基于深度学习的双图代码查重方法及其系统
- 国知局
- 2025-01-17 13:06:05
本发明涉及代码查重技术,具体涉及一种基于深度学习的双图代码查重方法及其系统。
背景技术:
1、代码查重,也称为代码克隆检测或代码抄袭检测,是一种用于识别和比较源代码文件中相似或相同代码片段的过程。它的目的是确保代码的原创性,防止非法复制或滥用代码,以及维护软件开发中的知识产权。随着计算机编程在教育、工业和研究领域的广泛应用,代码查重技术成为了确保代码原创性和维护知识产权的重要工具。代码查重技术的发展与计算机编程教育的普及密切相关。在学术环境中,教师需要确保学生提交的代码作业是原创的,而在工业界,企业需要保护其软件产品的代码不被非法复制或滥用。此外,随着开源运动的兴起,代码查重也成为了维护开源社区健康和促进代码共享的重要手段。
2、代码查重工具通常采用多种技术和算法来识别相似或重复的代码片段,包括文本比对,通过直接比较代码文本的相似性;抽象语法树(ast)分析,基于代码的结构和语法进行比较;程序依赖图(pdg),分析代码的控制流和数据流以识别逻辑结构;以及机器学习,利用深度学习等技术识别代码模式和结构,从而发现更深层次的相似性。
3、在代码查重领域,尽管已有多种技术被用来识别源代码中的相似或重复片段,但这些技术仍然存在一些显著的局限性。传统的代码查重系统常常难以捕捉代码的复杂结构差异和执行顺序的微小变化,例如代码片段的简单重新排列,就可能使这些系统无法正确识别抄袭。基于文本相似度的算法,尽管操作简单直接,但它们对代码的格式和注释非常敏感,容易受到表面文本改动的影响,从而降低了查重的效果。这类算法往往忽视了代码背后的执行逻辑信息,限制了它们识别结构相似但文本不同的代码片段的能力。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的基于深度学习的双图代码查重方法及其系统解决了现有技术难以准确识别代码结构上的细微差异,致使查重准确度不高的问题。
2、为了达到上述发明目的,本发明采用的技术方案为:
3、第一方面,提供一种基于深度学习的双图代码查重方法,其包括步骤:
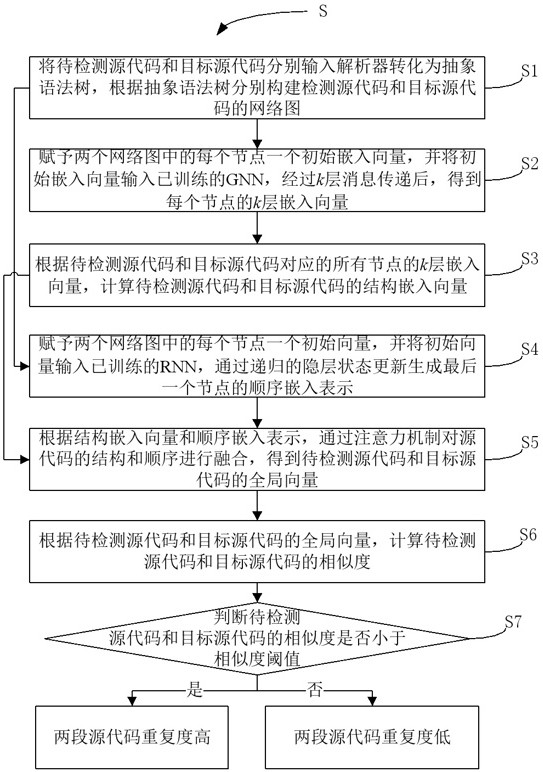
4、s1、将待检测源代码和目标源代码分别输入解析器转化为抽象语法树,根据抽象语法树分别构建检测源代码和目标源代码的网络图;
5、s2、赋予两个网络图中的每个节点一个初始嵌入向量,并将初始嵌入向量输入已训练的gnn,经过k层消息传递后,得到每个节点的k层嵌入向量;
6、s3、根据待检测源代码和目标源代码对应的所有节点的k层嵌入向量,计算待检测源代码和目标源代码的结构嵌入向量;
7、s4、赋予两个网络图中的每个节点一个初始向量,并将初始向量输入已训练的rnn,通过递归的隐层状态更新生成最后一个节点的顺序嵌入表示;
8、s5、根据结构嵌入向量和顺序嵌入表示,通过注意力机制对源代码的结构和顺序进行融合,得到待检测源代码和目标源代码的全局向量;
9、s6、根据待检测源代码和目标源代码的全局向量,计算待检测源代码和目标源代码的相似度;
10、s7、判断待检测源代码和目标源代码的相似度是否小于相似度阈值,若是,则两段源代码重复度高,否则两段源代码重复度低。
11、进一步地,相似度阈值的计算方法包括:
12、s71、选取待检测源代码或目标源代码作为锚点,计算锚点与代码数据库中的所有源代码的相似度,并进行降序排序;
13、s72、选取排名靠前预设数量的相似度对应的源代码作为锚点的正样本,选取排名靠后预设数量的相似度对应的源代码作为锚点的负样本;
