地球科学大语言模型的训练方法、装置以及电子设备
- 国知局
- 2024-12-06 12:08:03
本发明涉及人工智能,尤其涉及一种地球科学大语言模型的训练方法、装置以及电子设备。
背景技术:
1、在人工智能领域,尤其是自然语言处理应用中,大语言模型已经成为推动技术发展的重要力量。大语言模型依赖于大量的参数和复杂的算法,能够通过学习海量的文本数据,掌握自然语言的深层结构和语义规律。然而,尽管现有的大语言模型在通用性和多功能性方面表现优异,它们在特定领域(如地球科学等垂直行业)的应用效果仍然受限。
2、传统的大语言模型训练方法主要包括两个阶段:预训练和指令精调。在预训练阶段,模型通过在大规模、多领域的无标签文本数据来学习语言的基础规则和结构;在指令精调阶段,模型则通过较少量的多样化的标注数据进行调整,以提升在特定任务上的性能。现有的训练方式,导致大语言模型在处理地球科学专业领域的文本时,不能充分理解和生成地球科学领域的专业内容,从而限制了其在地球科学领域的实际应用价值。
3、此外,相关技术中,还采用地球科学文本数据继续预训练和微调通用大语言模型,虽然这可以在一定程度上提高模型的地球科学性能,但是这些方法对模型地球科学性能的提升效率较低,且会导致大语言模型的通用性能下降。
4、因此,如何训练得到具有良好的通用性能,且在地球科学领域具有良好表现的地球科学大语言模型,是亟待解决的技术问题。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种地球科学大语言模型的训练方法、装置以及电子设备,用以训练得到具有良好的通用性能,且在地球科学领域具有良好表现的地球科学大语言模型。
2、本发明提供一种地球科学大语言模型的训练方法,包括如下步骤。
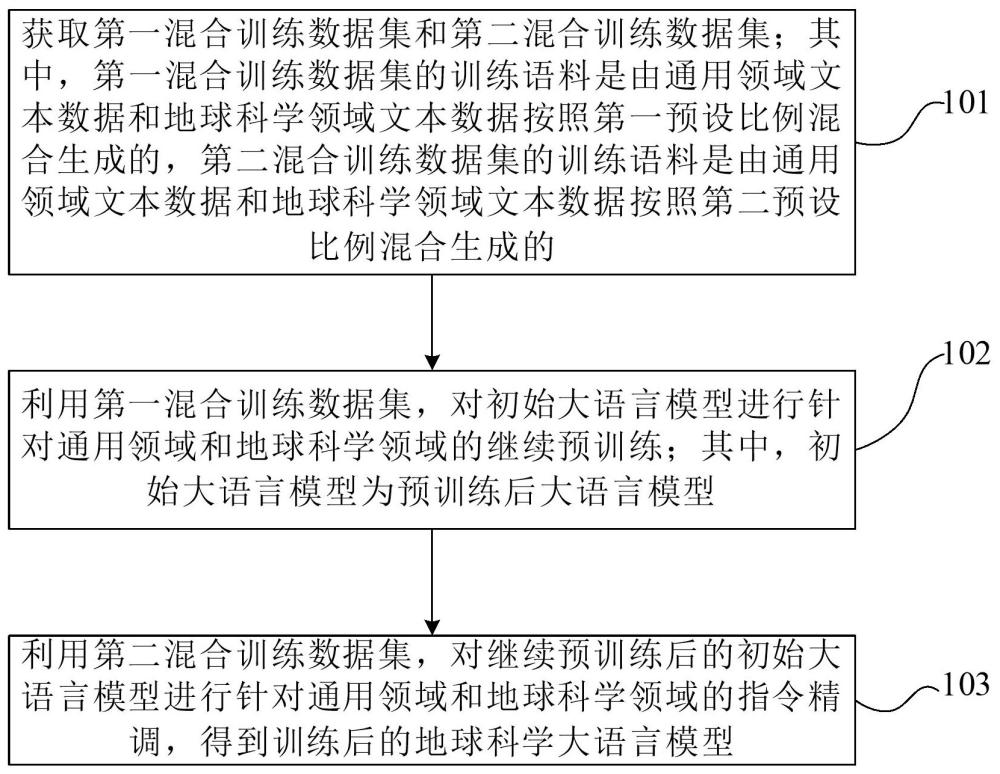
3、获取第一混合训练数据集和第二混合训练数据集;其中,所述第一混合训练数据集的训练语料是由通用领域文本数据和地球科学领域文本数据按照第一预设比例混合生成的,所述第二混合训练数据集的训练语料是由通用领域文本数据和地球科学领域文本数据按照第二预设比例混合生成的;利用所述第一混合训练数据集,对初始大语言模型进行针对通用领域和地球科学领域的继续预训练;其中,所述初始大语言模型为预训练后大语言模型;利用所述第二混合训练数据集,对继续预训练后的所述初始大语言模型进行针对通用领域和地球科学领域的指令精调,得到训练后的地球科学大语言模型,以利用所述地球科学大语言模型生成针对地球科学领域问题的答案。
4、根据本发明提供的一种地球科学大语言模型的训练方法,所述方法还包括:获取第一通用领域训练数据集;其中,所述第一通用领域训练数据集中的训练语料是由通用领域文本数据生成的;在利用所述第一混合训练数据集,对初始大语言模型进行针对通用领域和地球科学领域的继续预训练之前,所述方法还包括:利用所述第一通用领域训练数据集,对所述初始大语言模型进行针对通用领域的继续预训练。
5、根据本发明提供的一种地球科学大语言模型的训练方法,所述方法还包括:获取第二通用领域训练数据集;其中,所述第二通用领域训练数据集中的训练语料是由通用领域文本数据生成的;在利用所述第二混合训练数据集,对继续预训练后的所述初始大语言模型进行针对通用领域和地球科学领域的指令精调之前,所述方法还包括:利用所述第二通用领域训练数据集,对所述继续预训练后的所述初始大语言模型进行针对通用领域的指令精调。
6、根据本发明提供的一种地球科学大语言模型的训练方法,所述利用所述第一混合训练数据集,对初始大语言模型进行针对通用领域和地球科学领域的继续预训练,包括:利用所述第一混合训练数据集,基于预设优化算法,对所述初始大语言模型的全部参数进行调整。
