一种基于深度学习的语音转录方法与流程
- 国知局
- 2025-01-10 13:28:35
本发明属于语音识别领域,涉及一种基于深度学习的语音转录方法。
背景技术:
1、执法机关或检察机关处理案件的过程中,通常使用执法记录仪或者监控器对执法过程进行记录,同时会有执法人员对该过程中的对话进行记录,最终形成笔录并存档。这些执法过程中的视频以及笔录的执法信息数据对日后进一步的使用有着重要的作用,其中包含的案件事实对案情起着佐证作用,提高办案人员的办案效率。此外,两类信息也相互补充,避免执法信息数据的遗漏。
2、为了使笔录中的信息更加规范,通常需要记录人员在记录的同时,也需要对对话的内容进行整理,对记录人员的要求较高,需要有长时间的该类工作经验才能够胜任。除此之外,对执法过程进行记录会影响整体的执法信息数据存储的进度,所以需要对该过程的生成、存储速度进行优化。
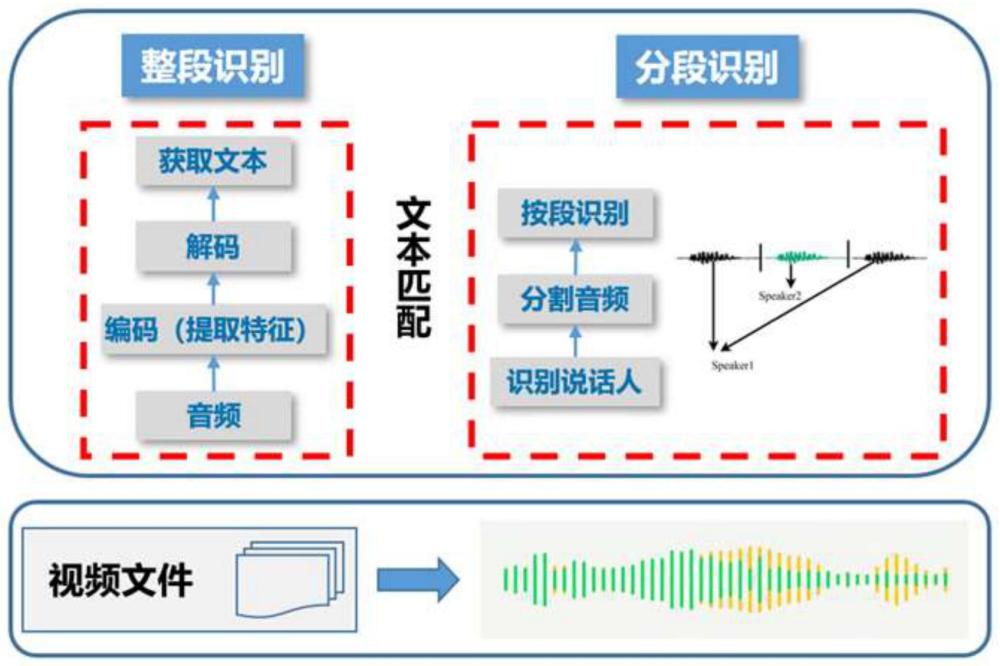
3、整体的语音识别不能具有文本分区以及说话人的区分,导致转录文本不具有可读性,通常本领域采用分段文本转录,如申请公布号us20230154468a1的美国专利申请文件中公开了一种用于长格式音频的语音识别装置,并具体公开了将音频流分段成多个音频段;识别所述多个音频片段中的每一个音频片段内的多个说话者;对所述多个音频片段中的每一个执行自动语音识别(asr),以产生多个短片段假设;将所述短节假设的至少一部分合并到第一合并假设集合中;将缝合符号插入到所述第一合并假设集合中,所述缝合符号包括窗口改变(wc)符号;以及用基于网络的假设拼接器将所述第一合并假设集合合并为第一合并假设。其采用分段成多个音频段识别形成转录文本,而该种方式存在的缺陷是分段识别相较于整体识别,对时间较短的音频无法获取准确或者获取到对应的音频文本。
技术实现思路
1、为了解决现有分段语音文本识别中较短时间音频文本处理不准确,导致转录文本不完整的问题,在本发明的一种实施例中的基于深度学习的语音转录方法,包括
2、s10.提取视频文件中的音频文件;
3、s20.识别所述音频文件中的音频对应的第一文本,所述第一文本是所述音频文件中的音频的对应文本的集合,所述第一文本包括音频时间标记;
4、s30.通过声纹识别对所述音频文件中的音频中的不同声音特征分类;
5、s40.根据所述特征分类确定不同说话对象以及不同说话对象的音频区间;
6、s50.识别音频区间的音频对应的第二文本,所述第二文本是各所述音频区间的音频对应文本的集合,且所述第二文本包括各音频区间对应的文本区间的文本区间标记以及文本区间对应的说话对象标记,所述第二文本还包括音频时间标记;
7、s60.根据所述音频时间标记,将所述第二文本与所述第一文本匹配,对所述第二文本中各音频区间的音频对应的文本对应在所述第一文本的相应的文本位置,根据第二文本的所述文本区间标记对所述第一文本的对应文本的区间标记说话对象,所述标记文本区间的说话对象的第一文本是所述语音转录所得文件,其中,所述音频区间、文本区间是所述音频时间的时间区间的对应表示。
8、在本发明的一种实施例中的基于深度学习的语音转录方法,在所述步骤s50中,音频区间未识别有效文本内容,识别得到音频区间的声音特征以及特征分类,使第二文本中这类文本的文本区间无对应文本内容,但文本区间对应说话对象标记,这类文本是第二文本中的特别文本;
9、在所述步骤s60中,根据所述音频时间标记,将所述第二文本与所述第一文本匹配,其中,对所述第二文本中的特别文本根据音频时间标记对应在所述第一文本的相应的文本位置,根据第二文本中的特别文本的所述文本区间标记对所述第一文本的对应文本的区间标记说话对象。
