一种高表现力歌唱声音合成模型训练方法、合成方法及装置与流程
- 国知局
- 2024-12-06 12:27:40
本发明涉及人工智能,尤其涉及一种高表现力歌唱声音合成模型训练方法、合成方法及装置。
背景技术:
1、歌声既是一种人们借以传达信息的媒介,也是一种传达创作者、歌唱者思绪的艺术形式。随着人工智能及计算机技术的不断发展,高表现力的歌声合成技术是人工智能必不可少的一个研究课题,同时也是现在计算机音乐的热门研究领域之一。
2、现阶段的歌声合成系统可以通过输入歌词和乐谱中的音高和持续时间,来合成自然的歌声。但是,在高表现力歌声合成任务中,需要对歌声进行四个方面的控制来实现高表现力的歌声生成:旋律,强度,节奏和音色。目前的高表现力歌声合成系统缺乏对歌声强度的建模与控制,若用户想细粒度的操作歌声的上述属性,较为困难。
3、现有的歌声合成技术方案包括声学模型和声码器两部分组成,其中声学模型由文本编码器,乐谱编码器,编码器,变量适配器,长度约束器和梅尔编码器构成。文本编码器和乐谱编码器读取歌词,对音高和持续时间进行初步建模,编码器对建模得到的音高和持续时间进一步编码。变量适配器从四个方面对合成歌声进行控制:音色,感情,音高,能量,每个属性所对应的模块通过残差进行连接。随后,经过长度约束器后,由梅尔谱编码器预测梅尔谱。声码器读取梅尔谱,合成最终的歌唱音频。
4、但现有技术方案中,情感标签需要人工标注,成本十分高昂,人工标注的情感标签存在个人差异,不能客观地反映歌手的情感。并且现有技术方案的情感标签仅针对句子级别进行标注,操作粒度较粗,不能做到字级别细粒度的标注与控制,缺乏对细节的把控,同时也造成训练过程中情感标签和目标感情的不匹配的情况。进一步的,现有技术方案使用情感标签、歌词和乐谱指导歌声合成,但是,歌声情感属性的改变会引发歌唱声音中多个属性的改变,从而会导致高表现力歌声合成多个属性相耦合,缺乏对其中单独属性的控制能力,合成效果欠佳。
技术实现思路
1、鉴于此,本发明实施例提供了一种高表现力歌唱声音合成模型训练方法、合成方法及装置,以消除或改善现有技术中存在的一个或更多个缺陷,解决现有歌声合成技术方案需人工标注情感标签,粒度粗、成本高且不能客观反应情感偏向,缺乏对歌声强度强度的建模与控制,以及歌声情感属性的改变会导致高表现力歌声合成多个属性相耦合,缺乏对单独属性的控制能力,合成效果差的问题。
2、一方面,本发明提供了一种高表现力歌唱声音合成模型训练方法,所述方法包括以下步骤:
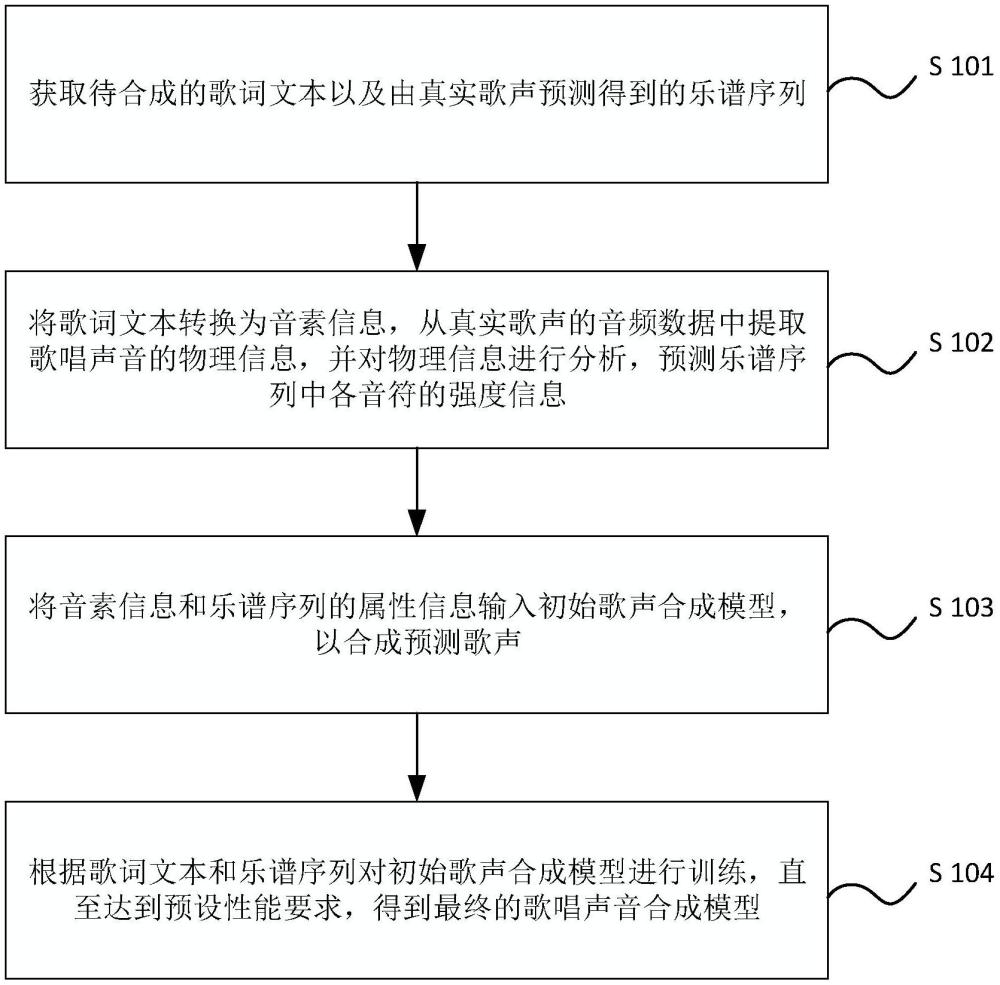
3、获取待合成的歌词文本,以及由真实歌声预测得到的乐谱序列;