14、s73、将锚点、正样本和负样本输入神经网络进行训练,并采用三元组损失函数bpr作为神经网络的损失函数,训练完成后,输出相似度阈值。
15、进一步地,三元组损失函数bpr的表达式为:
16、
17、其中,为损失值;为锚点与正样本之间的相似度;为锚点与负样本之间的相似度;dθ为相似度阈值;σ为激活函数,用于将输入的值映射到0到1之间的数值;λ为超参数;为锚点的全局向量;为l2范数的平方。
18、进一步地,步骤s5进一步包括:
19、s51、根据结构嵌入向量和顺序嵌入表示,通过注意力机制得到待检测源代码和目标源代码权衡结构信息和顺序信息的结构权重和顺序权重:
20、
21、
22、其中,和分别为源代码m的结构权重和顺序权重,m=i和j,当m=i时,表示待检测源代码,m=j时,表示目标源代码;为待学习的权重矩阵;为拼接操作;为偏置项;为softmax激活函数;和分别为源代码m对应的结构嵌入向量和顺序嵌入表示;
23、s52、根据结构嵌入向量和顺序嵌入表示及结构权重和顺序权重,对结构和顺序信息进行加权,融合得到待检测源代码和目标源代码的全局向量:
24、
25、其中,为全局向量。
26、进一步地,计算待检测源代码和目标源代码的相似度的表达式为:
27、
28、其中,为待检测源代码和目标源代码的相似度;为待检测源代码的全局向量;为目标源代码的全局向量;为l2范数。
29、进一步地,节点的k层嵌入向量的表达式为:
30、
31、其中,为源代码m的节点q通过第k层传递得到的k层嵌入向量;m=i和j,当m=i时,表示待检测源代码,m=j时,表示目标源代码;为源代码m的节点q通过第k-1传递得到的k-1层嵌入向量;为与源代码m的节点q直接连接的节点p通过第k-1层传递得到的k-1层嵌入向量;dq,m为源代码m的节点q的度;dp,m为源代码m的节点p的度;vp为与源代码m的节点q直接连接的节点集合;
32、结构嵌入向量的表达式为:
33、
34、其中,t为源代码m包括的节点总数量;为源代码m的结构嵌入向量。
35、进一步地,步骤s4进一步包括:
36、赋予网络图中的每个节点一个初始向量:
37、
38、其中,xm为源代码m的所有节点的初始向量集合;m=i和j,当m=i时,表示待检测源代码,m=j时,表示目标源代码;、和分别为源代码m的第1个、第2个和第t个节点的初始向量;
39、将初始向量集合中的每个初始向量按顺序输入已训练的rnn,通过递归的隐层状态更新生成最后一个节点的顺序嵌入表示ht;
40、每个节点的顺序嵌入表示的表达式为:
41、
42、其中,为源代码m的第t个节点的顺序嵌入表示,1≤t≤t;为源代码m的第t个节点的初始向量;为源代码m的第t-1个节点的顺序嵌入表示;wh和wx分别为rnn对隐层状态和输入的权重矩阵;b为rnn的偏置项;relu为激活函数。
43、进一步地,检测源代码和目标源代码的网络图的构建方法为:提取抽象语法树中的函数、类和控制结构作为节点,节点之间的调用关系作为边,得到检测源代码和目标源代码对应的网络图。
44、进一步地,所述神经网络为卷积神经网络,步骤s73中对神经网络进行训练时,设定最大训练轮数为150轮,每一轮训练中通过反向传播更新参数,当连续10轮训练的损失值ζ的变化量低于预设值时,则停止神经网络的训练。
45、第二方面,提供一种应用于基于深度学习的双图代码查重方法的系统,其包括:
46、网络图构建模块,用于将待检测源代码和目标源代码分别输入解析器转化为抽象语法树,根据抽象语法树分别构建检测源代码和目标源代码的网络图;
