基于深度学习的3D虚拟形象模型训练方法与流程
- 国知局
- 2024-11-21 12:00:42
本发明涉及计算机,特别涉及基于深度学习的3d虚拟形象模型训练方法。
背景技术:
1、3d虚拟形象,作为现代计算机图形学和数字艺术的杰出代表,是数字化时代的重要产物。在娱乐、教育、医疗和工业设计等多个领域,3d虚拟形象均展现出强大的应用潜力和价值。其不仅能够为用户提供沉浸式的体验,还能够在不同场景中模拟现实世界的交互与行为,为人们的数字生活带来更加丰富多彩的体验。
2、随着科技的飞速发展,深度学习在图像处理、计算机视觉等领域展现出强大的潜力。特别是在3d虚拟形象生成方面,传统的技术方法已难以满足高质量、高效率的需求。因此,基于深度学习的3d虚拟形象模型训练方法应运而生。
3、而在实际的操作中还存在以下问题:
4、现有方法无法高效地从2d图像中提取关键特征信息,导致重建的3d模型质量不高,同时传统的训练方法可能效率低下,无法充分利用计算资源,导致训练过程漫长,无法准确衡量生成的3d模型的质量。
技术实现思路
1、本发明的目的在于提供基于深度学习的3d虚拟形象模型训练方法,以解决上述背景技术中提出的问题。
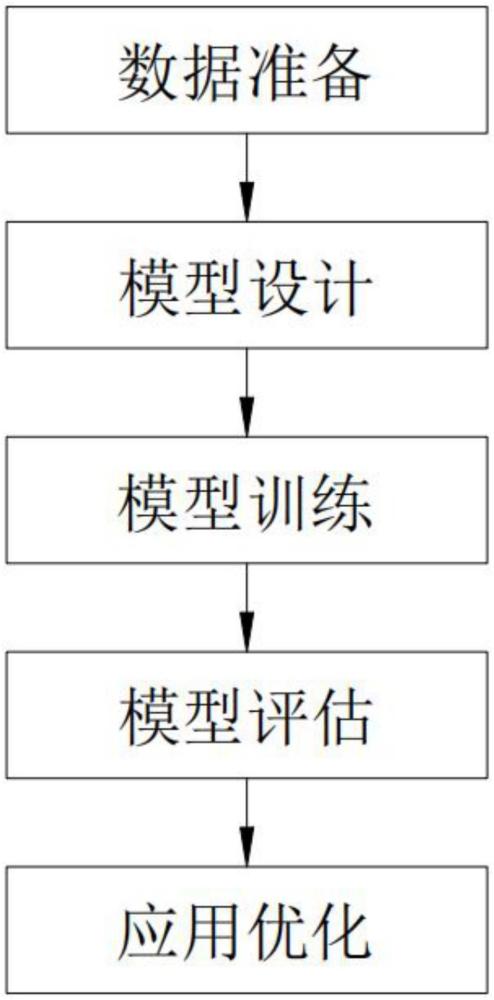
2、为实现上述目的,本发明提供如下技术方案:基于深度学习的3d虚拟形象模型训练方法,包括以下步骤:
3、数据准备,获取训练数据,所述训练数据包括2d图像和对应的3d模型,其中,2d图像包括人脸、全身以及身体部位的特写,3d模型包括对应的详细几何形状和纹理,对2d图像进行预处理,调整输入数据的一致性,对3d模型进行统一格式转换,并对转换后的3d模型进行缩放和旋转调整;
4、模型设计,搭建一个包含卷积神经网络和自编码器的深度学习模型,其中,卷积神经网络用于提取2d图像中的特征信息,自编码器用于学习数据的编码和解码过程并重建出3d模型,将预处理后的2d图像输入到深度学习模型中,通过卷积神经网络提取出人脸的关键特征信息,并将关键特征信息编码为低维的向量表示,基于编码后的特征向量,将低维向量解码为3d模型数据;
5、模型训练,构建损失函数指导深度学习模型的训练,其中,所述损失函数用于衡量生成的3d模型与目标3d模型之间的差异,使用收集到的训练数据对深度学习模型进行训练,在训练过程中优化模型的参数,同时,通过验证集监控模型的性能,并在验证集表现良好时保存模型的参数;
6、模型评估,在训练完成后,使用测试集对模型进行评估衡量模型的性能,评估指标包括重建误差、用户满意度,根据评估结果对模型进行模型调整,模型调整包括模型架构调整、参数调整以及损失函数调整;
7、应用优化,将训练好的3d虚拟形象模型进行实际应用,所述实际应用包括艺术创作、游戏设计、虚拟试衣,在实际应用过程中,收集用户反馈和数据,对模型进行优化和改进。
8、进一步的,所述数据准备,具体还包括以下步骤:
9、获取包含不同人脸、全身以及身体部位特写的2d图像,同时收集与所述2d图像相对应的3d模型,所述3d模型包括设备扫描模型、手动创建模型或建模软件生成模型;
10、裁剪去除2d图像的背景部分使目标区域成为图像的中心,所述目标区域包括人脸、全身,将图像缩放到256x256像素尺寸,并进行归一化处理,将像素值映射到[0,1]或[-1,1]范围内;
11、将所有3d模型转换为统一的文件格式,将各3d模型的原点进行统一设置,确保所有3d模型的坐标系统对齐;
12、将各个2d图像与其对应的3d模型配对,并保存配对信息。
13、进一步的,所述数据准备,还包括:
14、提取缩放操作之前的目标区域的区域形状,作为第一区域形状数据;
15、提取缩放操作之后的目标区域的区域形状,作为第二区域形状数据;