4、将所述歌词文本转换为音素信息,从所述真实歌声的音频数据中提取歌唱声音的物理信息,并对所述物理信息进行分析,预测所述乐谱序列中各音符的强度信息,包括:计算所述歌词文本中每个字真实演唱时的持续时长,根据所述持续时长计算每个字的基频,根据每个字的基频计算其谐波能量,将所述谐波能量除以持续时长,得到时间平均谐波能量,将每个字的时间平均谐波能量预处理后映射至预设范围,生成相应的强度信息;
5、将所述音素信息和所述乐谱序列的属性信息输入初始歌声合成模型中,以合成最终的预测歌声;其中,所述初始歌声合成模型包括文本编码器、时长预测期、长度约束器、基频解码器、梅尔解码器、transformer、连续语音单元表征模块、信号处理模块和声码器;将所述音素信息和所述属性信息输入所述文本编码器,生成文本嵌入序列;将所述文本嵌入序列输入所述时长预测器,确定每个字的持续时长;将所述文本嵌入序列和每个字的持续时长输入所述长度约束器,生成语音表征;将所述语音表征分别输入所述基频解码器和所述梅尔解码器,生成基频和梅尔谱;将所述基频、所述梅尔谱和所述语音表征相加,得到混合嵌入向量;将所述混合嵌入向量依次输入所述transformer和所述连续语音单元表征模块,生成连续语音单元向量;将所述连续语音单元向量、所述基频和所述谐波能量输入信号处理模块,生成初级语音表示;将所述连续语音单元向量输入所述声码器,以所述初级语音表示为所述声码器的先验条件,合成最终的预测歌声;所述乐谱序列的属性信息至少包括音高信息和持续时长信息;
6、根据所述歌词文本和所述乐谱序列对所述初始歌声合成模型进行训练,直至达到预设性能要求,得到最终的歌唱声音合成模型。
7、在本发明的一些实施例中,获取待合成的歌词文本,以及由真实歌声预测得到的乐谱序列,所述乐谱序列采用乐器数字接口格式。
8、在本发明的一些实施例中,根据每个字的基频计算其谐波能量,包括:
9、根据每个字的基频计算预设数量维度的谐波能量,并将所有维度的谐波能量相加得到每个字的谐波能量总和。
10、在本发明的一些实施例中,将每个字的时间平均谐波能量预处理后映射至预设范围,包括:
11、对每个字的时间平均谐波能量进行minmax归一化处理;将处理后的结果映射至预设范围,以得到所述乐谱序列中每个音符对应的强度。
12、在本发明的一些实施例中,将所述混合嵌入向量依次输入所述transformer和所述连续语音单元表征模块,生成连续语音单元向量之后,还包括:
13、将所述真实歌声的音频数据输入预设的hubert模型,生成离散语音单元向量;
14、将所述连续语音单元向量进行线性投影,将其与所述离散语音单元向量进行交叉熵损失计算,以优化语音表征质量。
15、在本发明的一些实施例中,将所述连续语音单元向量、所述基频和所述谐波能量输入信号处理模块,生成初级语音表示,包括:
16、根据所述基频和所述谐波能量合成目标歌声的周期性部分,根据所述连续语音单元向量合成所述目标歌声的非周期性部分;
17、将所述目标歌声的周期性部分和非周期性部分相加,得到所述目标歌声的初级语音表示。
