基于数据驱动和稀疏序列化的综合热定位误差建模方法与流程
- 国知局
- 2025-01-10 13:35:29
本发明涉及机床热误差建模,更具体地,涉及一种基于数据驱动和稀疏序列化的综合热定位误差建模方法。
背景技术:
1、随着全闭环多轴驱动系统在高精度设备和精度控制领域中的广泛应用,传动系统的精准性和可靠性成为关注的焦点。在这一背景下,本发明对全闭环多轴驱动系统的综合热定位误差进行了全面的分析与建模,着重关注热漂移和热定位误差两大方面。在不同驱动方式的全闭环传动系统和主轴发热的综合影响下,热漂移和热定位误差之间的复杂相互作用成为研究的难点。
2、高精度机床通常利用冷却系统和光学光栅位置反馈来减轻传动系统在该领域产生的热定位误差。然而,精密机床的主轴会显著影响多轴系统中热定位误差的稳定性,针对该问题的研究尚未得到充分探索。综合热定位误差的复杂性主要是由于主轴的锁定也会产生热量,导致主轴热变形与传动系统的热定位误差交织和互相干扰,从而导致多轴传动系统产生严重热漂移。
3、因此,全闭环控制多轴传动系统中综合热定位误差的变化非常复杂。本发明首次深入研究了综合热定位误差的研究,创新性地将其分为热漂移问题和热定位误差问题,并分别进行了数据特性分析和建模预测研究。
技术实现思路
1、针对上述基于自然图像的显微镜自动对焦存在的技术问题,本发明提供了一种基于数据驱动和稀疏序列化的综合热定位误差建模方法,可以实现对综合热定位误差的准确预测。
2、作为本发明的第一个方面,提供一种基于数据驱动和稀疏序列化的综合热定位误差建模方法,包括如下步骤:
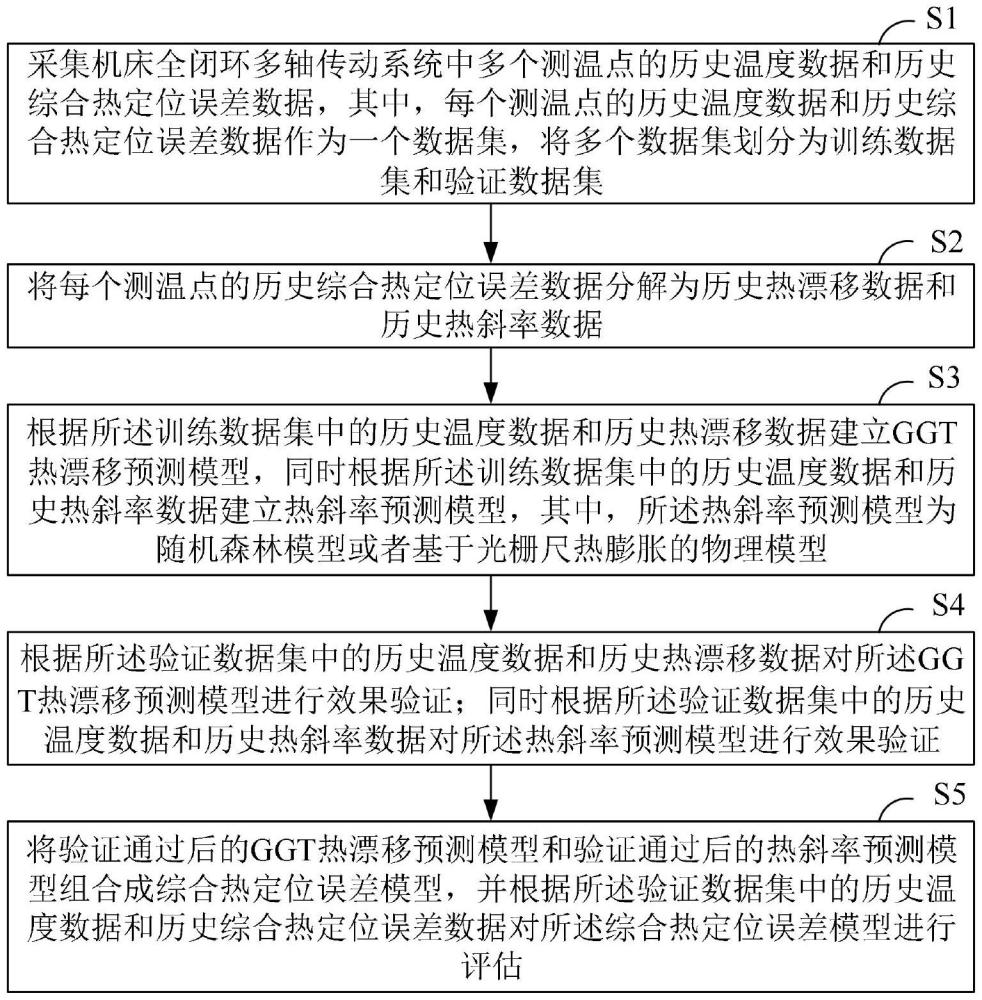
3、步骤s1:采集机床全闭环多轴传动系统中多个测温点的历史温度数据和历史综合热定位误差数据,其中,每个测温点的历史温度数据和历史综合热定位误差数据作为一个数据集,将多个数据集划分为训练数据集和验证数据集;
4、步骤s2:将每个测温点的历史综合热定位误差数据分解为历史热漂移数据和历史热斜率数据;
5、步骤s3:根据所述训练数据集中的历史温度数据和历史热漂移数据建立ggt热漂移预测模型,同时根据所述训练数据集中的历史温度数据和历史热斜率数据建立热斜率预测模型,其中,所述热斜率预测模型为随机森林模型或者基于光栅尺热膨胀的物理模型;
6、步骤s4:根据所述验证数据集中的历史温度数据和历史热漂移数据对所述ggt热漂移预测模型进行效果验证;同时根据所述验证数据集中的历史温度数据和历史热斜率数据对所述热斜率预测模型进行效果验证;
7、步骤s5:将验证通过后的ggt热漂移预测模型和验证通过后的热斜率预测模型组合成综合热定位误差模型,并根据所述验证数据集中的历史温度数据和历史综合热定位误差数据对所述综合热定位误差模型进行评估。
8、进一步地,所述步骤s1中,还包括:
9、对采集的多个历史温度数据进行增量化处理,以得到增量化的历史温度数据;
10、对所述增量化的历史温度数据进行稀疏序列化操作,以得到稀疏序列化的历史温度数据。
