一种基于多标签学习的多源素材混合剪辑视频的方法及系统与流程
- 国知局
- 2024-12-06 12:11:41
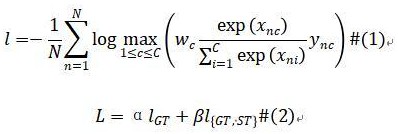
本发明涉及视频剪辑,具体为一种基于多标签学习的多源素材混合剪辑视频的方法及系统。
背景技术:
1、随着视频行业需求的增长和技术的发展,在视频智能合成领域,基于输入的文本自动合成符合文本语义的视频相关的研究一般包括训练文本-视频匹配模型、检索视频和合成视频三个阶段。首先建立文本-视频的多模态模型学习任务,然后在线搜索或从视频库检索出符合语义的视频素材,通过计算机视觉技术对素材进行分析和理解,最后精选出合适的素材进行智能合成。
2、视频智能合成的第一阶段常面临多标签学习问题,因为当视频用token(词元)的方式表示时,其真值往往不唯一,理论上存在多种方式解释同个视频,多标签学习研究的是一个样本对应一个标签集合的问题,多标签分类问题指单个样本可以同时拥有一个或多个类别标签,在多标签问题中对实例可以被分配到多少标签没有限制,难点主要有:(1)类别数量不确定,有的样本可能只有一个真值类别,有些样本的真值类别可能高达几十个;(2)真值类别之间并非独立,类别间的依赖性问题较难解决。目前根据解决问题的角度,多标签分类算法被大致可被分为基于问题转化方法和基于算法适用的方法。基于问题转化的方法或考虑标签之间的关联性,或不考虑标签的关联性。不考虑关联性的算法将多标签中的每一个标签当成是单标签,对每一个标签做二分类。考虑多标签的相关性时可将上一个输出的标签当成是下一个标签分类器的输入。基于算法适用的方法指的是改变算法来直接执行多标签分类,而不是将问题转化为不同的问题子集。在机器学习模型中常见的多标签分类模型有:knn多标签版本mlknn,svm的多标签版本rank-svm等。在深度学习中一般修改多分类模型的输出层,使其适用于多标签的分类。
3、视频智能合成领域中,视频token化一般有两种方式,其一是直接提取视频特征,其二是用图像表示视频,对图像提取特征,在特征空间采用无监督的聚类方法,将类簇索引作为token,从而完成对视频的token化。常见的聚类方式如k-means、dnscan等,在大数据集下无法同时兼顾类内距离和类簇分布。
4、视频智能合成的第二个视频检索阶段,一般会根据初始条件检索出一批候选视频,如何合理地对候选视频排序是一个关键问题。现有的方法一般基于检索相似度直接对视频排序,但事实上过短的视频片段质量较差,因此也有研究用视频时长对相似度加权,最后根据加权后的相似度对视频片段排序。当素材库视频片段长度分布的方差大时,过长且相似度一般的视频片段会始终占据靠前的排名,影响最终视频的合成效果。
5、当前业界的由长文本智能合成视频的方法中,视频智能合成相关研究中的多标签分类学习、视频token化方式和视频检索中的排序算法在影响整体的视频合成效果中各有问题:
6、现有的多标签分类学习仅在算法上进行适当转换,并未结合实际任务的特点。当单一样本的真值标签之间有一定依赖,且其真值标签存在近义标签时,无法直接用现有的算法进行解决;
7、直接用聚类算法生成的视频token分布不均,容易产生混淆,视频token类内距离不够小,导致token不足以代表其所涵盖的视频;token类间距分布不均导致token之间依赖性过高,影响多标签分类问题的学习准确率;
8、针对检索到的视频片段的排序方法,仅基于相似度的排序,易使得较相似但时长较短(小于2s)的视频片段被用于后续合成,但时长较短的视频质量不稳定,因而降低合成视频的效果,基于片段时长对相似度加权的排序方法,在素材库中视频片段之间时长偏差较大的情况下,时长较长相似度稍低的视频片段会被召回,亦会降低合成视频的效果。
技术实现思路
1、本发明的目的在于提供一种基于多标签学习的多源素材混合剪辑视频的方法及系统,具备节省了计算资源提高的优点,解决了背景技术中所提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于多标签学习的多源素材混合剪辑视频的方法及系统,包括
3、步骤一:最大化近义模糊匹配学习
4、最大化近义模糊匹配学习旨在将多标签分类问题映射为模糊匹配任务,其损失函数定义为:其中, c为token数量(词典大小), n为批量样本数; y是真值,,当第 n个样本属于第 i个token,则,否则; x为模型预测值; w为类别权重; gt(ground truth)表示真值集合, st(synonymous token)表示真值的近义token集合。
