向量。
28、进一步的,所述多重交织深度学习模型由多个单重交织网络的叠加构成;每个单重交织网络的输入为步骤2得到的嵌入矩阵,输入的嵌入矩阵经过双向门控循环单元bi-gru得到一个关注到嵌入矩阵内部各抽样时刻之间关联的、与原嵌入矩阵大小相同的新的嵌入矩阵;新的嵌入矩阵与输入的嵌入矩阵相加后送入卷积神经网cnn,以提取单个抽样时刻内部各电网数据之间的关联特征。
29、进一步的,每个单重交织网络的输入输出形状相同,各单重交织网络的网络参数相互独立。
30、进一步的,所述卷积神经网cnn中采用的卷积核的长度与嵌入矩阵长度保持相同。
31、进一步的,所述的进行特征提取和最大池化处理,具体包括:所有单重交织网络叠加产生的最终特征矩阵,再经过最大池化处理,得到每组历史数据和每组预测数据对应的向量表示形式。
32、进一步的,所述的进行特征提取和最大池化处理,具体包括:每层单重交织网络产生的特征矩阵经过最大池化处理,得到向量;再将所有向量进行堆叠得到每组历史数据和每组预测数据对应的向量表示形式。
33、进一步的,按照以下步骤得到训练好的多重交织深度学习模型:
34、将所有历史数据和所有预测数据对应的嵌入矩阵、以及带有历史数据和预测数据之间匹配/不匹配的标签,当匹配时,标签为1,当不匹配时,标签为0;输入至多重交织深度学习模型中,利用多重交织深度学习模型计算历史数据和预测数据之间的匹配得分;
35、在训练阶段,使用以下边际损失函数指导多重交织深度学习模型中参数的更新,使用adam优化算法来训练多重交织深度学习模型和更新参数:
36、
37、其中,n为(h,p+,p-)三元组的数量,h表示一组历史数据,p+表示一组匹配该组历史数据的预测数据,p-表示一组不匹配该组历史数据的预测数据;m为一个常量,用于控制匹配预测数据与不匹配预测数据的边缘;在训练过程中,该边际损失函数使某历史数据与其匹配的预测数据之间的匹配得分越来越高,与其不匹配的预测数据之间的匹配得分越来越低,直到匹配预测数据比不匹配预测数据之间的匹配度得分高出m。
38、本发明公开了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现一种基于多重交织深度学习模型的电网数据校核方法的步骤。
39、本发明公开了一种存储介质,所述存储介质存储有电网数据校核程序,所述电网数据校核程序被至少一个处理器执行时实现一种基于多重交织深度学习模型的电网数据校核方法的步骤。
40、有益效果:本发明与现有技术相比,具有以下优点:
41、(1)本发明使用多个不同抽样时刻的历史数据来预测下一抽样时刻的数据,通过计算历史数据和预测数据之间的匹配度得分判断电网数据是否异常,从而达到数据校核的目的,具有响应速度快、识别准确度高等优点;
42、(2)本发明使用cnn关注单个抽样时刻不同电网数据之间的内在联系,使用gru关注不同抽样时刻同一电网数据在时序上的内在联系,从不同角度、不同维度进行数据校核,可以提高模型的校核效率;
43、(3)本发明使用经过特殊设计的cnn卷积核进行特征提取,可以保证一组抽样数据的完整性,提高模型的准确率;同时cnn和gru的参数也进行了特殊设计,使得单重交织网络的输入输出形状相同,可以叠加使用,增加了模型的灵活性;
44、(4)本发明相较于传统数据校核而言更加高效准确,同时自动化程度高,可以降低人工成本。
本文地址:https://www.jishuxx.com/zhuanli/20241118/330451.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表