16、利用所述第一区域形状数据和第二区域形状数据获取形状变化参数;其中,所述形状变化参数通过如下公式获取:
17、
18、其中,rx表示形状变化参数;rx0表示预设的形状变化参数的基准数值;sy表示预设的形状相似度阈值;sx表示缩放操作之前的目标区域的区域形状和缩放操作之后的目标区域的区域形状之间的形状相似度数值;x表示第一调节系数,并且,所述第一调节系数通过如下公式获取:
19、
20、其中,x表示第一调节系数;m×m表示缩放操作之前的目标区域的像素尺寸,与缩放后的目标区域对应的目标像素尺寸256x256相对应;
21、将所述形状变化参数与预设的形状变化参数阈值进行比较;
22、当所述形状变化参数超过预设的形状变化参数阈值时,则判定所述目标区域缩放质量异常,并进行异常报警;
23、当所述形状变化参数未超过预设的形状变化参数阈值时,则利用所述缩放操作之前的目标区域和缩放操作之后的目标区域的灰度值变化参数对目标区域缩放质量进行二次异常判定。
24、进一步的,当所述形状变化参数未超过预设的形状变化参数阈值时,则利用所述缩放操作之前的目标区域和缩放操作之后的目标区域的灰度值变化参数对目标区域缩放质量进行二次异常判定,包括:
25、提取缩放操作之前的目标区域所包含的像素块的灰度值,作为第一区域灰度值数据;
26、提取缩放操作之后的目标区域所包含的像素块的灰度值,作为第二区域灰度值数据;
27、将所述第一区域灰度值数据中的灰度值为0和灰度值为255的灰度数值提出,形成第一像素值集合;
28、将所述第二区域灰度值数据中的灰度值为0和灰度值为255的灰度数值提出,形成第二像素值集合;
29、利用所述第一像素值集合和第二像素值集合获取灰度变化参数,其中,所述灰度变化参数通过如下公式获取:
30、
31、其中,rh表示灰度变化参数;rh0表示预设的灰度变化参数的基准数值;h01max和h01min分别表示第一像素值集合中所包含的灰度最大值和灰度最小值;h02max和h02min分别表示第二像素值集合中所包含的灰度最大值和灰度最小值;r表示第二调节系数,并且,所述第二调节系数通过如下公式获取:
32、
33、其中,r表示第二调节系数;a表示第一像素值集合中所包含的灰度值元素的个数;b表示第二像素值集合中所包含的灰度值元素的个数;hi表示第一像素值集合中的第i个灰度值的对应数值;hi-1表示第一像素值集合中的第i-1个灰度值的对应数值;hp01表示第一像素值集合中灰度值元素对应的灰度平均值;hj表示第二像素值集合中的第j个灰度值的对应数值;hi-1表示第二像素值集合中的第j-1个灰度值的对应数值;hp02表示第二像素值集合中灰度值元素对应的灰度平均值;
34、将所述灰度变化参数与预设的灰度变化参数阈值进行比较;
35、当所述灰度变化参数低于预设的灰度变化参数阈值时,则判定所述目标区域缩放质量异常,并进行异常报警。
36、进一步的,所述数据准备,具体还包括以下步骤:
37、将预处理后的数据划分为训练集、验证集和测试集;
38、其中,80%的数据作为训练集,训练集用于训练深度学习模型,10%的数据作为验证集,验证集用于验证模型性能并调整超参数,10%的数据作为测试集,测试集用于最终测试模型性能。
39、进一步的,所述模型设计,具体还包括以下步骤:
40、确定模型架构,从2d图像中提取关键特征信息作为特征向量,将特征信息压缩成低维的向量表示,接收提取的特征向量作为输入,将输入数据编码为低维向量表示,输出编码后的低维向量;
41、接收编码器输出的低维向量作为输入,从编码中解码出3d模型数据,输出3d模型数据。
42、进一步的,所述模型训练,具体还包括以下步骤:
43、根据具体任务需求,添加损失函数,通过数据加载器加载训练数据,包括训练集中预处理后的2d图像和对应的目标3d模型,将数据分为多个批次进行训练,每个批次包含一定数量的样本;