47、嵌入向量生成模块,用于赋予两个网络图中的每个节点一个初始嵌入向量,并将初始嵌入向量输入已训练的gnn,经过k层消息传递后,得到每个节点的k层嵌入向量;
48、结构嵌入向量生成模块,用于根据待检测源代码和目标源代码对应的所有节点的k层嵌入向量,计算待检测源代码和目标源代码的结构嵌入向量;
49、顺序嵌入表示生成模块,用于赋予两个网络图中的每个节点一个初始向量,并将初始向量输入已训练的rnn,通过递归的隐层状态更新生成最后一个节点的顺序嵌入表示;
50、全局向量生成模块,用于根据结构嵌入向量和顺序嵌入表示,通过注意力机制对源代码的结构和顺序进行融合,得到待检测源代码和目标源代码的全局向量;
51、相似度计算模块,用于根据待检测源代码和目标源代码的全局向量,计算待检测源代码和目标源代码的相似度;
52、重复度判断模块,用于判断待检测源代码和目标源代码的相似度是否小于相似度阈值,若是,则两段源代码重复度高,否则两段源代码重复度低。
53、与现有技术相比,本发明的有益效果为:
54、1、提升抄袭模式识别的全面性:现有查重系统通常只能捕捉代码的表层相似性或简单的顺序特征,难以应对结构复杂或依赖关系不明显的代码片段。本方案通过引入图神经网络(gnn)和递归神经网络(rnn),即双图,分别提取代码中的结构和顺序特征,生成多层次的代码表示。gnn能够捕捉代码中节点之间的依赖关系、控制流、调用关系等复杂结构信息,而rnn能够保留代码的执行顺序和逻辑上下文。通过这种多角度的嵌入表示,能够更全面地识别复杂的抄袭模式,避免单一特征提取的局限性。这实现了对复杂抄袭模式的有效捕捉,提高了对隐性抄袭和重构抄袭的识别能力。
55、2、通过注意力机制实现特征的自适应融合:本方案在gnn和rnn的嵌入融合过程中引入了注意力机制,以自适应的方式分配结构特征和顺序特征的权重。相比于传统的直接拼接或简单加权方式,注意力机制能够根据输入代码的特征动态调整融合权重,确保在面对不同代码片段时对关键特征的关注度得到优化。这使得特征融合更加灵活精准,有助于在不同特征权重需求下优化模型表现,从而提高查重结果的准确性和鲁棒性。
56、3、基于三元组损失的对比学习优化抄袭判别:本方案通过三元组损失(tripletloss)进行模型优化,选取“锚点-正样本-负样本”三元组进行嵌入学习,使模型学会判别相似和非相似代码片段。相比于传统的分类或距离度量方法,三元组损失能够自动缩小抄袭代码的嵌入距离,同时拉大非抄袭代码的嵌入距离,实现了精细的相似度判断。此外,在训练过程中会根据三元组距离分布更新相似度阈值,以进一步提高抄袭判定的可靠性。这使得模型通过不断优化相似度分布,能够自适应地提升嵌入向量的区分度,使得抄袭检测结果更加精准,有效降低误判率。
57、4、动态的相似度阈值提高抄袭检测的灵活性:在实际抄袭判定时,本方案利用三元组损失的优化过程设置动态相似度阈值。随着模型嵌入向量的优化,阈值会根据训练数据自动调整,确保不同特征分布的代码都能适应最优阈值。这种方法较传统的固定阈值更加灵活,能够适应不同代码集的数据分布特征,提升模型在多样化代码上的查重效果。自适应的动态阈值设置使得本方案在处理不同数据集或不同代码风格时能保证较高的检测准确度和灵活性。
本文地址:https://www.jishuxx.com/zhuanli/20250117/356156.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表