10、在本发明的一种实施例中的基于深度学习的语音转录方法,所述步骤s10中提取视频文件中的音频文件的方法,包括:对于执法记录仪或者监控器中的视频文件,使用自动化剪辑工具将视频中的音频抽取出来,并固定格式,抽取出的音频格式固定为16khz,16位的单声道音频。
11、在本发明的一种实施例中的基于深度学习的语音转录方法,所述步骤s30中通过声纹识别对所述音频文件中的音频中的不同声音特征分类的方法包括:
12、对于音频区间的音频的音频信号进行预处理;
13、对于预处理后的音频区间的音频的音频信号进行mfcc特征提取,把每一帧波形变成一个包含声音信息的多维向量,得到音频区间的音频中的特征向量;
14、声学模型将特征向量根据语音的声学特征分类,得到所述音频文件中的音频中的声音特征分类。
15、在本发明的一种实施例中的基于深度学习的语音转录方法,步骤s50的识别音频区间的音频对应的第二文本,包括
16、声学模型将所述声学特征分类对应到音素和/或字词单元;
17、通过语言模型将所得到的音素和/或字词单元解码成完整的句子,所述完整的句子是音频区间的音频对应的文本区间的第二文本。
18、在本发明的一种实施例中的基于深度学习的语音转录方法,所述预处理包括帧切割、对语音的高频部分进行预加重、增加语音的高频分辨率的操作中的任一种或者其组合。
19、本技术实施例还提供一种电子设备,所述电子设备包括:一个或多个处理器,存储器,以及,一个或多个程序;其中,所述一个或多个程序被存储在所述存储器中,所述一个或多个程序包括指令,当所述指令被所述电子设备执行时,使得所述电子设备执行本技术实施例第一方面任一可能设计的技术方案。
20、本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质包括计算机程序,当计算机程序在电子设备上运行时,使得所述电子设备执行本技术实施例第一方面任一可能设计的技术方案。
21、本发明的有益效果:
22、在第一方面上,本发明基于对人力以及时间的两点要求,提出能够对执法记录仪或监控器中的视频的对话内容进行提取的方法,并将对话的文本进行保存,从而减缓对人力的需求,并提高执法信息数据存储的速度。
23、在第二方面上,本发明为了能够识别视频中的文本,使用语音信号处理与识别实现对音频的提取和初步识别。本发明还为能够将音频中不同的说话人进行区分,使用声纹识别对不同的声音特征进行分类。
24、在第三方面上,本发明通过根据所述音频时间标记,将所述第二文本与所述第一文本匹配,对所述第二文本中各音频区间的音频对应的文本对应在所述第一文本的相应的文本位置,根据第二文本的所述文本区间标记对所述第一文本的对应文本的区间标记说话对象,所述标记文本区间的说话对象的第一文本是所述语音转录所得文件,其中,所述音频区间、文本区间是所述音频时间的时间区间的对应表示。从而将的不同说话人的第二文本与整体识别得到的第一文本进行匹配,一方面使得第一文本能够具有文本分区和说话人的对应标记,并将具有文本分区和说话人对应标记的第一文本作为最终转录文本。另一方面对因音频时间短等原因在分段识别的第二文本中无法识别的语音,借由整体识别的第一文本所弥补,避免了分段识别因音频时间短等原因具有部分无法识别语音的现象。
本文地址:https://www.jishuxx.com/zhuanli/20250110/353352.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表