声音处理方法、可穿戴设备和可读存储介质与流程
- 国知局
- 2025-01-10 13:25:45
本申请涉及语音处理,尤其涉及一种声音处理方法、可穿戴设备和计算机可读存储介质。
背景技术:
1、目前,现有的智能可穿戴设备(例如,智能眼镜)大多数缺乏有效的声音增强功能,而传统的可穿戴设备(例如,蓝牙耳机)受限于空间和硬件处理能力而无法实现高级的音频分离、增强算法,导致可穿戴设备在嘈杂环境、会议、多人交谈等场景中无法实现声音增强,降低了用户的听觉体验。
技术实现思路
1、本申请提供了一种声音处理方法、可穿戴设备和计算机可读存储介质,可以解决现有的可穿戴设备无法实现声音增强的问题。
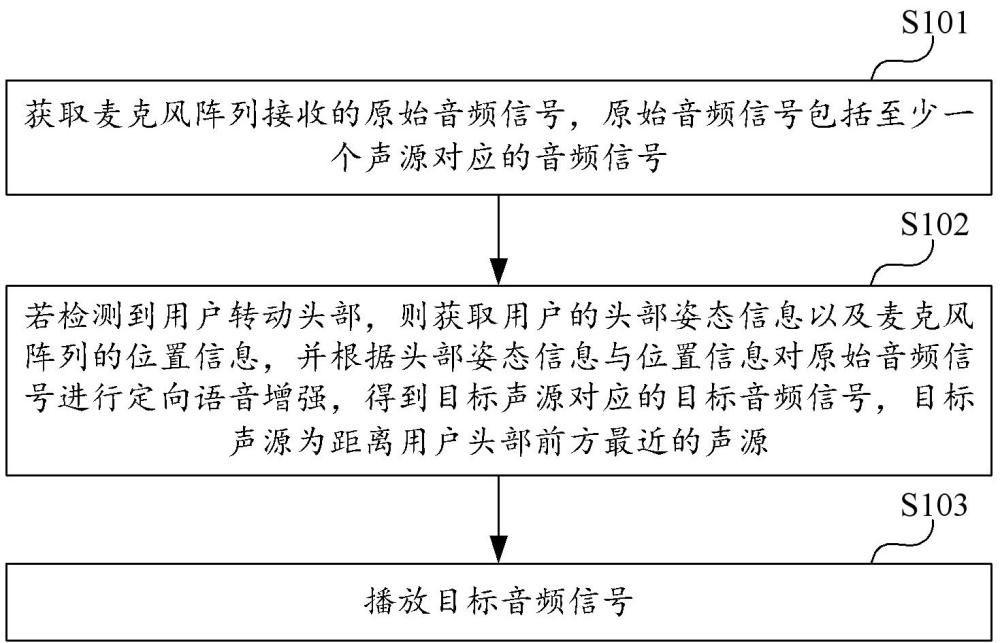
2、第一方面,本申请还提供了一种声音处理方法,所述声音处理方法包括:获取所述麦克风阵列接收的原始音频信号,所述原始音频信号包括至少一个声源对应的音频信号;若检测到用户转动头部,则获取所述用户的头部姿态信息以及所述麦克风阵列的位置信息,并根据所述头部姿态信息与所述位置信息对所述原始音频信号进行定向语音增强,得到目标声源对应的目标音频信号,所述目标声源为距离所述用户头部前方最近的声源;播放所述目标音频信号。
3、第二方面,本申请提供了一种声音处理方法,应用于可穿戴设备,所述可穿戴设备包括麦克风阵列;所述方法包括:
4、获取用户的头部姿态信息、所述麦克风阵列接收的原始音频信号以及所述麦克风阵列的位置信息;
5、根据所述原始音频信号、所述头部姿态信息以及所述位置信息进行声源定位,获得至少一个声源对应的声源位置估计值;
6、根据所述原始音频信号、所述头部姿态信息、所述位置信息以及每个所述声源对应的所述声源位置估计值进行波束合成,得到波束合成信号;
7、对所述原始音频信号进行盲源分离,得到每个所述声源对应的独立音频信号;
8、根据所述波束合成信号、每个所述声源对应的所述独立音频信号进行声音增强,得到目标音频信号。
9、第三方面,本申请还提供了一种可穿戴设备,所述可穿戴设备包括存储器、处理器、麦克风阵列和惯性测量单元;
10、所述存储器,用于存储计算机程序;
11、所述麦克风阵列,用于接收音频信号;
12、所述惯性测量单元,用于采集用户的头部姿态信息;
13、所述处理器,用于执行所述计算机程序并在执行所述计算机程序时实现如上述的声音处理方法。
14、第四方面,本申请还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如上述的声音处理方法。
15、本申请公开了一种声音处理方法、可穿戴设备和计算机可读存储介质,通过在检测到用户转动头部时,获取用户的头部姿态信息以及麦克风阵列的位置信息,并根据头部姿态信息与位置信息对原始音频信号进行定向语音增强,可以实现基于用户头部转动行为进行定向语音增强并抑制其他音源以及环境噪音,可以适用于各种应用场景,能够有效地过滤掉噪声,提高了用户的听觉体验,同时能够起到听力辅助作用,帮助听力有缺陷的用户提高听力。
技术特征:1.一种声音处理方法,其特征在于,应用于可穿戴设备,所述可穿戴设备包括麦克风阵列;所述方法包括:
2.根据权利要求1所述的声音处理方法,其特征在于,所述原始音频信号包括至少一个麦克风通道接收到的至少一个声源对应的音频信号;所述根据所述头部姿态信息与所述位置信息对所述原始音频信号进行定向语音增强,得到目标声源对应的目标音频信号之前,所述方法还包括:
3.根据权利要求2所述的声音处理方法,其特征在于,所述根据所述头部姿态信息与所述位置信息对所述原始音频信号进行定向语音增强,得到目标声源对应的目标音频信号,包括:
4.根据权利要求3所述的声音处理方法,其特征在于,所述根据所述多通道时频信号、所述头部姿态信息以及所述位置信息进行声源定位,获得至少一个声源对应的声源位置估计值,包括:
5.根据权利要求4所述的声音处理方法,其特征在于,所述根据所述多通道时频信号,确定所述多通道时频信号的到达时间差对应的时延估计值,包括:
6.根据权利要求4所述的声音处理方法,其特征在于,所述位置信息包括麦克风阵列的第一位置;所述基于卡尔曼滤波器,根据所述时延估计值、所述头部姿态信息以及所述位置信息进行声源定位,获得每个所述声源对应的所述声源位置估计值,包括:
7.根据权利要求6所述的声音处理方法,其特征在于,所述对每个所述声源对应的状态估计值进行坐标系转换,得到每个所述声源对应的所述声源位置估计值,包括:
8.根据权利要求3所述的声音处理方法,其特征在于,所述根据所述头部姿态信息、所述位置信息以及每个所述声源对应的所述声源位置估计值对所述多通道时频信号进行波束合成,得到波束合成信号,包括:
9.根据权利要求8所述的声音处理方法,其特征在于,所述声源位置估计值包括每个声源对应的第二位置估计值;所述根据所述头部姿态信息与所述声源位置估计值进行声源方向计算,得到目标声源方向,包括:
10.根据权利要求8所述的声音处理方法,其特征在于,所述根据所述目标声源方向、所述位置信息以及所述协方差矩阵估计结果对所述多通道时频信号进行波束计算,得到所述波束合成信号,包括:
11.根据权利要求3所述的声音处理方法,其特征在于,所述对所述多通道时频信号进行协方差矩阵估计,得到所述多通道时频信号对应的协方差矩阵估计结果之后,所述方法还包括:
12.根据权利要求11所述的声音处理方法,其特征在于,所述对所述多通道时频信号进行盲源分离,得到每个所述声源对应的独立音频信号,包括:
13.根据权利要求12所述的声音处理方法,其特征在于,所述基于所述声源数量估计值,根据每个所述声源对应的第一掩蔽估计值对所述多通道时频信号进行信号分离,得到每个所述声源对应的独立音频信号,包括:
14.根据权利要求4所述的声音处理方法,其特征在于,所述根据所述波束合成信号、每个所述声源对应的所述独立音频信号进行声音增强,得到目标音频信号,包括:
15.根据权利要求14所述的声音处理方法,其特征在于,所述根据所述波束合成信号、每个所述声源的时频信号进行增益计算,得到每个所述声源在每个所述麦克风通道上的软掩蔽值,包括:
16.根据权利要求14所述的声音处理方法,其特征在于,所述对每个所述声源在每个所述麦克风通道上的软掩蔽值进行信号合成,得到单通道频域总信号,包括:
17.根据权利要求1所述的声音处理方法,其特征在于,所述播放所述目标音频信号,包括:
18.根据权利要求17所述的声音处理方法,其特征在于,所述目标音频信号包括至少一个声源的音频信号;所述根据所述头部姿态信息与每个所述声源对应的所述声源位置估计值,将所述目标音频信号分配至所述可穿戴设备的左声道和右声道,包括:
19.一种声音处理方法,其特征在于,应用于可穿戴设备,所述可穿戴设备包括麦克风阵列;所述方法包括:
20.一种可穿戴设备,其特征在于,所述可穿戴设备包括存储器、处理器、麦克风阵列和惯性测量单元;
21.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至18任一项所述的声音处理方法或如权利要求19所述的声音处理方法。
技术总结本申请公开了一种声音处理方法、可穿戴设备和可读存储介质,该声音处理方法包括:获取所述麦克风阵列接收的原始音频信号,所述原始音频信号包括至少一个声源对应的音频信号;若检测到用户转动头部,则获取所述用户的头部姿态信息以及所述麦克风阵列的位置信息,并根据所述头部姿态信息与所述位置信息对所述原始音频信号进行定向语音增强,得到目标声源对应的目标音频信号,所述目标声源为距离所述用户头部前方最近的声源;播放所述目标音频信号。上述声音处理方法,可以实现根据用户的头部转向进行定向语音增强,并抑制其他音源以及环境噪音,提高了用户的听觉体验。技术研发人员:周万程,陈攀,张波受保护的技术使用者:闪极科技(深圳)有限公司技术研发日:技术公布日:2025/1/6本文地址:https://www.jishuxx.com/zhuanli/20250110/353075.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。