基于专家状态的生成对抗网络强化学习的暖通空调控制方法
- 国知局
- 2024-11-21 12:07:06
本发明涉及强化学习的暖通空调控制方法领域,尤其涉及基于专家状态的生成对抗网络强化学习的暖通空调控制方法。
背景技术:
1、在全球范围内,建筑能耗占全球总能耗的40%以上,其中冬季供暖、夏季制冷和通风所消耗的能源在建筑能耗中占有较大比例。因此,实施有效的暖通空调控制可以显著提高能源利用效率和室内舒适度。另一方面,随着能源转型的推进,能源相关的需求响应控制操作应具备应对随机环境影响、波动的能源价格、潜在的电力短缺以及可再生能源间歇性的能力。
2、近年来,因为强化学习可以同时考虑室内温度的舒适度,能源价格的波动等因素,强化学习在建筑能源领域得到了广泛的应用,尤其在暖通空调系统中。强化学习的核心是马尔可夫决策过程,旨在最大化从环境中获得的累计奖励。通常,奖励函数需要由了解该环境的专家在强化学习任务前精心设计,并且在设计时需要充分理解任务的目标。然而,在实际的应用场景中,尤其是在建筑方向上,由于需要考虑的环境因素过多例如墙壁的厚度,室内室外的温度,实时电价等,手动设计一个合理的奖励函数十分的困难。
3、综上,强化学习在暖通空调的控制方面具有应用场景,但是强化学习奖励函数设计以及强化学习算法上的选择限制了强化学习在应用中的表现。
技术实现思路
1、本发明的目的是使用规划方法生成专家状态,通过专家状态指导生成对抗强化学习算法以解决复杂的暖通空调系统控制问题。
2、基于专家状态的生成对抗网络强化学习的暖通空调控制方法的步骤包括:
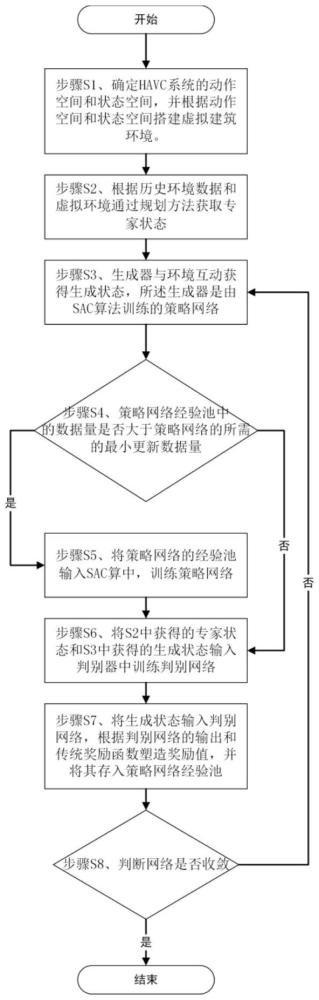
3、步骤s1、确定havc系统的动作空间和状态空间,并根据动作空间和状态空间搭建虚拟建筑环境,该虚拟建筑环境可以通过输入的动作计算出下一时刻的状态值。
4、步骤s2、根据历史环境数据和虚拟环境通过规划方法获取的状态-下一时刻状态对作为专家状态。
5、步骤s3、生成器与虚拟建筑环境互动获得状态-下一时刻状态对作为生成状态,所述生成器是由sac算法训练的策略网络。
6、步骤s4、判断策略网络经验池bsac的数据量是否大于策略网络π最小更新时经验池中经验数量的最小值,若是则跳转至步骤s5,若不是则跳转至步骤s6。
7、步骤s5、将经验池bsac输入sac算法中,训练策略网络π。
8、步骤s6、将s2中获得的专家状态和s3中获得的生成状态输入判别器中训练判别网络,判别器训练时引入了wasserstein来判别专家状态分布和生成状态分布之间的距离。
9、步骤s7、将生成状态输入判别网络,根据判别网络的输出和传统奖励函数塑造奖励值,并将其存入策略网络经验池bsac。
10、步骤s8、重复步骤s3-s7,直至结果收敛后输出策略网络
11、作为优选,所述步骤s1中使用energyplus来搭建建筑物模型和暖通空调系统(havc)的虚拟环境并用openai gym框架训练来与强化学习进行交互,假设虚拟环境中的建筑物分为东西两个区域每个区域都配备了独立的暖通空调系统。该虚拟环境可以根据该时刻所给出的at得到下一时刻的环境状态值st+1,st+1为一个包含多状态值的数组,其公式可以表示为:
12、st+1=fenv(at)
13、作为优选,所述步骤s2中采用历史的数据和环境模型通过规划方法得到良好的专家状态,其规划目标函数如下:
14、
15、式中,ct为t时刻的电价;a1(t),a2(t),a3(t),a4(t)分别为西区的设定温度、东部区域的设定温度、西区送风机空气质量流量和东区送风机空气质量流量在该时刻的动作值;为经过调控后下一时刻havc的耗电功率;ppv为光伏功率;α为温度惩罚系数;tsuit为合理的室内温度;和分别为经过调控后西区和东区的室内温度。