7、根据本发明提供的一种地球科学大语言模型的训练方法,所述利用所述第二混合训练数据集,对继续预训练后的所述初始大语言模型进行针对通用领域和地球科学领域的指令精调,包括:利用所述第二混合训练数据集,基于预设优化算法,对所述继续预训练后的所述初始大语言模型的全部参数进行调整。
8、根据本发明提供的一种地球科学大语言模型的训练方法,通过以下方式获取所述第一混合训练数据集:依照所述第一预设比例,获取通用领域文本数据和地球科学领域文本数据,得到第一数据集;对所述第一数据集中的文本数据进行预处理;根据预处理后的所述第一数据集中的文本数据,生成所述第一混合训练数据集中的训练语料;通过以下方式获取所述第二混合训练数据集:依照所述第二预设比例,获取通用领域文本数据和地球科学领域文本数据,得到第二数据集;对所述第二数据集中的文本数据进行预处理;对预处理后的所述第二数据集中的文本数据进行标注,得到预处理后的所述第二数据集中携带标签的文本数据;根据预处理后的所述第二数据集中携带标签的文本数据,生成所述第二混合训练数据集中的训练语料。
9、本发明还提供一种地球科学大语言模型的训练装置,包括如下模块:获取模块,用于获取第一混合训练数据集和第二混合训练数据集;其中,所述第一混合训练数据集的训练语料是由通用领域文本数据和地球科学领域文本数据按照第一预设比例混合生成的,所述第二混合训练数据集的训练语料是由通用领域文本数据和地球科学领域文本数据按照第二预设比例混合生成的;第一训练模块,用于利用所述第一混合训练数据集,对初始大语言模型进行针对通用领域和地球科学领域的继续预训练;其中,所述初始大语言模型为预训练后大语言模型;第二训练模块,用于利用所述第二混合训练数据集,对继续预训练后的所述初始大语言模型进行针对通用领域和地球科学领域的指令精调,得到训练后的地球科学大语言模型,以利用所述地球科学大语言模型生成针对地球科学领域问题的答案。
10、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述地球科学大语言模型的训练方法。
11、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述地球科学大语言模型的训练方法。
12、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述地球科学大语言模型的训练方法。
13、本发明提供的地球科学大语言模型的训练方法、装置以及电子设备,利用由通用领域文本数据和地球科学领域文本数据按照第一预设比例混合生成的第一混合训练数据集,对初始大语言模型进行针对通用领域和地球科学领域的继续预训练;利用由通用领域文本数据和地球科学领域文本数据按照第二预设比例混合生成的第二混合训练数据集,对继续预训练后的初始大语言模型进行针对通用领域和地球科学领域的指令精调,得到训练后的地球科学大语言模型。第一混合训练数据集中的地球科学领域文本数据,可以增强初始大语言模型对地球科学知识的掌握;第一混合训练数据集中的通用领域数据可以防止初始大语言模型在此阶段的训练过程中遗忘先前学习到的通用领域的知识,避免由此造成的灾难性遗忘现象和解决问题的泛化性能下降。第二混合训练数据集中的地球科学领域文本数据,可以增强继续预训练后的初始大语言模型对地球科学领域任务的理解和响应能力;第二混合训练数据集中的通用领域数据可以防止继续预训练后的初始大语言模型在此阶段的训练过程中遗忘先前学习到的通用领域任务的理解和响应能力。因此,本发明可以训练得到具有良好的通用性能,且在地球科学领域具有良好表现的地球科学大语言模型。
本文地址:https://www.jishuxx.com/zhuanli/20241204/339492.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表