44、基于深度学习框架初始化深度学习模型,对于每个训练批次,将2d图像输入到模型中,通过前向传播计算生成的3d模型,使用损失函数计算生成的3d模型与目标3d模型之间的差异,得到损失值;
45、根据损失值进行反向传播,计算梯度并更新模型的参数。
46、进一步的,所述模型训练,具体还包括以下步骤:
47、通过数据加载器加载验证集数据,在每个训练周期结束后,使用验证集对模型进行评估,将验证集数据输入到模型中,计算生成的3d模型与目标3d模型之间的差异,得到验证损失,监控验证损失的变化情况;
48、设定保存模型的触发条件,所述触发条件包括验证损失连续特定个数周期下降以及达到预设的验证准确率,当满足保存条件时,将当前模型的参数保存到磁盘上;
49、记录训练过程中的训练信息,所述训练信息包括损失值、准确率、学习率,使用可视化工具对训练过程进行可视化,基于训练信息生成数据曲线。
50、进一步的,所述模型评估,具体还包括以下步骤:
51、加载已训练好的深度学习模型,将预处理后的测试集2d图像输入到模型中,模型通过卷积神经网络提取特征,利用自编码器将特征编码为低维向量,并解码为3d模型数据;
52、计算生成的3d模型与真实3d模型之间的误差,分析重建误差的分布情况,得到评估结果,基于评估结果对模型的架构、参数以及损失函数进行调整;
53、重复进行模型评估、分析和调整的过程,直到模型性能达到期望的水平。
54、进一步的,所述应用优化,具体还包括以下步骤:
55、将训练好的3d虚拟形象模型集成到相应的应用平台以及软件中,为用户提供清晰的使用指南或教程,设置反馈机制,所述反馈机制包括评分系统、调查问卷、在线聊天,在用户使用过程中,实时收集用户对模型性能和应用体验的评价;
56、根据用户反馈和数据分析结果,对模型的性能以及功能进行改进和拓展,将优化和改进后的模型重新部署到应用平台中,并在应用更新后持续监控用户的使用情况和反馈。
57、与现有技术相比,本发明的有益效果是:
58、1.本发明通过卷积神经网络或其他深度学习架构,模型能够高效地从2d图像中提取关键特征信息,这些特征信息对于重建高质量的3d模型至关重要,将提取的特征信息压缩成低维的向量表示,可以大大降低数据的维度,同时保留关键信息,不仅减少了计算成本,还有助于模型学习更高效的表示。使用自编码器或其变种作为模型的一部分,使得模型能够从低维向量中解码出3d模型数据,在训练过程中能够学习到从2d到3d的映射关系,并且可以通过调整编码器和解码器的参数来优化生成的3d模型的质量。
59、2.本发明通过将数据分为多个批次进行训练,模型能够更有效地利用计算资源,并加速训练过程,批量训练还有助于减少梯度计算中的噪声,提高模型训练的稳定性。添加与具体任务需求相匹配的损失函数,能够准确衡量生成的3d模型与目标3d模型之间的差异,从而指导模型进行精确的参数优化,在每个训练周期结束后使用验证集对模型进行评估,能够及时发现模型训练过程中的问题。
60、3.本发明通过计算生成的3d模型与真实3d模型之间的误差,能够精准地评估模型的性能,有助于研究人员明确模型在3d重建任务上的表现,并作为模型优化和改进的依据,分析重建误差的分布情况,可以帮助研究人员了解模型在不同类型或难度数据上的表现,有助于识别模型可能存在的弱点和问题,并针对性地进行改进,基于评估结果对模型的架构、参数以及损失函数进行调整,可以针对性地优化模型的性能,模型能够逐渐逼近最优解,提升在3d虚拟形象重建任务上的表现。
本文地址:https://www.jishuxx.com/zhuanli/20241120/333829.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表