11、进一步地,所述对所述增量化的历史温度数据进行稀疏序列化操作,以得到稀疏序列化的历史温度数据,还包括:
12、确定历史温度数据的采样数量和采样步长;
13、根据历史综合热定位误差数据的时间戳确定所述历史温度数据的初始采样点位置;
14、根据采样步长和采样数量得到历史温度数据的所有采样点位置;
15、其中,如果采样点位置为空,则表示在零时刻之前,历史温度数据将完全填充为零;最终得到稀疏序列化的历史温度数据及其对应的历史综合热定位误差数据。
16、进一步地,所述ggt热漂移预测模型包含gcn模块、bi-gru模块、编码器模块、第一线性层、relu激活层、第二线性层和输出层,所述根据所述训练数据集中的历史温度数据和历史热漂移数据建立ggt热漂移预测模型,还包括:
17、步骤s311:构建gcn模块,所述gcn模块的核心公式如下:
18、z=relu(axw)
19、其中,z为输出,relu为一个非线性激活函数,a为变形邻接矩阵,x为输入的历史温度数据,w为权重矩阵;
20、步骤s312:构建bi-gru模块,所述bi-gru模块的核心公式如下:
21、
22、其中,xt为当前输入的历史温度数据;zt、rt、ht和分别代表当前更新门、当前复位门、当前候选隐藏状态和当前隐藏状态;ht—1代表上一个候选隐藏状态;w、u和b均为权重矩阵;φh和σg分别代表双曲正切和sigmod函数;⊙是hadamard积;
23、步骤s313:对所述gcn模块输出的特征信息和所述bi-gru模块输出的特征信息进行整合,随后,将整合后的特征信息依次经过所述编码器模块、第一线性层、relu激活层和第二线性层进行回归预测,最终通过所述输出层输出热漂移预测结果,其中,所述编码器模块中的多头注意力机制的公式如下:
24、
25、其中,q是查询;k是钥匙;v是值;softmax()是归一化指数函数,dk是向量维度。
26、进一步地,还包括:
27、将输入的历史温度数据分别经过gcn模块和bi-gru模块,以学习空间信息特征和时间信息特征;gcn模块和bi-gru模块分别输出一个一维特征向量,将两个一维特征向量拼接整合得到新的一维编码特征向量;
28、将新的一维编码特征向量依次经过所述编码器模块、第一线性层、relu激活层和第二线性层进行回归预测,最终通过所述输出层输出热漂移预测结果;
29、其中,所述编码器模块包括多头注意力机制、第一个残差连接层和归一化层、前馈神经网络层以及第二个残差连接层和归一化层。
30、进一步地,所述根据所述训练数据集中的历史温度数据和历史热斜率数据建立热斜率预测模型,其中,所述热斜率预测模型为随机森林模型或者基于光栅尺热膨胀的物理模型,还包括:
31、步骤s321:利用随机森林模型对热斜率进行回归预测;
32、步骤s322:利用贝叶斯推断的方法,对随机森林模型的超参数进行优化,以得到训练好的随机森林模型;
33、步骤s323:基于光栅尺热膨胀系数建立物理模型,所述物理模型的核心公式为:
34、
35、其中,yex表示历史热斜率数据,单位为μm/l;是光栅尺周围的平均温度;α是光栅尺的热膨胀系数,以12μm/℃/m表示;l是运动轴的行程长度,单位为m。
36、进一步地,所述随机森林模型是一种包含多个决策树的机器学习模型,将历史温度数据输入单个决策树获得一个热斜率预测值,多个决策树的热斜率预测值加权叠加形成随机森林模型,以获取更好的预测能力和模型鲁棒性;
37、其中,随机森林模型包含多个超参数,通过贝叶斯优化的方式对随机森林模型的多个超参数进行优化,以得到最优的超参数,即可得到训练好的随机森林模型;将历史温度数据输入到所述训练好的随机森林模型,即可得到最终的热斜率预测结果。
38、进一步地,所述根据所述验证数据集中的历史温度数据和历史综合热定位误差数据对所述综合热定位误差模型进行评估,还包括:
39、所述综合热定位误差模型的评估指标包括均方根误差rmse、平均绝对误差mae、校正决定系数r2adj和总绝对误差tae,其中,各个评估指标的公式如下:
40、
41、其中,
42、
43、其中,yi是观测值;是观测值yi的平均值;是预测值;n是样本数;p是特征的数量;r2是决定系数。
44、进一步地,所述采集机床全闭环多轴传动系统中多个测温点的历史温度数据和历史综合热定位误差数据,还包括:
45、通过fbg温度传感器采集机床全闭环多轴传动系统中多个测温点的历史温度数据;
46、通过激光干涉仪采集机床全闭环多轴传动系统中多个测温点的历史综合热定位误差数据;其中,对不同驱动方式的机床全闭环多轴传动系统在不同运动速度下进行综合热定位误差数据测量,其中z轴驱动方式为滚珠丝杠,x轴驱动方式为直线电机,全闭环方式为高精度光栅尺。
47、进一步地,所述历史温度数据的采集频率为1hz;每采集一次完整的历史综合热定位误差数据耗时为1min,间隔时间为10min,单次实验为180min。
48、本发明提供的一种基于数据驱动和稀疏序列化的综合热定位误差建模方法具有以下有益效果:
49、(1)提出一种新颖的稀疏时间序列方法,用于有效的热误差分析,并且使数据稀疏序列化而不丢失时间信息。
50、(2)热漂移对综合热定位误差有显著影响。针对温度数据的时空特征,本发明提出了ggt深度学习模型,有效地预测热漂移变化。实验结果表明,在所提模型中,用gru和gcn模块替换transformer数据编码是有效的;
51、(3)光栅尺抑制并简化了热定位误差。直接建立的基于热膨胀系数的thermal_ex模型可以简单有效地预测热定位误差,而bayes-rf模型则进一步提高了热定位误差的预测精度;
52、(4)提出的ggt热漂移模型和bayes-rf热定位误差模型显着提高了综合热定位误差的预测精度。
本文地址:https://www.jishuxx.com/zhuanli/20250110/354075.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表