18、另一方面,本发明还提供一种高表现力歌唱声音合成方法,所述方法包括以下步骤:
19、获取待合成的歌词文本,以及真实演奏的乐谱序列;
20、从所述乐谱序列中提取强度信息、音高信息和持续时长信息;
21、将所述强度信息、所述音高信息和所述持续时长信息输入如上文中提及的任意一项所述高表现力歌唱声音合成模型训练方法训练得到的歌唱声音合成模型中,以合成预测歌声;所述乐谱序列的属性信息至少包括音高信息和持续时长信息。
22、另一方面,本发明还提供一种高表现力歌唱声音合成装置,所述装置被执行时实现如上文中提及的任意一项所述高表现力歌唱声音合成方法的步骤,所述装置包括:
23、歌声获取模块,用于获取待合成的歌词文本,以及真实演奏的乐谱序列;从所述乐谱序列中提取强度信息、音高信息和持续时长信息;;
24、歌唱声音合成模块,包括文本编码器、时长预测期、长度约束器、基频解码器、梅尔解码器、transformer、连续语音单元表征模块、信号处理模块和声码器,用于根据所述强度信息、所述音高信息和所述持续时长信息自动合成预测歌声。
25、另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上文中提及的任意一项所述方法的步骤。
26、另一方面,本发明还提供一种计算机程序产品,包括计算机程序/指令,该计算机程序/指令被处理器执行时实现如上文中提及的任意一项所述方法的步骤。
27、本发明的有益效果至少是:
28、本发明提供一种高表现力歌唱声音合成模型训练方法、合成方法及装置,包括:获取待合成的歌词文本,以及由真实歌声预测得到的乐谱序列;将歌词文本转换为音素信息,从真实歌声的音频数据中提取歌声的物理信息并分析,得到乐谱序列中各音符的强度信息;将音素信息和乐谱序列的属性信息输入文本编码器生成文本嵌入序列,经由时长预测器确定每个字的持续时长,将文本嵌入序列和持续时长输入长度约束器生成语音表征;将语音表征输入基频解码器和梅尔解码器生成基频和梅尔谱;将基频、梅尔谱和语音表征相加得到混合嵌入向量,将混合嵌入向量输入transformer和连续语音单元表征模块生成连续语音单元向量,由声码器合成最终的预测歌声。本发明提供的方法能够对现有歌声合成数据集进行全自动强度信息标注,无需增加人工成本。同时,分别对音高、持续时长、强度等各属性进行精确细粒度建模,避免各属性之间的耦合,合成高质量的高表现力歌声。
29、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
30、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341499.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表