16、作为优选,所述步骤s3策略网络π根据状态值st挑选动作值at并将动作值输入环境得到下一时刻状态值st+1其公式可以表示为:
17、at=fπ(st)
18、获得动作值后,将其状态值和动作值以(st,at,st+1)的形式存入生成经验池bπ中。
19、作为优选,所述步骤s5中生成器目标是找到一个策略π,使得有策略网络π生成联合分布ρπ(s,s')接近专家状态的联合分布ρe(s,s'),基于状态的生成对抗网络的强化学习优化的目标函数为:
20、
21、式中,生成状态和专家状态之间的分布差异,在本专利中使用l1-wassertain来测量专家状态和生成状态之间的差距。在本专利中策略的更新采用sac算法。
22、作为优选,所述步骤s6中将s2中获得的专家策略和s3中获得的生成经验池bπ输入判别网络中用以训练判别网络。在算法中我们使用wasserstein距离来计算专家状态分布和生成状态分布的距离,其距离可以用判别网络d定义为:
23、
24、式中,(s,s')e和(s,s')π分别为从专家状态生成状态。为了满足wasserstein距离的lipschitz约束条件,因此需要向判别网络中添加梯度约束,其式子可以表示为:
25、
26、式中,为专家状态分布和生成状态分布的线性插值的概率分布;是从分布中采样的随机插值。算法中判别网络的目标函数如下:
27、
28、式中,ω为判别网络d的网络参数;λgp为惩罚系数。
29、作为优选,所述步骤s7中通过步骤s6训练完成的判别网络和传统奖励函数塑造奖励值rt,并将其以(st,at,rt,st+1)的形式存入策略网络经验池bsac。因此奖励函数的塑造分为两部分,一部分为判别网络的输出值经过一个映射函数得到;一部分为传统的奖励函数。本专利中映射函数的表达形式如下:
30、
31、式中,x为判别器d的输出值。
32、传统的奖励函数通过人为经验设定奖励函数,该环境的目标是为了最大限度的减少能源的消耗,同时将室内温度保持在预定范围内,因此专利中奖励函数将其设为:
33、
34、式中,表示区域i的在该时刻温度奖励值;λt为功率惩罚系数;et为该时刻电价;phavc为暖通空调的功率;ppv为光伏功率。将奖励函数的两部分相结合得到奖励函数如下:
35、
36、式中,η1和η2为两个奖励系数。将步骤s3中获得的生成经验池bπ输入奖励函数得到奖励值,并将其以(st,at,rt,st+1)的形式更新策略网络经验池bsac。
37、作为优选,策略网络经验池bsac为一个固定容量的经验池,当存入经验池的容量超过了最大容量,则旧的数据将被删除。
38、本发明的有益效果:
39、将规划算法和强化学习相结合,通过规划方法求解专家状态,再通过专家状态训练强化学习;为了学习专家状态,设计了一种基于专家状态的生成对抗网络强化学习算法,该算法中引入了wasserstein距离使得训练更加的稳定;为了提高训练的效果,算法中重塑了奖励函数将判别网络的输出值通过映射函数和传统奖励函数相结合;为了提高策略网络在连续动作空间上训练的稳定性和探索性,在策略网络的训练上使用了sac算法。
40、通过规划算法所得的专家经验更多的从时间维度去考略控制和合理性,通过规划算法所得的专家状态能从时序的角度上确保每个时间步都能采取合适的行动,因此通过专家状态和本专利所述算法训练的策略网络能有效的降低建筑能源成本,同时能将室内温度维持在合理的区间内。
本文地址:https://www.jishuxx.com/zhuanli/20241120/334412.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表