5、步骤二:分阶段视频token化
6、设素材库有 n条视频片段,表示为,是视频片段中选取的某一帧图像的特征,视频token化的目的是用token表示特征空间内在一定范围内相似的图像特征簇,相似图像簇可由聚类算法产生,本发明提出的分阶段视频token化方法,在每阶段确保图像特征簇的相似度范围,直到满足最大迭代次数 t或数据量小于等于最小样本数min_num,在最后阶段,将不满足相似度范围的token特征与候选词典的token特征逐一计算距离,根据预设的条件选择性地加入到候选token词典中。算法伪代码如下:
7、步骤三:视频片段排序策略
8、当根据每个子句在素材库的固定范围中检索视频片段时,满足初始筛选条件的视频片段会有多个,对候选视频片段排序,把排序后的top k个视频片段视作当前子句的视频片段,拼接每个子句的视频片段再整体剪辑合成最终的视频。因此,视频片段排序是一个影响视频合成效果的关键环节。设输入文案有 t个子句,根据初始条件检索到的视频片段有条,,则对输入文案各子句在固定范围的素材库中检索后的结果表示为,,为第 i个子句检索到的第 r条视频片段信息,。本发明设计的排序策略基于检索相似度和视频片段时长,的排序分值 m定义为:其中,表示为第 i个子句与其第 r条视频片段的相似度,为视频片段最小可用时长;为第 i个子句检索结果中第 r条视频片段的时长。优选的,所述步骤二中分阶段视频token化算法具体如下:输入:token内距离阈值();最少样本数min_num;视频片段;聚类算法a;最大迭代次数t
9、输出:视频token词典d;词典d中token在特征空间中的向量分布finalresult
10、初始化:未分配token的视频片段数n=n;数据集;索引index=0;
11、token内距离d=0;
12、while n>min_num or t<t:
13、cur_result = a(ds)
14、ds = []
15、next_feature = []
16、for each token_feature in cur_result:
17、if token_distance<= :
18、finalresult.append( token_feature )
19、else:
20、ds.extend( token_dataset )
21、next_feature.append( token_feature )
22、t += 1
23、n = len(ds)
24、for token_feature in next_feature:
25、if token_distance<min(distance( token_feature, finalresult )):
26、finalresult.append( token_feature )
27、return finalresult。
28、与现有技术相比,本发明的有益效果如下:
29、本发明针对多源素材混合剪辑算法的多标签分类问题(multilabelclassification),提出了一个新的学习策略,该策略将多标签分类问题映射为模糊匹配问题,提升了分类效果。
30、本发明提出了一种有效的将视频词元(token)化的方法,基于最小类内距离的原则,生成了优质的视频token词典。
31、本发明提出了一种简单有效的视频排序方法,该方法基于检索相似度和视频片段时长对每个子句检索到的视频片段排序,取排名第一的片段作为子句预选的视频片段。
32、本发明提出的学习策略,可以解决多标签分类中一对多的模糊匹配问题,不需要训练多个二分类器即可完成对多标签分类任务的训练,避免了同时训练多个二分类器所产生的损失计算冲突,并且节省了计算资源。
33、本发明提出的视频词元(token)化方法,基于最小类内距离,分阶段完成对视频的token化,生成的视频token词典可接入后续任何tokens-to-token的训练任务。
34、本发明提出的视频片段排序方法,有效地结合视频文本的相似度和片段时长两个因素,在满足相似度的同时确保了视频片段质量,该排序方法大大提升了视频合成的效果。
本文地址:https://www.jishuxx.com/zhuanli/20241204/339873.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表